Leveraging Pre-trained Language Model Checkpoints for Encoder-Decoder Models







Transformer-based encoder-decoder models were proposed in Vaswani et al. (2017) and have recently experienced a surge of interest, e.g. Lewis et al. (2019), Raffel et al. (2019), Zhang et al. (2020), Zaheer et al. (2020), Yan et al. (2020).
Similar to BERT and GPT2, massive pre-trained encoder-decoder models have shown to significantly boost performance on a variety of sequence-to-sequence tasks Lewis et al. (2019), Raffel et al. (2019). However, due to the enormous computational cost attached to pre-training encoder-decoder models, the development of such models is mainly limited to large companies and institutes.
In Leveraging Pre-trained Checkpoints for Sequence Generation Tasks (2020), Sascha Rothe, Shashi Narayan and Aliaksei Severyn initialize encoder-decoder model with pre-trained encoder and/or decoder-only checkpoints (e.g. BERT, GPT2) to skip the costly pre-training. The authors show that such warm-started encoder-decoder models yield competitive results to large pre-trained encoder-decoder models, such as T5, and Pegasus on multiple sequence-to-sequence tasks at a fraction of the training cost.
In this notebook, we will explain in detail how encoder-decoder models can be warm-started, give practical tips based on Rothe et al. (2020), and finally go over a complete code example showing how to warm-start encoder-decoder models with 🤗Transformers.
This notebook is divided into 4 parts:
- Introduction - Short summary of pre-trained language models in NLP and the need for warm-starting encoder-decoder models.
- Warm-starting encoder-decoder models (Theory) - Illustrative explanation on how encoder-decoder models are warm-started?
- Warm-starting encoder-decoder models (Analysis) - Summary of Leveraging Pre-trained Checkpoints for Sequence Generation Tasks (2020) - What model combinations are effective to warm-start encoder-decoder models; How does it differ from task to task?
- Warm-starting encoder-decoder models with 🤗Transformers
(Practice) - Complete code example showcasing in-detail how to
use the
EncoderDecoderModelframework to warm-start transformer-based encoder-decoder models.
It is highly recommended (probably even necessary) to have read this blog post about transformer-based encoder-decoder models.
Let's start by giving some back-ground on warm-starting encoder-decoder models.
Introduction
Recently, pre-trained language models have revolutionized the field of natural language processing (NLP).
The first pre-trained language models were based on recurrent neural networks (RNN) as proposed Dai et al. (2015). Dai et. al showed that pre-training an RNN-based model on unlabelled data and subsequently fine-tuning it on a specific task yields better results than training a randomly initialized model directly on such a task. However, it was only in 2018, when pre-trained language models become widely accepted in NLP. ELMO by Peters et al. and ULMFit by Howard et al. were the first pre-trained language model to significantly improve the state-of-the-art on an array of natural language understanding (NLU) tasks. Just a couple of months later, OpenAI and Google published transformer-based pre-trained language models, called GPT by Radford et al. and BERT by Devlin et al. respectively. The improved efficiency of transformer-based language models over RNNs allowed GPT2 and BERT to be pre-trained on massive amounts of unlabeled text data. Once pre-trained, BERT and GPT were shown to require very little fine-tuning to shatter state-of-art results on more than a dozen NLU tasks .
The capability of pre-trained language models to effectively transfer task-agnostic knowledge to task-specific knowledge turned out to be a great catalyst for NLU. Whereas engineers and researchers previously had to train a language model from scratch, now publicly available checkpoints of large pre-trained language models can be fine-tuned at a fraction of the cost and time. This can save millions in industry and allows for faster prototyping and better benchmarks in research.
Pre-trained language models have established a new level of performance on NLU tasks and more and more research has been built upon leveraging such pre-trained language models for improved NLU systems. However, standalone BERT and GPT models have been less successful for sequence-to-sequence tasks, e.g. text-summarization, machine translation, sentence-rephrasing, etc.
Sequence-to-sequence tasks are defined as a mapping from an input sequence to an output sequence of a-priori unknown output length . Hence, a sequence-to-sequence model should define the conditional probability distribution of the output sequence conditioned on the input sequence :
Without loss of generality, an input word sequence of words is hereby represented by the vector sequnece and an output sequence of words as .
Let's see how BERT and GPT2 would be fit to model sequence-to-sequence tasks.
BERT
BERT is an encoder-only model, which maps an input sequence to a contextualized encoded sequence :
BERT's contextualized encoded sequence can then further be processed by a classification layer for NLU classification tasks, such as sentiment analysis, natural language inference, etc. To do so, the classification layer, i.e. typically a pooling layer followed by a feed-forward layer, is added as a final layer on top of BERT to map the contextualized encoded sequence to a class :
It has been shown that adding a pooling- and classification layer, defined as , on top of a pre-trained BERT model and subsequently fine-tuning the complete model can yield state-of-the-art performances on a variety of NLU tasks, cf. to BERT by Devlin et al..
Let's visualize BERT.
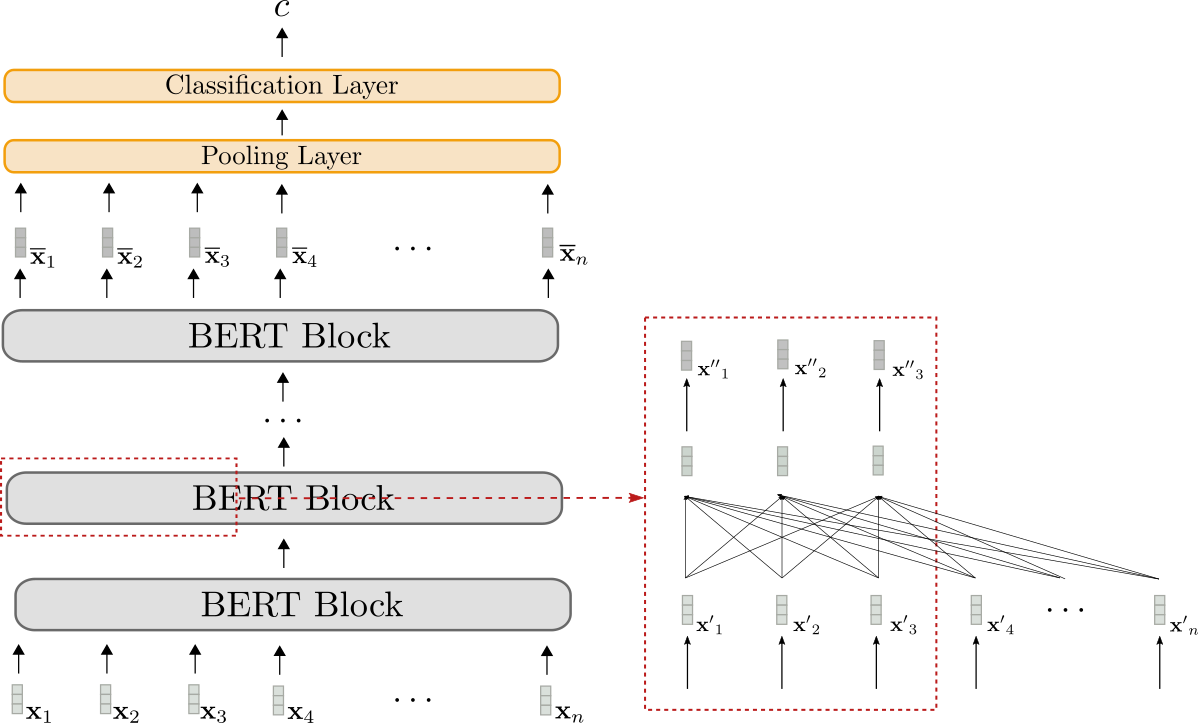
The BERT model is shown in grey. The model stacks multiple BERT blocks, each of which is composed of bi-directional self-attention layers (shown in the lower part of the red box) and two feed-forward layers (short in the upper part of the red box).
Each BERT block makes use of bi-directional self-attention to process an input sequence (shown in light grey) to a more "refined" contextualized output sequence (shown in slightly darker grey) . The contextualized output sequence of the final BERT block, i.e. , can then be mapped to a single output class by adding a task-specific classification layer (shown in orange) as explained above.
Encoder-only models can only map an input sequence to an output sequence of a priori known output length. In conclusion, the output dimension does not depend on the input sequence, which makes it disadvantageous and impractical to use encoder-only models for sequence-to-sequence tasks.
As for all encoder-only models, BERT's architecture corresponds exactly to the architecture of the encoder part of transformer-based encoder-decoder models as shown in the "Encoder" section in the Encoder-Decoder notebook.
GPT2
GPT2 is a decoder-only model, which makes use of uni-directional (i.e. "causal") self-attention to define a mapping from an input sequence to a "next-word" logit vector sequence :
By processing the logit vectors with the softmax operation, the model can define the probability distribution of the word sequence . To be exact, the probability distribution of the word sequence can be factorized into conditional "next word" distributions:
hereby presents the probability distribution of the next word given all previous words and is defined as the softmax operation applied on the logit vector . To summarize, the following equations hold true.
For more detail, please refer to the decoder section of the encoder-decoder blog post.
Let's visualize GPT2 now as well.
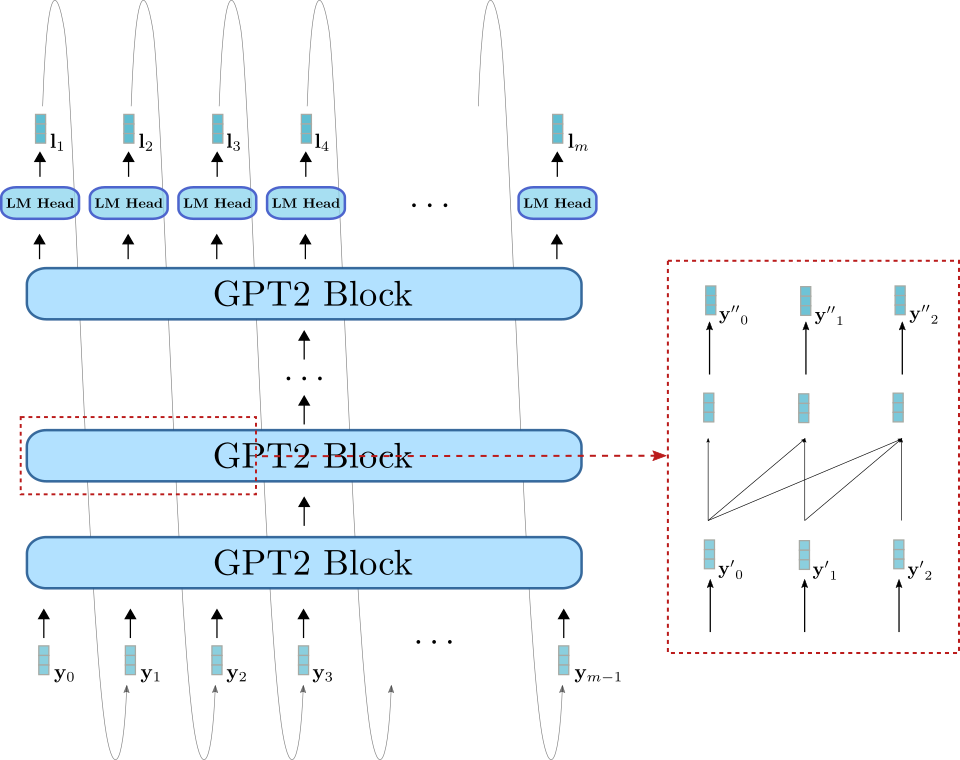
Analogous to BERT, GPT2 is composed of a stack of GPT2 blocks. In contrast to BERT block, GPT2 block makes use of uni-directional self-attention to process some input vectors (shown in light blue on the bottom right) to an output vector sequence (shown in darker blue on the top right). In addition to the GPT2 block stack, the model also has a linear layer, called LM Head, which maps the output vectors of the final GPT2 block to the logit vectors . As mentioned earlier, a logit vector can then be used to sample of new input vector .
