

Update README.md
Browse files
README.md
CHANGED
|
@@ -39,6 +39,11 @@ Model (EN/FR)
|
|
| 39 |
| [Bloomz-560m-retriever](https://huggingface.co/cmarkea/bloomz-560m-retriever) | 10 | 44 | 49 | 77 | 86 |
|
| 40 |
| [Bloomz-3b-retriever](https://huggingface.co/cmarkea/bloomz-3b-retriever) | 9 | 38 | 50 | 78 | 87 |
|
| 41 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
|
| 43 |
How to Use Blommz-3b-retriever
|
| 44 |
--------------------------------
|
|
|
|
| 39 |
| [Bloomz-560m-retriever](https://huggingface.co/cmarkea/bloomz-560m-retriever) | 10 | 44 | 49 | 77 | 86 |
|
| 40 |
| [Bloomz-3b-retriever](https://huggingface.co/cmarkea/bloomz-3b-retriever) | 9 | 38 | 50 | 78 | 87 |
|
| 41 |
|
| 42 |
+
We observed that TF-IDF loses robustness in cross-language scenarios (even showing lower performance than CamemBERT, which is a model specialized in French). This can be explained by the fact that a Bag-Of-Words method cannot support this type of issue because, for a given sentence between two languages, the embedding vectors will be significantly different.
|
| 43 |
+
|
| 44 |
+
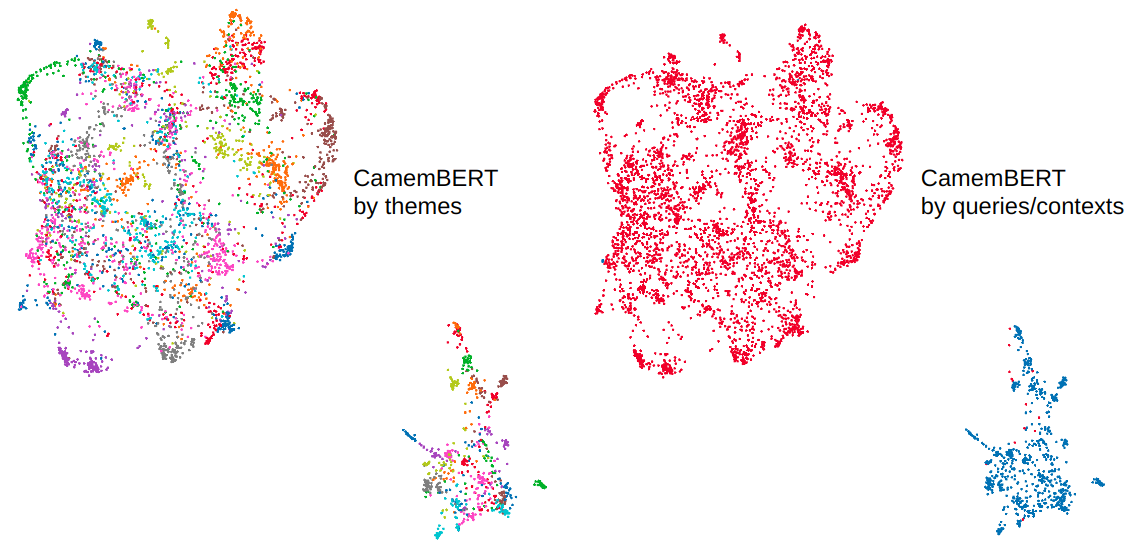
CamemBERT exhibits poor performance, not because it poorly groups contexts and queries by themes, but because a meta-cluster appears, separating contexts and queries (as illustrated in the image below), making this type of modeling inappropriate in a retriever context.
|
| 45 |
+
|
| 46 |
+
|
| 47 |
|
| 48 |
How to Use Blommz-3b-retriever
|
| 49 |
--------------------------------
|