
End of training
Browse files- README.md +4 -1
- all_results.json +12 -0
- eval_results.json +7 -0
- train_results.json +8 -0
- trainer_state.json +142 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -3,6 +3,7 @@ license: apache-2.0
|
|
| 3 |
library_name: peft
|
| 4 |
tags:
|
| 5 |
- llama-factory
|
|
|
|
| 6 |
- generated_from_trainer
|
| 7 |
base_model: tiiuae/falcon-7b-instruct
|
| 8 |
model-index:
|
|
@@ -15,7 +16,9 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# Falcon-7B-Instruct-ORPO-SFT
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) on
|
|
|
|
|
|
|
| 19 |
|
| 20 |
## Model description
|
| 21 |
|
|
|
|
| 3 |
library_name: peft
|
| 4 |
tags:
|
| 5 |
- llama-factory
|
| 6 |
+
- lora
|
| 7 |
- generated_from_trainer
|
| 8 |
base_model: tiiuae/falcon-7b-instruct
|
| 9 |
model-index:
|
|
|
|
| 16 |
|
| 17 |
# Falcon-7B-Instruct-ORPO-SFT
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) on the bct_non_cot_sft_1000 dataset.
|
| 20 |
+
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.1655
|
| 22 |
|
| 23 |
## Model description
|
| 24 |
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.986666666666667,
|
| 3 |
+
"eval_loss": 0.16554969549179077,
|
| 4 |
+
"eval_runtime": 2.7017,
|
| 5 |
+
"eval_samples_per_second": 37.014,
|
| 6 |
+
"eval_steps_per_second": 18.507,
|
| 7 |
+
"total_flos": 1.3957687162699776e+16,
|
| 8 |
+
"train_loss": 0.30872942223435357,
|
| 9 |
+
"train_runtime": 264.2672,
|
| 10 |
+
"train_samples_per_second": 10.217,
|
| 11 |
+
"train_steps_per_second": 0.636
|
| 12 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.986666666666667,
|
| 3 |
+
"eval_loss": 0.16554969549179077,
|
| 4 |
+
"eval_runtime": 2.7017,
|
| 5 |
+
"eval_samples_per_second": 37.014,
|
| 6 |
+
"eval_steps_per_second": 18.507
|
| 7 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.986666666666667,
|
| 3 |
+
"total_flos": 1.3957687162699776e+16,
|
| 4 |
+
"train_loss": 0.30872942223435357,
|
| 5 |
+
"train_runtime": 264.2672,
|
| 6 |
+
"train_samples_per_second": 10.217,
|
| 7 |
+
"train_steps_per_second": 0.636
|
| 8 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
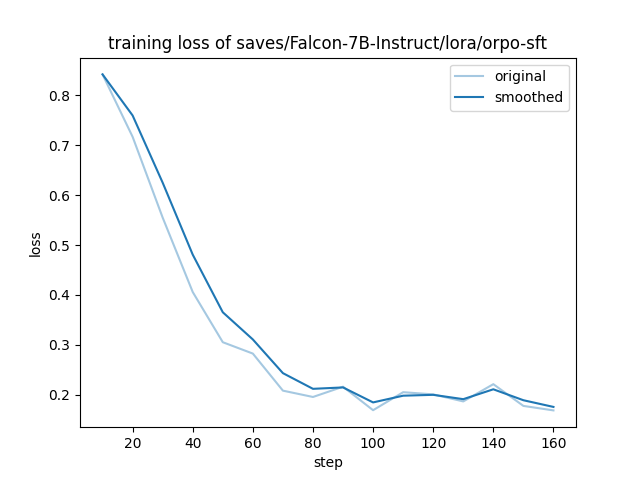
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.986666666666667,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 168,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.17777777777777778,
|
| 13 |
+
"grad_norm": 4.22963809967041,
|
| 14 |
+
"learning_rate": 4.957230266673969e-06,
|
| 15 |
+
"loss": 0.8422,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.35555555555555557,
|
| 20 |
+
"grad_norm": 3.0976099967956543,
|
| 21 |
+
"learning_rate": 4.828686741593921e-06,
|
| 22 |
+
"loss": 0.7171,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.5333333333333333,
|
| 27 |
+
"grad_norm": 3.412571430206299,
|
| 28 |
+
"learning_rate": 4.618852307232078e-06,
|
| 29 |
+
"loss": 0.5551,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.7111111111111111,
|
| 34 |
+
"grad_norm": 3.297762393951416,
|
| 35 |
+
"learning_rate": 4.335051964269395e-06,
|
| 36 |
+
"loss": 0.4059,
|
| 37 |
+
"step": 40
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"epoch": 0.8888888888888888,
|
| 41 |
+
"grad_norm": 2.6004385948181152,
|
| 42 |
+
"learning_rate": 3.987192750660719e-06,