GPT2 is mainly used for open-domain text generation. First, an input prompt is fed to the model to yield the conditional distribution . Then the next word is sampled from the distribution (represented by the grey arrows in the graph above) and consequently append to the input. In an auto-regressive fashion the word can then be sampled from and so on.
GPT2 is therefore well-suited for language generation, but less so for conditional generation. By setting the input prompt equal to the sequence input , GPT2 can very well be used for conditional generation. However, the model architecture has a fundamental drawback compared to the encoder-decoder architecture as explained in Raffel et al. (2019) on page 17. In short, uni-directional self-attention forces the model's representation of the sequence input to be unnecessarily limited since cannot depend on .
Encoder-Decoder
Because encoder-only models require to know the output length a priori, they seem unfit for sequence-to-sequence tasks. Decoder-only models can function well for sequence-to-sequence tasks, but also have certain architectural limitations as explained above.
The current predominant approach to tackle sequence-to-sequence tasks are transformer-based encoder-decoder models - often also called seq2seq transformer models. Encoder-decoder models were introduced in Vaswani et al. (2017) and since then have been shown to perform better on sequence-to-sequence tasks than stand-alone language models (i.e. decoder-only models), e.g. Raffel et al. (2020). In essence, an encoder-decoder model is the combination of a stand-alone encoder, such as BERT, and a stand-alone decoder model, such as GPT2. For more details on the exact architecture of transformer-based encoder-decoder models, please refer to this blog post.
Now, we know that freely available checkpoints of large pre-trained stand-alone encoder and decoder models, such as BERT and GPT, can boost performance and reduce training cost for many NLU tasks, We also know that encoder-decoder models are essentially the combination of stand-alone encoder and decoder models. This naturally brings up the question of how one can leverage stand-alone model checkpoints for encoder-decoder models and which model combinations are most performant on certain sequence-to-sequence tasks.
In 2020, Sascha Rothe, Shashi Narayan, and Aliaksei Severyn investigated exactly this question in their paper Leveraging Pre-trained Checkpoints for Sequence Generation Tasks. The paper offers a great analysis of different encoder-decoder model combinations and fine-tuning techniques, which we will study in more detail later.
Composing an encoder-decoder model of pre-trained stand-alone model checkpoints is defined as warm-starting the encoder-decoder model. The following sections show how warm-starting an encoder-decoder model works in theory, how one can put the theory into practice with 🤗Transformers, and also gives practical tips for better performance.
A pre-trained language model is defined as a neural network:
- that has been trained on unlabeled text data, i.e. in a task-agnostic, unsupervised fashion, and
- that processes a sequence of input words into a context-dependent embedding. E.g. the continuous bag-of-words and skip-gram model from Mikolov et al. (2013) is not considered a pre-trained language model because the embeddings are context-agnostic.
Fine-tuning is defined as the task-specific training of a model that has been initialized with the weights of a pre-trained language model.
The input vector corresponds hereby to the embedding vector required to predict the very first output word .
Without loss of generalitiy, we exclude the normalization layers to not clutter the equations and illustrations.
For more detail on why uni-directional self-attention is used for "decoder-only" models, such as GPT2, and how sampling works exactly, please refer to the decoder section of the encoder-decoder blog post.
Warm-starting encoder-decoder models (Theory)
Having read the introduction, we are now familiar with encoder-only- and decoder-only models. We have noticed that the encoder-decoder model architecture is essentially a composition of a stand-alone encoder model and a stand-alone decoder model, which led us to the question of how one can warm-start encoder-decoder models from stand-alone model checkpoints.
There are multiple possibilities to warm-start an encoder-decoder model. One can
- initialize both the encoder and decoder part from an encoder-only model checkpoint, e.g. BERT,
- initialize the encoder part from an encoder-only model checkpoint, e.g. BERT, and the decoder part from and a decoder-only checkpoint, e.g. GPT2,
- initialize only the encoder part with an encoder-only model checkpoint, or
- initialize only the decoder part with a decoder-only model checkpoint.
In the following, we will put the focus on possibilities 1. and 2. Possibilities 3. and 4. are trivial after having understood the first two.
Recap Encoder-Decoder Model
First, let's do a quick recap of the encoder-decoder architecture.
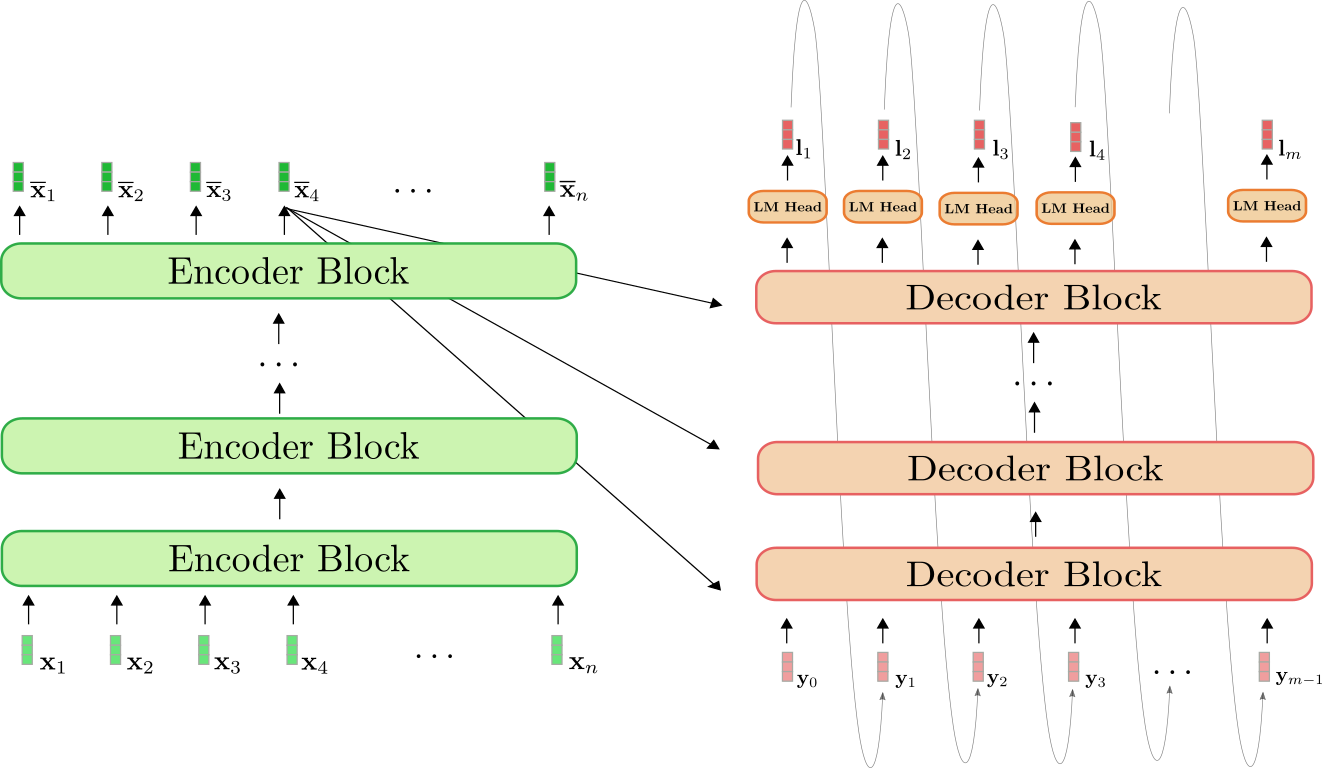
The encoder (shown in green) is a stack of encoder blocks. Each encoder block is composed of a bi-directional self-attention layer, and two feed-forward layers . The decoder (shown in orange) is a stack of decoder blocks, followed by a dense layer, called LM Head. Each decoder block is composed of a uni-directional self-attention layer, a cross-attention layer, and two feed-forward layers.
The encoder maps the input sequence to a contextualized encoded sequence in the exact same way BERT does. The decoder then maps the contextualized encoded sequence and a target sequence to the logit vectors . Analogous to GPT2, the logits are then used to define the distribution of the target sequence conditioned on the input sequence by means of a softmax operation.
To put it into mathematical terms, first, the conditional distribution is factorized into conditional distributions of the next word by Bayes' rule.
Each "next-word" conditional distributions is thereby defined by the softmax of the logit vector as follows.
For more detail, please refer to the Encoder-Decoder notebook.
Warm-staring Encoder-Decoder with BERT
Let's now illustrate how a pre-trained BERT model can be used to warm-start the encoder-decoder model. BERT's pre-trained weight parameters are used to both initialize the encoder's weight parameters as well as the decoder's weight parameters. To do so, BERT's architecture is compared to the encoder's architecture and all layers of the encoder that also exist in BERT will be initialized with the pre-trained weight parameters of the respective layers. All layers of the encoder that do not exist in BERT will simply have their weight parameters be randomly initialized.
Let's visualize.
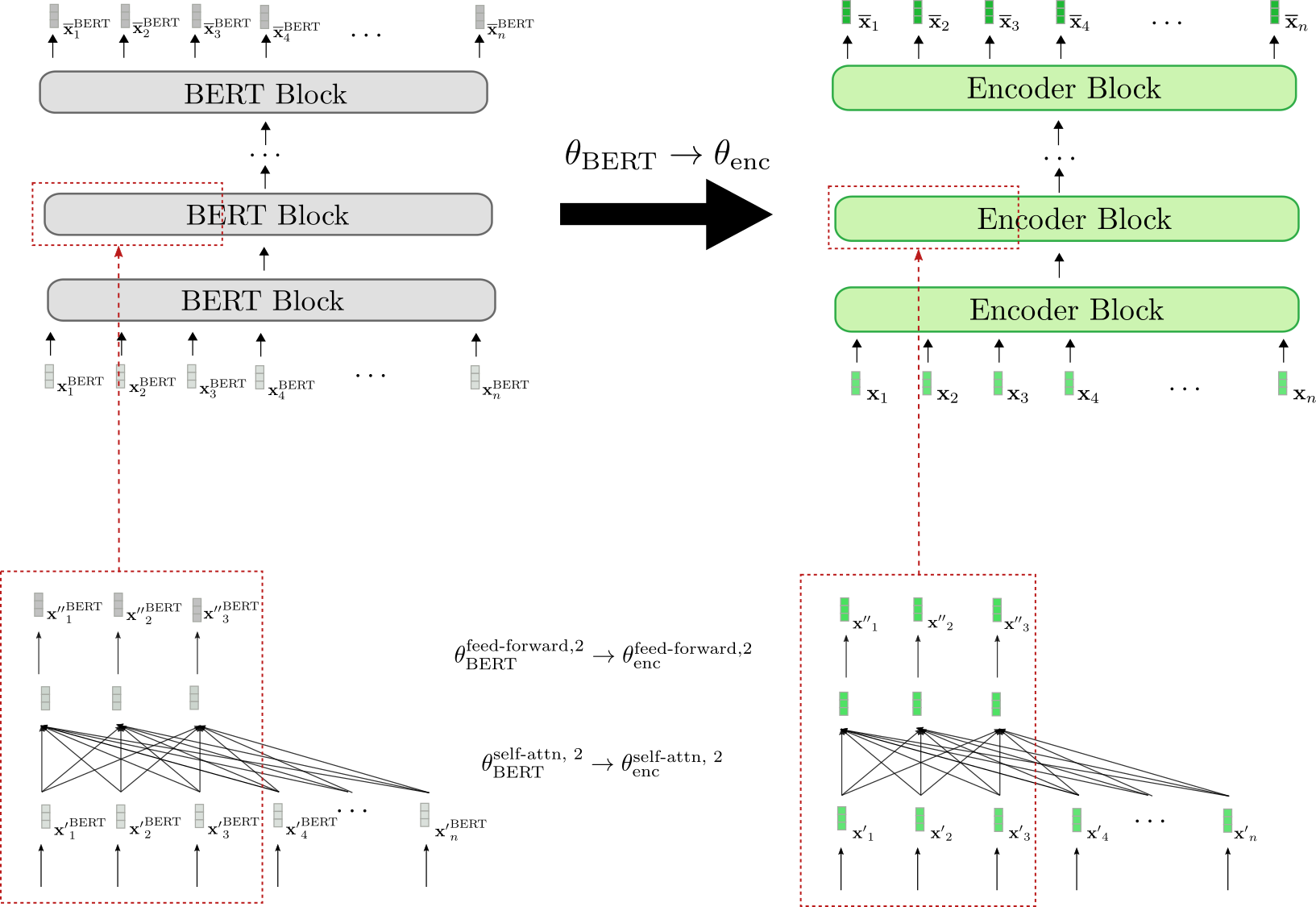
We can see that the encoder architecture corresponds 1-to-1 to BERT's architecture. The weight parameters of the bi-directional self-attention layer and the two feed-forward layers of all encoder blocks are initialized with the weight parameters of the respective BERT blocks. This is illustrated examplary for the second encoder block (red boxes at bottow) whose weight parameters and are set to BERT's weight parameters and , respectively at initialization.
Before fine-tuning, the encoder therefore behaves exactly like a pre-trained BERT model. Assuming the input sequence (shown in green) passed to the encoder is equal to the input sequence (shown in grey) passed to BERT, this means that the respective output vector sequences (shown in darker green) and (shown in darker grey) also have to be equal.
Next, let's illustrate how the decoder is warm-started.
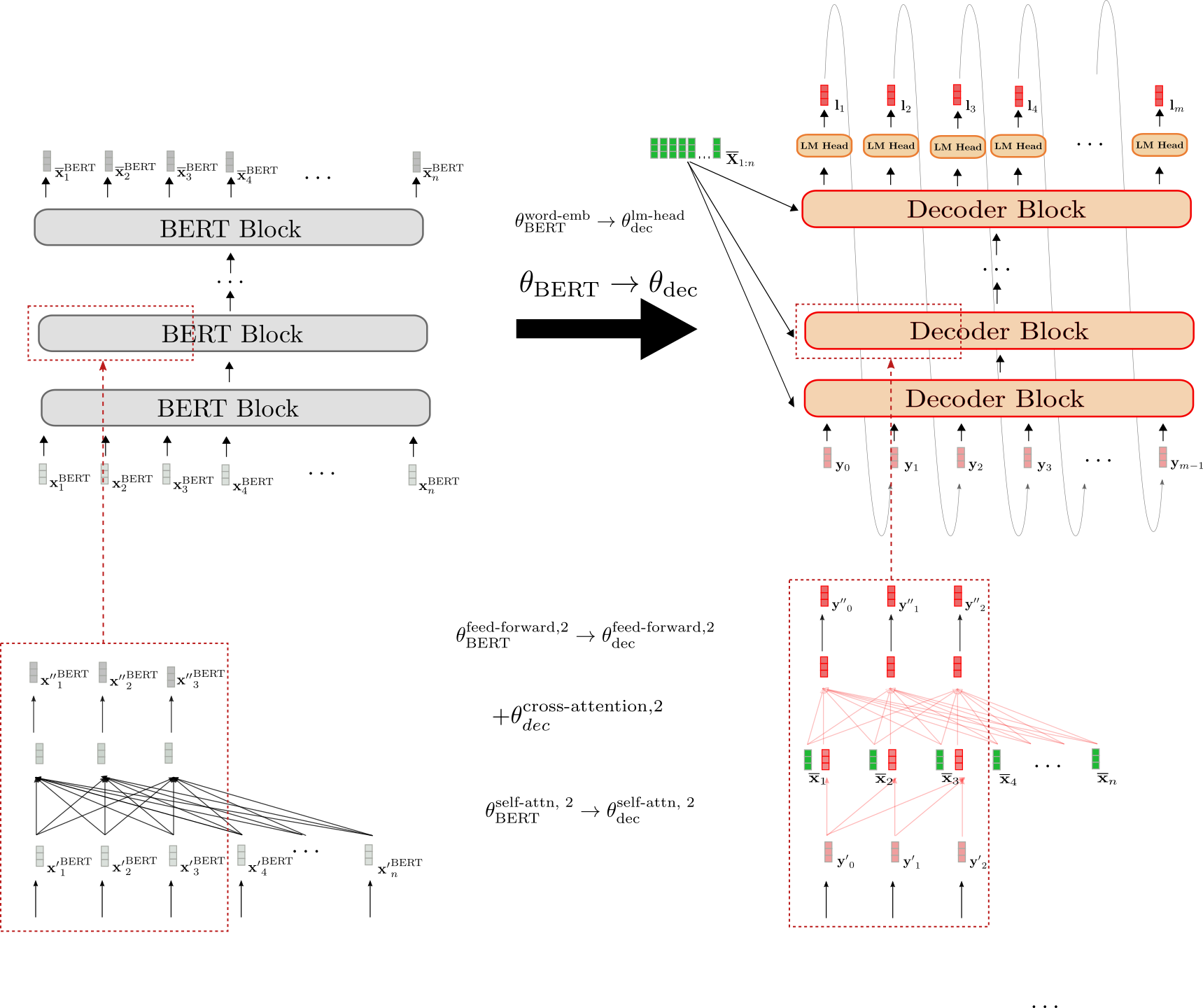
The architecture of the decoder is different from BERT's architecture in three ways.
First, the decoder has to be conditioned on the contextualized encoded sequence by means of cross-attention layers. Consequently, randomly initialized cross-attention layers are added between the self-attention layer and the two feed-forward layers in each BERT block. This is represented exemplary for the second block by and illustrated by the newly added fully connected graph in red in the lower red box on the right. This necessarily changes the behavior of each modified BERT block so that an input vector, e.g. now yields a random output vector (highlighted by the red border around the output vector ).
Second, BERT's bi-directional self-attention layers have to be changed to uni-directional self-attention layers to comply with auto-regressive generation. Because both the bi-directional and the uni-directional self-attention layer are based on the same key, query and value projection weights, the decoder's self-attention layer weights can be initialized with BERT's self-attention layer weights. E.g. the query, key and value weight parameters of the decoder's uni-directional self-attention layer are initialized with those of BERT's bi-directional self-attention layer However, in uni-directional self-attention each token only attends to all previous tokens, so that the decoder's self-attention layers yield different output vectors than BERT's self-attention layers even though they share the same weights. Compare e.g., the decoder's causally connected graph in the right box versus BERT's fully connected graph in the left box.
Third, the decoder outputs a sequence of logit vectors in order to define the conditional probability distribution . As a result, a LM Head layer is added on top of the last decoder block. The weight parameters of the LM Head layer usually correspond to the weight parameters of the word embedding and thus are not randomly initialized. This is illustrated in the top by the initialization .
To conclude, when warm-starting the decoder from a pre-trained BERT model only the cross-attention layer weights are randomly initialized. All other weights including those of the self-attention layer and LM Head are initialized with BERT's pre-trained weight parameters.
Having warm-stared the encoder-decoder model, the weights are then fine-tuned on a sequence-to-sequence downstream task, such as summarization.
Warm-staring Encoder-Decoder with BERT and GPT2
Instead of warm-starting both the encoder and decoder with a BERT checkpoint, we can instead leverage the BERT checkpoint for the encoder and a GPT2 checkpoint for the decoder. At first glance, a decoder-only GPT2 checkpoint seems to be better-suited to warm-start the decoder because it has already been trained on causal language modeling and uses uni-directional self-attention layers.
Let's illustrate how a GPT2 checkpoint can be used to warm-start the decoder.