|
| 43 |
+
"loss": 0.3053,
|
| 44 |
+
"step": 50
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 1.0666666666666667,
|
| 48 |
+
"grad_norm": 1.9239391088485718,
|
| 49 |
+
"learning_rate": 3.587417902020876e-06,
|
| 50 |
+
"loss": 0.2825,
|
| 51 |
+
"step": 60
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"epoch": 1.2444444444444445,
|
| 55 |
+
"grad_norm": 1.2859814167022705,
|
| 56 |
+
"learning_rate": 3.1496829497545268e-06,
|
| 57 |
+
"loss": 0.2082,
|
| 58 |
+
"step": 70
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"epoch": 1.4222222222222223,
|
| 62 |
+
"grad_norm": 1.2387938499450684,
|
| 63 |
+
"learning_rate": 2.6892685546987724e-06,
|
| 64 |
+
"loss": 0.1955,
|
| 65 |
+
"step": 80
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"epoch": 1.6,
|
| 69 |
+
"grad_norm": 2.38809871673584,
|
| 70 |
+
"learning_rate": 2.2222470825144806e-06,
|
| 71 |
+
"loss": 0.2161,
|
| 72 |
+
"step": 90
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"epoch": 1.7777777777777777,
|
| 76 |
+
"grad_norm": 1.2159907817840576,
|
| 77 |
+
"learning_rate": 1.7649215418673847e-06,
|
| 78 |
+
"loss": 0.169,
|
| 79 |
+
"step": 100
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"epoch": 1.9555555555555557,
|
| 83 |
+
"grad_norm": 1.050315499305725,
|
| 84 |
+
"learning_rate": 1.3332564712129845e-06,
|
| 85 |
+
"loss": 0.2051,
|
| 86 |
+
"step": 110
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"epoch": 2.1333333333333333,
|
| 90 |
+
"grad_norm": 2.968810796737671,
|
| 91 |
+
"learning_rate": 9.423206410612498e-07,
|
| 92 |
+
"loss": 0.2007,
|
| 93 |
+
"step": 120
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"epoch": 2.311111111111111,
|
| 97 |
+
"grad_norm": 2.0824708938598633,
|
| 98 |
+
"learning_rate": 6.057610261367044e-07,
|
| 99 |
+
"loss": 0.1866,
|
| 100 |
+
"step": 130
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"epoch": 2.488888888888889,
|
| 104 |
+
"grad_norm": 1.7900301218032837,
|
| 105 |
+
"learning_rate": 3.3532641026504415e-07,
|
| 106 |
+
"loss": 0.2212,
|
| 107 |
+
"step": 140
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"epoch": 2.6666666666666665,
|
| 111 |
+
"grad_norm": 1.0882800817489624,
|
| 112 |
+
"learning_rate": 1.4045725421448332e-07,
|
| 113 |
+
"loss": 0.1776,
|
| 114 |
+
"step": 150
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"epoch": 2.8444444444444446,
|
| 118 |
+
"grad_norm": 1.0603089332580566,
|
| 119 |
+
"learning_rate": 2.7956143581177874e-08,
|
| 120 |
+
"loss": 0.1686,
|
| 121 |
+
"step": 160
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"epoch": 2.986666666666667,
|
| 125 |
+
"step": 168,
|
| 126 |
+
"total_flos": 1.3957687162699776e+16,
|
| 127 |
+
"train_loss": 0.30872942223435357,
|
| 128 |
+
"train_runtime": 264.2672,
|
| 129 |
+
"train_samples_per_second": 10.217,
|
| 130 |
+
"train_steps_per_second": 0.636
|
| 131 |
+
}
|
| 132 |
+
],
|
| 133 |
+
"logging_steps": 10,
|
| 134 |
+
"max_steps": 168,
|
| 135 |
+
"num_input_tokens_seen": 0,
|
| 136 |
+
"num_train_epochs": 3,
|
| 137 |
+
"save_steps": 500,
|
| 138 |
+
"total_flos": 1.3957687162699776e+16,
|
| 139 |
+
"train_batch_size": 2,
|
| 140 |
+
"trial_name": null,
|
| 141 |
+
"trial_params": null
|
| 142 |
+
}
|
training_loss.png
ADDED
|