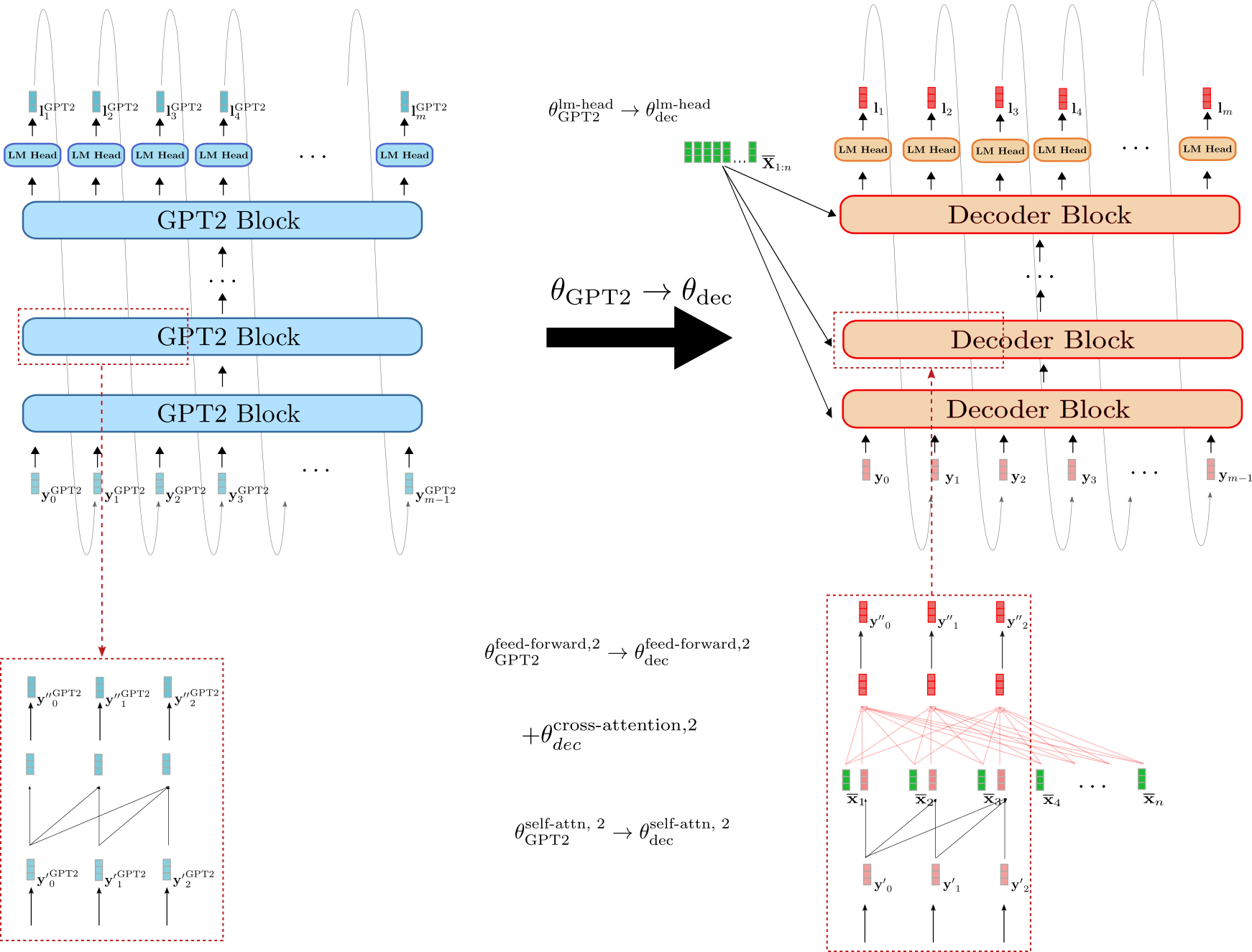
We can see that decoder is more similar to GPT2 than it is to BERT. The weight parameters of decoder's LM Head can directly be initialized with GPT2's LM Head weight parameters, e.g. . In addition, the blocks of the decoder and GPT2 both make use of uni-directional self-attention so that the output vectors of the decoder's self-attention layer are equivalent to GPT2's output vectors assuming the input vectors are the same, e.g. . In contrast to the BERT-initialized decoder, the GPT2-initialized decoder, therefore, keeps the causal connected graph of the self-attention layer as can be seen in the red boxes on the bottom.
Nevertheless, the GPT2-initialized decoder also has to condition the decoder on . Analoguos to the BERT-initialized decoder, randomly initialized weight parameters for the cross-attention layer are therefore added to each decoder block. This is illustrated e.g. for the second encoder block by .
Even though GPT2 resembles the decoder part of an encoder-decoder model more than BERT, a GPT2-initialized decoder will also yield random logit vectors without fine-tuning due to randomly initialized cross-attention layers in every decoder block. It would be interesting to investigate whether a GPT2-initialized decoder yields better results or can be fine-tuned more efficiently.
Encoder-Decoder Weight Sharing
In Raffel et al. (2020), the
authors show that a randomly-initialized encoder-decoder model that
shares the encoder's weights with the decoder, and therefore reduces
the memory footprint by half, performs only slightly worse than its
"non-shared" version. Sharing the encoder's weights with the decoder
means that all layers of the decoder that are found at the same position
in the encoder share the same weight parameters, i.e. the same node in
the network's computation graph.
E.g. the query, key, and value projection matrices of the
self-attention layer in the third encoder block, defined as , , are identical to the
respective query, key, and value projections matrices of the
self-attention layer in the third decoder block :
As a result, the key projection weights are updated twice for each backward propagation pass - once when the gradient is backpropagated through the third decoder block and once when the gradient is backprapageted thourgh the third encoder block.
In the same way, we can warm-start an encoder-decoder model by sharing the encoder weights with the decoder. Being able to share the weights between the encoder and decoder requires the decoder architecture (excluding the cross-attention weights) to be identical to the encoder architecture. Therefore, encoder-decoder weight sharing is only relevant if the encoder-decoder model is warm-started from a single encoder-only pre-trained checkpoint.
Great! That was the theory about warm-starting encoder-decoder models. Let's now look at some results.
Without loss of generality, we exclude the normalization layers to not clutter the equations and illustrations. For more detail on how self-attention layers function, please refer to this section of the transformer-based encoder-decoder model blog post for the encoder-part (and this section for the decoder part respectively).
Warm-starting encoder-decoder models (Analysis)
In this section, we will summarize the findings on warm-starting encoder-decoder models as presented in Leveraging Pre-trained Checkpoints for Sequence Generation Tasks by Sascha Rothe, Shashi Narayan, and Aliaksei Severyn. The authors compared the performance of warm-started encoder-decoder models to randomly initialized encoder-decoder models on multiple sequence-to-sequence tasks, notably summarization, translation, sentence splitting, and sentence fusion.
To be more precise, the publicly available pre-trained checkpoints of BERT, RoBERTa, and GPT2 were leveraged in different variations to warm-start an encoder-decoder model. E.g. a BERT-initialised encoder was paired with a BERT-initialized decoder yielding a BERT2BERT model or a RoBERTa-initialized encoder was paired with a GPT2-initialized decoder to yield a RoBERTa2GPT2 model. Additionally, the effect of sharing the encoder and decoder weights (as explained in the previous section) was investigated for RoBERTa, i.e. RoBERTaShare, and for BERT, i.e. BERTShare. Randomly or partly randomly initialized encoder-decoder models were used as a baseline, such as a fully randomly initialized encoder-decoder model, coined Rnd2Rnd or a BERT-initialized decoder paired with a randomly initialized encoder, defined as Rnd2BERT.
The following table shows a complete list of all investigated model
variants including the number of randomly initialized weights, i.e.
"random", and the number of weights initialized from the respective
pre-trained checkpoints, i.e. "leveraged". All models are based on a
12-layer architecture with 768-dim hidden size embeddings, corresponding
to the bert-base-cased, bert-base-uncased, roberta-base, and
gpt2 checkpoints in the 🤗Transformers model hub.
| Model | random | leveraged | total |
|---|---|---|---|
| Rnd2Rnd | 221M | 0 | 221M |
| Rnd2BERT | 112M | 109M | 221M |
| BERT2Rnd | 112M | 109M | 221M |
| Rnd2GPT2 | 114M | 125M | 238M |
| BERT2BERT | 26M | 195M | 221M |
| BERTShare | 26M | 109M | 135M |
| RoBERTaShare | 26M | 126M | 152M |
| BERT2GPT2 | 26M | 234M | 260M |
| RoBERTa2GPT2 | 26M | 250M | 276M |
The model Rnd2Rnd, which is based on the BERT2BERT architecture,
contains 221M weight parameters - all of which are randomly initialized.
The other two "BERT-based" baselines Rnd2BERT and BERT2Rnd have
roughly half of their weights, i.e. 112M parameters, randomly
initialized. The other 109M weight parameters are leveraged from the
pre-trained bert-base-uncased checkpoint for the encoder- or decoder
part respectively. The models BERT2BERT, BERT2GPT2, and
RoBERTa2GPT2 have all of their encoder weight parameters leveraged
(from bert-base-uncased, roberta-base respectively) and most of the
decoder weight parameter weights as well (from gpt2,
bert-base-uncased respectively). 26M decoder weight parameters, which
correspond to the 12 cross-attention layers, are thereby randomly
initialized. RoBERTa2GPT2 and BERT2GPT2 are compared to the Rnd2GPT2
baseline. Also, it should be noted that the shared model variants
BERTShare and RoBERTaShare have significantly fewer parameters
because all encoder weight parameters are shared with the respective
decoder weight parameters.
Experiments
The above models were trained and evaluated on four sequence-to-sequence tasks of increasing complexity: sentence-level fusion, sentence-level splitting, translation, and abstractive summarization. The following table shows which datasets were used for each task.
| Seq2Seq Task | Datasets | Paper | 🤗datasets |
|---|---|---|---|
| Sentence Fusion | DiscoFuse | Geva et al. (2019) | link |
| Sentence Splitting | WikiSplit | Botha et al. (2018) | - |
| Translation | WMT14 EN => DE | Bojar et al. (2014) | link |
| WMT14 DE => EN | Bojar et al. (2014) | link | |
| Abstractive Summarizaion | CNN/Dailymail | Hermann et al. (2015) | link |
| BBC XSum | Narayan et al. (2018a) | link | |
| Gigaword | Napoles et al. (2012) | link |
Depending on the task, a slightly different training regime was used. E.g. according to the size of the dataset and the specific task, the number of training steps ranges from 200K to 500K, the batch size is set to either 128 or 256, the input length ranges from 128 to 512 and the output length varies between 32 to 128. It shall be emphasized however that within each task, all models were trained and evaluated using the same hyperparameters to ensure a fair comparison. For more information on the task-specific hyperparameter settings, the reader is advised to see the Experiments section in the paper.
We will now give a condensed overview of the results for each task.
Sentence Fusion and -Splitting (DiscoFuse, WikiSplit)
Sentence Fusion is the task of combining multiple sentences into a single coherent sentence. E.g. the two sentences:
As a run-blocker, Zeitler moves relatively well. Zeitler too often struggles at the point of contact in space.
should be connected with a fitting linking word, such as:
As a run-blocker, Zeitler moves relatively well. However, he too often struggles at the point of contact in space.
As can be seen the linking word "however" provides a coherent transition from the first sentence to the second one. A model that is capable of generating such a linking word has arguably learned to infer that the two sentences above contrast to each other.
The inverse task is called Sentence splitting and consists of splitting a single complex sentence into multiple simpler ones that together retain the same meaning. Sentence splitting is considered as an important task in text simplification, cf. to Botha et al. (2018).
As an example, the sentence:
Street Rod is the first in a series of two games released for the PC and Commodore 64 in 1989
can be simplified into
Street Rod is the first in a series of two games . It was released for the PC and Commodore 64 in 1989
It can be seen that the long sentence tries to convey two important pieces of information. One is that the game was the first of two games being released for the PC, and the second being the year in which it was released. Sentence splitting, therefore, requires the model to understand which part of the sentence should be divided into two sentences, making the task more difficult than sentence fusion.
A common metric to evaluate the performance of models on sentence fusion resp. -splitting tasks is SARI (Wu et al. (2016), which is broadly based on the F1-score of label and model output.
Let's see how the models perform on sentence fusion and -splitting.
| Model | 100% DiscoFuse (SARI) | 10% DiscoFuse (SARI) | 100% WikiSplit (SARI) |
|---|---|---|---|
| Rnd2Rnd | 86.9 | 81.5 | 61.7 |
| Rnd2BERT | 87.6 | 82.1 | 61.8 |
| BERT2Rnd | 89.3 | 86.1 | 63.1 |
| Rnd2GPT2 | 86.5 | 81.4 | 61.3 |
| BERT2BERT | 89.3 | 86.1 | 63.2 |
| BERTShare | 89.2 | 86.0 | 63.5 |
| RoBERTaShare | 89.7 | 86.0 | 63.4 |
| BERT2GPT2 | 88.4 | 84.1 | 62.4 |
| RoBERTa2GPT2 | 89.9 | 87.1 | 63.2 |
| --- | --- | --- | --- |
| RoBERTaShare (large) | 90.3 | 87.7 | 63.8 |
The first two columns show the performance of the encoder-decoder models on the DiscoFuse evaluation data. The first column states the results of encoder-decoder models trained on all (100%) of the training data, while the second column shows the results of the models trained only on 10% of the training data. We observe that warm-started models perform significantly better than the randomly initialized baseline models Rnd2Rnd, Rnd2Bert, and Rnd2GPT2. A warm-started RoBERTa2GPT2 model trained only on 10% of the training data is on par with an Rnd2Rnd model trained on 100% of the training data. Interestingly, the Bert2Rnd baseline performs equally well as a fully warm-started Bert2Bert model, which indicates that warm-starting the encoder-part is more effective than warm-starting the decoder-part. The best results are obtained by RoBERTa2GPT2, followed by RobertaShare. Sharing encoder and decoder weight parameters does seem to slightly increase the model's performance.
On the more difficult sentence splitting task, a similar pattern emerges. Warm-started encoder-decoder models significantly outperform encoder-decoder models whose encoder is randomly initialized and encoder-decoder models with shared weight parameters yield better results than those with uncoupled weight parameters. On sentence splitting the BertShare models yields the best performance closely followed by RobertaShare.
In addition to the 12-layer model variants, the authors also trained and evaluated a 24-layer RobertaShare (large) model which outperforms all 12-layer models significantly.
Machine Translation (WMT14)
Next, the authors evaluated warm-started encoder-decoder models on the
probably most common benchmark in machine translation (MT) - the En De and De En WMT14 dataset. In this notebook, we
present the results on the newstest2014 eval dataset. Because the
benchmark requires the model to understand both an English and a German
vocabulary the BERT-initialized encoder-decoder models were warm-started
from the multilingual pre-trained checkpoint
bert-base-multilingual-cased. Because there is no publicly available
multilingual RoBERTa checkpoint, RoBERTa-initialized encoder-decoder
models were excluded for MT. GPT2-initialized models were initialized
from the gpt2 pre-trained checkpoint as in the previous experiment.
The translation results are reported using the BLUE-4 score metric .
| Model | En De (BLEU-4) | De En (BLEU-4) |
|---|---|---|
| Rnd2Rnd | 26.0 | 29.1 |
| Rnd2BERT | 27.2 | 30.4 |
| BERT2Rnd | 30.1 | 32.7 |
| Rnd2GPT2 | 19.6 | 23.2 |
| BERT2BERT | 30.1 | 32.7 |
| BERTShare | 29.6 | 32.6 |
| BERT2GPT2 | 23.2 | 31.4 |
| --- | --- | --- |
| BERT2Rnd (large, custom) | 31.7 | 34.2 |
| BERTShare (large, custom) | 30.5 | 33.8 |
Again, we observe a significant performance boost by warm-starting the
encoder-part, with BERT2Rnd and BERT2BERT yielding the best results
on both the En De and De En tasks. GPT2
initialized models perform significantly worse even than the Rnd2Rnd
baseline on En De. Taking into consideration that the gpt2
checkpoint was trained only on English text, it is not very surprising
that BERT2GPT2 and Rnd2GPT2 models have difficulties generating
German translations. This hypothesis is supported by the competitive
results (e.g. 31.4 vs. 32.7) of BERT2GPT2 on the De En
task for which GPT2's vocabulary fits the English output format.
Contrary to the results obtained on sentence fusion and sentence
splitting, sharing encoder and decoder weight parameters does not yield
a performance boost in MT. Possible reasons for this as stated by the
authors include
- the encoder-decoder model capacity is an important factor in MT, and
- the encoder and decoder have to deal with different grammar and vocabulary
Since the bert-base-multilingual-cased checkpoint was trained on more than 100 languages, its vocabulary is probably undesirably large for En De and De En MT. Thus, the authors pre-trained a large BERT encoder-only checkpoint on the English and German subset of the Wikipedia dump and subsequently used it to warm-start a BERT2Rnd and BERTShare encoder-decoder model. Thanks to the improved vocabulary, another significant performance boost is observed, with BERT2Rnd (large, custom) significantly outperforming all other models.
Summarization (CNN/Dailymail, BBC XSum, Gigaword)
Finally, the encoder-decoder models were evaluated on the arguably most challenging sequence-to-sequence task - summarization. The authors picked three summarization datasets with different characteristics for evaluation: Gigaword (headline generation), BBC XSum (extreme summarization), and CNN/Dailymayl (abstractive summarization).
The Gigaword dataset contains sentence-level abstractive summarizations, requiring the model to learn sentence-level understanding, abstraction, and eventually paraphrasing. A typical data sample in Gigaword, such as
"*venezuelan president hugo chavez said thursday he has ordered a probe into a suspected coup plot allegedly involving active and retired military officers .*",
would have a corresponding headline as its label, e.g.:
"chavez orders probe into suspected coup plot".
The BBC XSum dataset consists of much longer article-like text inputs with the labels being mostly single sentence summarizations. This dataset requires the model not only to learn document-level inference but also a high level of abstractive paraphrasing. Some data samples of the BBC XSUM datasets are shown here.
For the CNN/Dailmail dataset, documents, which are of similar length than those in the BBC XSum dataset, have to be summarized to bullet-point story highlights. The labels therefore often consist of multiple sentences. Besides document-level understanding, the CNN/Dailymail dataset requires models to be good at copying the most salient information. Some examples can be viewed here.
The models are evaluated using the Rouge metric, whereas the Rouge-2 scores are shown below.
Alright, let's take a look at the results.
| Model | CNN/Dailymail (Rouge-2) | BBC XSum (Rouge-2) | Gigaword (Rouge-2) |
|---|---|---|---|
| Rnd2Rnd | 14.00 | 10.23 | 18.71 |
| Rnd2BERT | 15.55 | 11.52 | 18.91 |
| BERT2Rnd | 17.76 | 15.83 | 19.26 |
| Rnd2GPT2 | 8.81 | 8.77 | 18.39 |
| BERT2BERT | 17.84 | 15.24 | 19.68 |
| BERTShare | 18.10 | 16.12 | 19.81 |
| RoBERTaShare | 18.95 | 17.50 | 19.70 |
| BERT2GPT2 | 4.96 | 8.37 | 18.23 |
| RoBERTa2GPT2 | 14.72 | 5.20 | 19.21 |
| --- | --- | --- | --- |
| RoBERTaShare (large) | 18.91 | 18.79 | 19.78 |
We observe again that warm-starting the encoder-part gives a significant improvement over models with randomly-initialized encoders, which is especially visible for document-level abstraction tasks, i.e. CNN/Dailymail and BBC XSum. This shows that tasks requiring a high level of abstraction benefit more from a pre-trained encoder part than those requiring only sentence-level abstraction. Except for Gigaword GPT2-based encoder-decoder models seem to be unfit for summarization.
Furthermore, the shared encoder-decoder models are the best performing models for summarization. RoBERTaShare and BERTShare are the best performing models on all datasets whereas the margin is especially significant on the BBC XSum dataset on which RoBERTaShare (large) outperforms BERT2BERT and BERT2Rnd by ca. 3 Rouge-2 points and Rnd2Rnd by more than 8 Rouge-2 points. As brought forward by the authors, "this is probably because the BBC summary sentences follow a distribution that is similar to that of the sentences in the document, whereas this is not necessarily the case for the Gigaword headlines and the CNN/DailyMail bullet-point highlights". Intuitively this means that in BBC XSum, the input sentences processed by the encoder are very similar in structure to the single sentence summary processed by the decoder, i.e. same length, similar choice of words, similar syntax.
Conclusion
Alright, let's draw a conclusion and try to derive some practical tips.
We have observed on all tasks that a warm-started encoder-part gives a significant performance boost compared to encoder-decoder models having a randomly initialized encoder. On the other hand, warm-starting the decoder seems to be less important, with BERT2BERT being on par with BERT2Rnd on most tasks. An intuitive reason would be that since a BERT- or RoBERTa-initialized encoder part has none of its weight parameters randomly initialized, the encoder can fully exploit the acquired knowledge of BERT's or RoBERTa's pre-trained checkpoints, respectively. In contrast, the warm-started decoder always has parts of its weight parameters randomly initialized which possibly makes it much harder to effectively leverage the knowledge acquired by the checkpoint used to initialize the decoder.
Next, we noticed that it is often beneficial to share encoder and decoder weights, especially if the target distribution is similar to the input distribution (e.g. BBC XSum). However, for datasets whose target data distribution differs more significantly from the input data distribution and for which model capacity is known to play an important role, e.g. WMT14, encoder-decoder weight sharing seems to be disadvantageous.
Finally, we have seen that it is very important that the vocabulary of the pre-trained "stand-alone" checkpoints fit the vocabulary required to solve the sequence-to-sequence task. E.g. a warm-started BERT2GPT2 encoder-decoder will perform poorly on En De MT because GPT2 was pre-trained on English whereas the target language is German. The overall poor performance of the BERT2GPT2, Rnd2GPT2, and RoBERTa2GPT2 compared to BERT2BERT, BERTShared, and RoBERTaShared suggests that it is more effective to have a shared vocabulary. Also, it shows that initializing the decoder part with a pre-trained GPT2 checkpoint is not more effective than initializing it with a pre-trained BERT checkpoint besides GPT2 being more similar to the decoder in its architecture.
For each of the above tasks, the most performant models were ported to 🤗Transformers and can be accessed here:
- RoBERTaShared (large) - Wikisplit: google/roberta2roberta_L-24_wikisplit.
- RoBERTaShared (large) - Discofuse: google/roberta2roberta_L-24_discofuse.
- BERT2BERT (large) - WMT en de: google/bert2bert_L-24_wmt_en_de.
- BERT2BERT (large) - WMT de en: google/bert2bert_L-24_wmt_de_en.
- RoBERTaShared (large) - CNN/Dailymail: google/roberta2roberta_L-24_cnn_daily_mail.
- RoBERTaShared (large) - BBC XSum: google/roberta2roberta_L-24_bbc.
- RoBERTaShared (large) - Gigaword: google/roberta2roberta_L-24_gigaword.
To retrieve BLEU-4 scores, a script from the Tensorflow Official
Transformer implementation https://github.com/tensorflow/models/tree
master/official/nlp/transformer was used. Note that, differently from
the tensor2tensor/utils/ get_ende_bleu.sh used by Vaswani et al.
(2017), this script does not split noun compounds, but utf-8 quotes were
normalized to ascii quotes after having noted that the pre-processed
training set contains only ascii quotes.
Model capacity is an informal definition of how good the model is at modeling complex patterns. It is also sometimes defined as the ability of a model to learn from more and more data. Model capacity is broadly measured by the number of trainable parameters - the more parameters, the higher the model capacity.
Warm-starting encoder-decoder models with 🤗Transformers (Practice)
We have explained the theory of warm-starting encoder-decoder models, analyzed empirical results on multiple datasets, and have derived practical conclusions. Let's now walk through a complete code example showcasing how a BERT2BERT model can be warm-started and consequently fine-tuned on the CNN/Dailymail summarization task. We will be leveraging the 🤗datasets and 🤗Transformers libraries.
In addition, the following list provides a condensed version of this and other notebooks on warm-starting other combinations of encoder-decoder models.
- for BERT2BERT on CNN/Dailymail (a condensed version of this notebook), click here.
- for RoBERTaShare on BBC XSum, click here.
- for BERT2Rnd on WMT14 En De, click here.
- for RoBERTa2GPT2 on DiscoFuse, click here.
Note: This notebook only uses a few training, validation, and test data samples for demonstration purposes. To fine-tune an encoder-decoder model on the full training data, the user should change the training and data preprocessing parameters accordingly as highlighted by the comments.
Data Preprocessing
In this section, we show how the data can be pre-processed for training. More importantly, we try to give the reader some insight into the process of deciding how to preprocess the data.
We will need datasets and transformers to be installed.
!pip install datasets==1.0.2
!pip install transformers==4.2.1
Let's start by downloading the CNN/Dailymail dataset.
import datasets
train_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="train")
Alright, let's get a first impression of the dataset. Alternatively, the dataset can also be visualized using the awesome datasets viewer online.
train_data.info.description
Our input is called article and our labels are called highlights. Let's now print out the first example of the training data to get a feeling for the data.
import pandas as pd
from IPython.display import display, HTML
from datasets import ClassLabel
df = pd.DataFrame(train_data[:1])
del df["id"]
for column, typ in train_data.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
OUTPUT:
-------
Article:
"""It's official: U.S. President Barack Obama wants lawmakers to weigh in on whether to use military force in Syria. Obama sent a letter to the heads of the House and Senate on Saturday night, hours after announcing that he believes military action against Syrian targets is the right step to take over the alleged use of chemical weapons. The proposed legislation from Obama asks Congress to approve the use of military force "to deter, disrupt, prevent and degrade the potential for future uses of chemical weapons or other weapons of mass destruction." It's a step that is set to turn an international crisis into a fierce domestic political battle. There are key questions looming over the debate: What did U.N. weapons inspectors find in Syria? What happens if Congress votes no? And how will the Syrian government react? In a televised address from the White House Rose Garden earlier Saturday, the president said he would take his case to Congress, not because he has to -- but because he wants to. "While I believe I have the authority to carry out this military action without specific congressional authorization, I know that the country will be stronger if we take this course, and our actions will be even more effective," he said. "We should have this debate, because the issues are too big for business as usual." Obama said top congressional leaders had agreed to schedule a debate when the body returns to Washington on September 9. The Senate Foreign Relations Committee will hold a hearing over the matter on Tuesday, Sen. Robert Menendez said. Transcript: Read Obama's full remarks . Syrian crisis: Latest developments . U.N. inspectors leave Syria . Obama's remarks came shortly after U.N. inspectors left Syria, carrying evidence that will determine whether chemical weapons were used in an attack early last week in a Damascus suburb. "The aim of the game here, the mandate, is very clear -- and that is to ascertain whether chemical weapons were used -- and not by whom," U.N. spokesman Martin Nesirky told reporters on Saturday. But who used the weapons in the reported toxic gas attack in a Damascus suburb on August 21 has been a key point of global debate over the Syrian crisis. Top U.S. officials have said there's no doubt that the Syrian government was behind it, while Syrian officials have denied responsibility and blamed jihadists fighting with the rebels. British and U.S. intelligence reports say the attack involved chemical weapons, but U.N. officials have stressed the importance of waiting for an official report from inspectors. The inspectors will share their findings with U.N. Secretary-General Ban Ki-moon Ban, who has said he wants to wait until the U.N. team's final report is completed before presenting it to the U.N. Security Council. The Organization for the Prohibition of Chemical Weapons, which nine of the inspectors belong to, said Saturday that it could take up to three weeks to analyze the evidence they collected. "It needs time to be able to analyze the information and the samples," Nesirky said. He noted that Ban has repeatedly said there is no alternative to a political solution to the crisis in Syria, and that "a military solution is not an option." Bergen: Syria is a problem from hell for the U.S. Obama: 'This menace must be confronted' Obama's senior advisers have debated the next steps to take, and the president's comments Saturday came amid mounting political pressure over the situation in Syria. Some U.S. lawmakers have called for immediate action while others warn of stepping into what could become a quagmire. Some global leaders have expressed support, but the British Parliament's vote against military action earlier this week was a blow to Obama's hopes of getting strong backing from key NATO allies. On Saturday, Obama proposed what he said would be a limited military action against Syrian President Bashar al-Assad. Any military attack would not be open-ended or include U.S. ground forces, he said. Syria's alleged use of chemical weapons earlier this month "is an assault on human dignity," the president said. A failure to respond with force, Obama argued, "could lead to escalating use of chemical weapons or their proliferation to terrorist groups who would do our people harm. In a world with many dangers, this menace must be confronted." Syria missile strike: What would happen next? Map: U.S. and allied assets around Syria . Obama decision came Friday night . On Friday night, the president made a last-minute decision to consult lawmakers. What will happen if they vote no? It's unclear. A senior administration official told CNN that Obama has the authority to act without Congress -- even if Congress rejects his request for authorization to use force. Obama on Saturday continued to shore up support for a strike on the al-Assad government. He spoke by phone with French President Francois Hollande before his Rose Garden speech. "The two leaders agreed that the international community must deliver a resolute message to the Assad regime -- and others who would consider using chemical weapons -- that these crimes are unacceptable and those who violate this international norm will be held accountable by the world," the White House said. Meanwhile, as uncertainty loomed over how Congress would weigh in, U.S. military officials said they remained at the ready. 5 key assertions: U.S. intelligence report on Syria . Syria: Who wants what after chemical weapons horror . Reactions mixed to Obama's speech . A spokesman for the Syrian National Coalition said that the opposition group was disappointed by Obama's announcement. "Our fear now is that the lack of action could embolden the regime and they repeat his attacks in a more serious way," said spokesman Louay Safi. "So we are quite concerned." Some members of Congress applauded Obama's decision. House Speaker John Boehner, Majority Leader Eric Cantor, Majority Whip Kevin McCarthy and Conference Chair Cathy McMorris Rodgers issued a statement Saturday praising the president. "Under the Constitution, the responsibility to declare war lies with Congress," the Republican lawmakers said. "We are glad the president is seeking authorization for any military action in Syria in response to serious, substantive questions being raised." More than 160 legislators, including 63 of Obama's fellow Democrats, had signed letters calling for either a vote or at least a "full debate" before any U.S. action. British Prime Minister David Cameron, whose own attempt to get lawmakers in his country to support military action in Syria failed earlier this week, responded to Obama's speech in a Twitter post Saturday. "I understand and support Barack Obama's position on Syria," Cameron said. An influential lawmaker in Russia -- which has stood by Syria and criticized the United States -- had his own theory. "The main reason Obama is turning to the Congress: the military operation did not get enough support either in the world, among allies of the US or in the United States itself," Alexei Pushkov, chairman of the international-affairs committee of the Russian State Duma, said in a Twitter post. In the United States, scattered groups of anti-war protesters around the country took to the streets Saturday. "Like many other Americans...we're just tired of the United States getting involved and invading and bombing other countries," said Robin Rosecrans, who was among hundreds at a Los Angeles demonstration. What do Syria's neighbors think? Why Russia, China, Iran stand by Assad . Syria's government unfazed . After Obama's speech, a military and political analyst on Syrian state TV said Obama is "embarrassed" that Russia opposes military action against Syria, is "crying for help" for someone to come to his rescue and is facing two defeats -- on the political and military levels. Syria's prime minister appeared unfazed by the saber-rattling. "The Syrian Army's status is on maximum readiness and fingers are on the trigger to confront all challenges," Wael Nader al-Halqi said during a meeting with a delegation of Syrian expatriates from Italy, according to a banner on Syria State TV that was broadcast prior to Obama's address. An anchor on Syrian state television said Obama "appeared to be preparing for an aggression on Syria based on repeated lies." A top Syrian diplomat told the state television network that Obama was facing pressure to take military action from Israel, Turkey, some Arabs and right-wing extremists in the United States. "I think he has done well by doing what Cameron did in terms of taking the issue to Parliament," said Bashar Jaafari, Syria's ambassador to the United Nations. Both Obama and Cameron, he said, "climbed to the top of the tree and don't know how to get down." The Syrian government has denied that it used chemical weapons in the August 21 attack, saying that jihadists fighting with the rebels used them in an effort to turn global sentiments against it. British intelligence had put the number of people killed in the attack at more than 350. On Saturday, Obama said "all told, well over 1,000 people were murdered." U.S. Secretary of State John Kerry on Friday cited a death toll of 1,429, more than 400 of them children. No explanation was offered for the discrepancy. Iran: U.S. military action in Syria would spark 'disaster' Opinion: Why strikes in Syria are a bad idea ."""
Summary:
"""Syrian official: Obama climbed to the top of the tree, "doesn't know how to get down"\nObama sends a letter to the heads of the House and Senate .\nObama to seek congressional approval on military action against Syria .\nAim is to determine whether CW were used, not by whom, says U.N. spokesman"""
The input data seems to consist of short news articles. Interestingly, the labels appear to be bullet-point-like summaries. At this point, one should probably take a look at a couple of other examples to get a better feeling for the data.
One should also notice here that the text is case-sensitive. This
means that we have to be careful if we want to use case-insensitive
models. As CNN/Dailymail is a summarization dataset, the model will be
evaluated using the ROUGE metric. Checking the description of ROUGE
in 🤗datasets, cf. here, we can
see that the metric is case-insensitive, meaning that upper case
letters will be normalized to lower case letters during evaluation.
Thus, we can safely leverage uncased checkpoints, such as
bert-base-uncased.
Cool! Next, let's get a sense of the length of input data and labels.
As models compute length in token-length, we will make use of the
bert-base-uncased tokenizer to compute the article and summary length.
First, we load the tokenizer.
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
Next, we make use of .map() to compute the length of the article and
its summary. Since we know that the maximum length that
bert-base-uncased can process amounts to 512, we are also interested
in the percentage of input samples being longer than the maximum length.
Similarly, we compute the percentage of summaries that are longer than
64, and 128 respectively.
We can define the .map() function as follows.
# map article and summary len to dict as well as if sample is longer than 512 tokens
def map_to_length(x):
x["article_len"] = len(tokenizer(x["article"]).input_ids)
x["article_longer_512"] = int(x["article_len"] > 512)
x["summary_len"] = len(tokenizer(x["highlights"]).input_ids)
x["summary_longer_64"] = int(x["summary_len"] > 64)
x["summary_longer_128"] = int(x["summary_len"] > 128)
return x
It should be sufficient to look at the first 10000 samples. We can speed
up the mapping by using multiple processes with num_proc=4.
sample_size = 10000
data_stats = train_data.select(range(sample_size)).map(map_to_length, num_proc=4)
Having computed the length for the first 10000 samples, we should now
average them together. For this, we can make use of the .map()
function with batched=True and batch_size=-1 to have access to all
10000 samples within the .map() function.
def compute_and_print_stats(x):
if len(x["article_len"]) == sample_size:
print(
"Article Mean: {}, %-Articles > 512:{}, Summary Mean:{}, %-Summary > 64:{}, %-Summary > 128:{}".format(
sum(x["article_len"]) / sample_size,
sum(x["article_longer_512"]) / sample_size,
sum(x["summary_len"]) / sample_size,
sum(x["summary_longer_64"]) / sample_size,
sum(x["summary_longer_128"]) / sample_size,
)
)
output = data_stats.map(
compute_and_print_stats,
batched=True,
batch_size=-1,
)
OUTPUT:
-------
Article Mean: 847.6216, %-Articles > 512:0.7355, Summary Mean:57.7742, %-Summary > 64:0.3185, %-Summary > 128:0.0
We can see that on average an article contains 848 tokens with ca. 3/4
of the articles being longer than the model's max_length 512. The
summary is on average 57 tokens long. Over 30% of our 10000-sample
summaries are longer than 64 tokens, but none are longer than 128
tokens.
bert-base-cased is limited to 512 tokens, which means we would have to
cut possibly important information from the article. Because most of the
important information is often found at the beginning of articles and
because we want to be computationally efficient, we decide to stick to
bert-base-cased with a max_length of 512 in this notebook. This
choice is not optimal but has shown to yield good
results on CNN/Dailymail.
Alternatively, one could leverage long-range sequence models, such as
Longformer to be
used as the encoder.
Regarding the summary length, we can see that a length of 128 already
includes all of the summary labels. 128 is easily within the limits of
bert-base-cased, so we decide to limit the generation to 128.
Again, we will make use of the .map() function - this time to
transform each training batch into a batch of model inputs.
"article" and "highlights" are tokenized and prepared as the
Encoder's "input_ids" and Decoder's "decoder_input_ids"
respectively.
"labels" are shifted automatically to the left for language modeling
training.
Lastly, it is very important to remember to ignore the loss of the padded labels. In 🤗Transformers this can be done by setting the label to -100. Great, let's write down our mapping function then.
encoder_max_length=512
decoder_max_length=128
def process_data_to_model_inputs(batch):
# tokenize the inputs and labels
inputs = tokenizer(batch["article"], padding="max_length", truncation=True, max_length=encoder_max_length)
outputs = tokenizer(batch["highlights"], padding="max_length", truncation=True, max_length=decoder_max_length)
batch["input_ids"] = inputs.input_ids
batch["attention_mask"] = inputs.attention_mask
batch["labels"] = outputs.input_ids.copy()
# because BERT automatically shifts the labels, the labels correspond exactly to `decoder_input_ids`.
# We have to make sure that the PAD token is ignored
batch["labels"] = [[-100 if token == tokenizer.pad_token_id else token for token in labels] for labels in batch["labels"]]
return batch
In this notebook, we train and evaluate the model just on a few training
examples for demonstration and set the batch_size to 4 to prevent
out-of-memory issues.
The following line reduces the training data to only the first 32
examples. The cell can be commented out or not run for a full training
run. Good results were obtained with a batch_size of 16.
train_data = train_data.select(range(32))
Alright, let's prepare the training data.
# batch_size = 16
batch_size=4
train_data = train_data.map(
process_data_to_model_inputs,
batched=True,
batch_size=batch_size,
remove_columns=["article", "highlights", "id"]
)
Taking a look at the processed training dataset we can see that the
column names article, highlights, and id have been replaced by the
arguments expected by the EncoderDecoderModel.
train_data
OUTPUT:
-------
Dataset(features: {'attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'decoder_attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'decoder_input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'labels': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None)}, num_rows: 32)
So far, the data was manipulated using Python's List format. Let's
convert the data to PyTorch Tensors to be trained on GPU.
train_data.set_format(
type="torch", columns=["input_ids", "attention_mask", "labels"],
)
Awesome, the data processing of the training data is finished. Analogous, we can do the same for the validation data.
First, we load 10% of the validation dataset:
val_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="validation[:10%]")
For demonstration purposes, the validation data is then reduced to just 8 samples,
val_data = val_data.select(range(8))
the mapping function is applied,
val_data = val_data.map(
process_data_to_model_inputs,
batched=True,
batch_size=batch_size,
remove_columns=["article", "highlights", "id"]
)
and, finally, the validation data is also converted to PyTorch tensors.
val_data.set_format(
type="torch", columns=["input_ids", "attention_mask", "labels"],
)
Great! Now we can move to warm-starting the EncoderDecoderModel.
Warm-starting the Encoder-Decoder Model
This section explains how an Encoder-Decoder model can be warm-started
using the bert-base-cased checkpoint.
Let's start by importing the EncoderDecoderModel. For more detailed
information about the EncoderDecoderModel class, the reader is advised
to take a look at the
documentation.
from transformers import EncoderDecoderModel
In contrast to other model classes in 🤗Transformers, the
EncoderDecoderModel class has two methods to load pre-trained weights,
namely:
the "standard"
.from_pretrained(...)method is derived from the generalPretrainedModel.from_pretrained(...)method and thus corresponds exactly to the the one of other model classes. The function expects a single model identifier, e.g..from_pretrained("google/bert2bert_L-24_wmt_de_en")and will load a single.ptcheckpoint file into theEncoderDecoderModelclass.a special
.from_encoder_decoder_pretrained(...)method, which can be used to warm-start an encoder-decoder model from two model identifiers - one for the encoder and one for the decoder. The first model identifier is thereby used to load the encoder, viaAutoModel.from_pretrained(...)(see doc here) and the second model identifier is used to load the decoder viaAutoModelForCausalLM(see doc here.
Alright, let's warm-start our BERT2BERT model. As mentioned earlier
we will warm-start both the encoder and decoder with the
"bert-base-cased" checkpoint.
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased", "bert-base-uncased")
OUTPUT:
-------
"""Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertLMHeadModel: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing BertLMHeadModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing BertLMHeadModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertLMHeadModel were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['bert.encoder.layer.0.crossattention.self.query.weight', 'bert.encoder.layer.0.crossattention.self.query.bias', 'bert.encoder.layer.0.crossattention.self.key.weight', 'bert.encoder.layer.0.crossattention.self.key.bias', 'bert.encoder.layer.0.crossattention.self.value.weight', 'bert.encoder.layer.0.crossattention.self.value.bias', 'bert.encoder.layer.0.crossattention.output.dense.weight', 'bert.encoder.layer.0.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.0.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.1.crossattention.self.query.weight', 'bert.encoder.layer.1.crossattention.self.query.bias', 'bert.encoder.layer.1.crossattention.self.key.weight', 'bert.encoder.layer.1.crossattention.self.key.bias', 'bert.encoder.layer.1.crossattention.self.value.weight', 'bert.encoder.layer.1.crossattention.self.value.bias', 'bert.encoder.layer.1.crossattention.output.dense.weight', 'bert.encoder.layer.1.crossattention.output.dense.bias', 'bert.encoder.layer.1.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.1.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.2.crossattention.self.query.weight', 'bert.encoder.layer.2.crossattention.self.query.bias', 'bert.encoder.layer.2.crossattention.self.key.weight', 'bert.encoder.layer.2.crossattention.self.key.bias', 'bert.encoder.layer.2.crossattention.self.value.weight', 'bert.encoder.layer.2.crossattention.self.value.bias', 'bert.encoder.layer.2.crossattention.output.dense.weight', 'bert.encoder.layer.2.crossattention.output.dense.bias', 'bert.encoder.layer.2.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.2.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.3.crossattention.self.query.weight', 'bert.encoder.layer.3.crossattention.self.query.bias', 'bert.encoder.layer.3.crossattention.self.key.weight', 'bert.encoder.layer.3.crossattention.self.key.bias', 'bert.encoder.layer.3.crossattention.self.value.weight', 'bert.encoder.layer.3.crossattention.self.value.bias', 'bert.encoder.layer.3.crossattention.output.dense.weight', 'bert.encoder.layer.3.crossattention.output.dense.bias', 'bert.encoder.layer.3.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.3.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.4.crossattention.self.query.weight', 'bert.encoder.layer.4.crossattention.self.query.bias', 'bert.encoder.layer.4.crossattention.self.key.weight', 'bert.encoder.layer.4.crossattention.self.key.bias', 'bert.encoder.layer.4.crossattention.self.value.weight', 'bert.encoder.layer.4.crossattention.self.value.bias', 'bert.encoder.layer.4.crossattention.output.dense.weight', 'bert.encoder.layer.4.crossattention.output.dense.bias', 'bert.encoder.layer.4.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.4.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.5.crossattention.self.query.weight', 'bert.encoder.layer.5.crossattention.self.query.bias', 'bert.encoder.layer.5.crossattention.self.key.weight', 'bert.encoder.layer.5.crossattention.self.key.bias', 'bert.encoder.layer.5.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.self.value.bias', 'bert.encoder.layer.5.crossattention.output.dense.weight', 'bert.encoder.layer.5.crossattention.output.dense.bias', 'bert.encoder.layer.5.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.5.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.6.crossattention.self.query.weight', 'bert.encoder.layer.6.crossattention.self.query.bias', 'bert.encoder.layer.6.crossattention.self.key.weight', 'bert.encoder.layer.6.crossattention.self.key.bias', 'bert.encoder.layer.6.crossattention.self.value.weight', 'bert.encoder.layer.6.crossattention.self.value.bias', 'bert.encoder.layer.6.crossattention.output.dense.weight', 'bert.encoder.layer.6.crossattention.output.dense.bias', 'bert.encoder.layer.6.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.6.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.7.crossattention.self.query.weight', 'bert.encoder.layer.7.crossattention.self.query.bias', 'bert.encoder.layer.7.crossattention.self.key.weight', 'bert.encoder.layer.7.crossattention.self.key.bias', 'bert.encoder.layer.7.crossattention.self.value.weight', 'bert.encoder.layer.7.crossattention.self.value.bias', 'bert.encoder.layer.7.crossattention.output.dense.weight', 'bert.encoder.layer.7.crossattention.output.dense.bias', 'bert.encoder.layer.7.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.7.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.8.crossattention.self.query.weight', 'bert.encoder.layer.8.crossattention.self.query.bias', 'bert.encoder.layer.8.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.self.key.bias', 'bert.encoder.layer.8.crossattention.self.value.weight', 'bert.encoder.layer.8.crossattention.self.value.bias', 'bert.encoder.layer.8.crossattention.output.dense.weight', 'bert.encoder.layer.8.crossattention.output.dense.bias', 'bert.encoder.layer.8.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.8.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.9.crossattention.self.query.weight', 'bert.encoder.layer.9.crossattention.self.query.bias', 'bert.encoder.layer.9.crossattention.self.key.weight', 'bert.encoder.layer.9.crossattention.self.key.bias', 'bert.encoder.layer.9.crossattention.self.value.weight', 'bert.encoder.layer.9.crossattention.self.value.bias', 'bert.encoder.layer.9.crossattention.output.dense.weight', 'bert.encoder.layer.9.crossattention.output.dense.bias', 'bert.encoder.layer.9.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.9.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.10.crossattention.self.query.weight', 'bert.encoder.layer.10.crossattention.self.query.bias', 'bert.encoder.layer.10.crossattention.self.key.weight', 'bert.encoder.layer.10.crossattention.self.key.bias', 'bert.encoder.layer.10.crossattention.self.value.weight', 'bert.encoder.layer.10.crossattention.self.value.bias', 'bert.encoder.layer.10.crossattention.output.dense.weight', 'bert.encoder.layer.10.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.10.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.11.crossattention.self.query.weight', 'bert.encoder.layer.11.crossattention.self.query.bias', 'bert.encoder.layer.11.crossattention.self.key.weight', 'bert.encoder.layer.11.crossattention.self.key.bias', 'bert.encoder.layer.11.crossattention.self.value.weight', 'bert.encoder.layer.11.crossattention.self.value.bias', 'bert.encoder.layer.11.crossattention.output.dense.weight', 'bert.encoder.layer.11.crossattention.output.dense.bias', 'bert.encoder.layer.11.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.11.crossattention.output.LayerNorm.bias']"""
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference."""
For once, we should take a good look at the warning here. We can see
that two weights corresponding to a "cls" layer were not used. This
should not be a problem because we don't need BERT's CLS layer for
sequence-to-sequence tasks. Also, we notice that a lot of weights are
"newly" or randomly initialized. When taking a closer look these
weights all correspond to the cross-attention layer, which is exactly
what we would expect after having read the theory above.
Let's take a closer look at the model.
bert2bert
OUTPUT:
-------
EncoderDecoderModel(
(encoder): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
),
...
,
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(decoder): BertLMHeadModel(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
),
...,
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(cls): BertOnlyMLMHead(
(predictions): BertLMPredictionHead(
(transform): BertPredictionHeadTransform(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(decoder): Linear(in_features=768, out_features=30522, bias=True)
)
)
)
)
We see that bert2bert.encoder is an instance of BertModel and that
bert2bert.decoder one of BertLMHeadModel. However, both instances
are now combined into a single torch.nn.Module and can thus be saved
as a single .pt checkpoint file.
Let's try it out using the standard .save_pretrained(...) method.
bert2bert.save_pretrained("bert2bert")
Similarly, the model can be reloaded using the standard
.from_pretrained(...) method.
bert2bert = EncoderDecoderModel.from_pretrained("bert2bert")
Awesome. Let's also checkpoint the config.
bert2bert.config
OUTPUT:
-------
EncoderDecoderConfig {
"_name_or_path": "bert2bert",
"architectures": [
"EncoderDecoderModel"
],
"decoder": {
"_name_or_path": "bert-base-uncased",
"add_cross_attention": true,
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bad_words_ids": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"decoder_start_token_id": null,
"do_sample": false,
"early_stopping": false,
"eos_token_id": null,
"finetuning_task": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": true,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"min_length": 0,
"model_type": "bert",
"no_repeat_ngram_size": 0,
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"pad_token_id": 0,
"prefix": null,
"pruned_heads": {},
"repetition_penalty": 1.0,
"return_dict": false,
"sep_token_id": null,
"task_specific_params": null,
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 30522,
"xla_device": null
},
"encoder": {
"_name_or_path": "bert-base-uncased",
"add_cross_attention": false,
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bad_words_ids": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"decoder_start_token_id": null,
"do_sample": false,
"early_stopping": false,
"eos_token_id": null,
"finetuning_task": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"min_length": 0,
"model_type": "bert",
"no_repeat_ngram_size": 0,
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"pad_token_id": 0,
"prefix": null,
"pruned_heads": {},
"repetition_penalty": 1.0,
"return_dict": false,
"sep_token_id": null,
"task_specific_params": null,
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 30522,
"xla_device": null
},
"is_encoder_decoder": true,
"model_type": "encoder_decoder"
}
The config is similarly composed of an encoder config and a decoder
config both of which are instances of BertConfig in our case. However,
the overall config is of type EncoderDecoderConfig and is therefore
saved as a single .json file.
In conclusion, one should remember that once an EncoderDecoderModel
object is instantiated, it provides the same functionality as any other
Encoder-Decoder model in 🤗Transformers, e.g.
BART,
T5,
ProphetNet,
... The only difference is that an EncoderDecoderModel provides the
additional from_encoder_decoder_pretrained(...) function allowing the
model class to be warm-started from any two encoder and decoder
checkpoints.
On a side-note, if one would want to create a shared encoder-decoder
model, the parameter tie_encoder_decoder=True can additionally be
passed as follows:
shared_bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-cased", "bert-base-cased", tie_encoder_decoder=True)
As a comparison, we can see that the tied model has much fewer parameters as expected.
print(f"\n\nNum Params. Shared: {shared_bert2bert.num_parameters()}, Non-Shared: {bert2bert.num_parameters()}")
OUTPUT:
-------
Num Params. Shared: 137298244, Non-Shared: 247363386
In this notebook, we will however train a non-shared Bert2Bert model,
so we continue with bert2bert and not shared_bert2bert.
# free memory
del shared_bert2bert
We have warm-started a bert2bert model, but we have not defined all
the relevant parameters used for beam search decoding yet.
Let's start by setting the special tokens. bert-base-cased does not
have a decoder_start_token_id or eos_token_id, so we will use its
cls_token_id and sep_token_id respectively. Also, we should define a
pad_token_id on the config and make sure the correct vocab_size is
set.
bert2bert.config.decoder_start_token_id = tokenizer.cls_token_id
bert2bert.config.eos_token_id = tokenizer.sep_token_id
bert2bert.config.pad_token_id = tokenizer.pad_token_id
bert2bert.config.vocab_size = bert2bert.config.encoder.vocab_size
Next, let's define all parameters related to beam search decoding.
Since bart-large-cnn yields good results on CNN/Dailymail, we will
just copy its beam search decoding parameters.
For more details on what each of these parameters does, please take a look at this blog post or the docs.
bert2bert.config.max_length = 142
bert2bert.config.min_length = 56
bert2bert.config.no_repeat_ngram_size = 3
bert2bert.config.early_stopping = True
bert2bert.config.length_penalty = 2.0
bert2bert.config.num_beams = 4
Alright, let's now start fine-tuning the warm-started BERT2BERT model.
Fine-Tuning Warm-Started Encoder-Decoder Models
In this section, we will show how one can make use of the
Seq2SeqTrainer to fine-tune a warm-started encoder-decoder model.
Let's first import the Seq2SeqTrainer and its training arguments
Seq2SeqTrainingArguments.
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
In addition, we need a couple of python packages to make the
Seq2SeqTrainer work.
!pip install git-python==1.0.3
!pip install rouge_score
!pip install sacrebleu
The Seq2SeqTrainer extends 🤗Transformer's Trainer for encoder-decoder
models. In short, it allows using the generate(...) function during
evaluation, which is necessary to validate the performance of
encoder-decoder models on most sequence-to-sequence tasks, such as
summarization.
For more information on the Trainer, one should read through
this short
tutorial.
Let's begin by configuring the Seq2SeqTrainingArguments.
The argument predict_with_generate should be set to True, so that
the Seq2SeqTrainer runs the generate(...) on the validation data and
passes the generated output as predictions to the
compute_metric(...) function which we will define later. The
additional arguments are derived from TrainingArguments and can be
read upon
here.
For a complete training run, one should change those arguments as
needed. Good default values are commented out below.
For more information on the Seq2SeqTrainer, the reader is advised to
take a look at the
code.
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
evaluation_strategy="steps",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
fp16=True,
output_dir="./",
logging_steps=2,
save_steps=10,
eval_steps=4,
# logging_steps=1000,
# save_steps=500,
# eval_steps=7500,
# warmup_steps=2000,
# save_total_limit=3,
)
Also, we need to define a function to correctly compute the ROUGE score
during validation. Since we activated predict_with_generate, the
compute_metrics(...) function expects predictions that were obtained
using the generate(...) function. Like most summarization tasks,
CNN/Dailymail is typically evaluated using the ROUGE score.
Let's first load the ROUGE metric using the 🤗datasets library.
rouge = datasets.load_metric("rouge")
Next, we will define the compute_metrics(...) function. The rouge
metric computes the score from two lists of strings. Thus we decode both
the predictions and labels - making sure that -100 is correctly
replaced by the pad_token_id and remove all special characters by
setting skip_special_tokens=True.
def compute_metrics(pred):
labels_ids = pred.label_ids
pred_ids = pred.predictions
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_ids[labels_ids == -100] = tokenizer.pad_token_id
label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
rouge_output = rouge.compute(predictions=pred_str, references=label_str, rouge_types=["rouge2"])["rouge2"].mid
return {
"rouge2_precision": round(rouge_output.precision, 4),
"rouge2_recall": round(rouge_output.recall, 4),
"rouge2_fmeasure": round(rouge_output.fmeasure, 4),
}
Great, now we can pass all arguments to the Seq2SeqTrainer and start
finetuning. Executing the following cell will take ca. 10 minutes ☕.
Finetuning BERT2BERT on the complete CNN/Dailymail training data takes ca. model takes ca. 8h on a single TITAN RTX GPU.
# instantiate trainer
trainer = Seq2SeqTrainer(
model=bert2bert,
tokenizer=tokenizer,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_data,
eval_dataset=val_data,
)
trainer.train()
Awesome, we should now be fully equipped to finetune a warm-started encoder-decoder model. To check the result of our fine-tuning let's take a look at the saved checkpoints.
!ls
OUTPUT:
-------
bert2bert checkpoint-20 runs seq2seq_trainer.py
checkpoint-10 __pycache__ sample_data seq2seq_training_args.py
Finally, we can load the checkpoint as usual via the
EncoderDecoderModel.from_pretrained(...) method.
dummy_bert2bert = EncoderDecoderModel.from_pretrained("./checkpoint-20")
Evaluation
In a final step, we might want to evaluate the BERT2BERT model on the test data.
To start, instead of loading the dummy model, let's load a BERT2BERT
model that was finetuned on the full training dataset. Also, we load its
tokenizer, which is just a copy of bert-base-cased's tokenizer.
from transformers import BertTokenizer
bert2bert = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail").to("cuda")
tokenizer = BertTokenizer.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail")
Next, we load just 2% of CNN/Dailymail's test data. For the full evaluation, one should obviously use 100% of the data.
test_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="test[:2%]")
Now, we can again leverage 🤗dataset's handy map() function to
generate a summary for each test sample.
For each data sample we:
- first, tokenize the
"article", - second, generate the output token ids, and
- third, decode the output token ids to obtain our predicted summary.
def generate_summary(batch):
# cut off at BERT max length 512
inputs = tokenizer(batch["article"], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to("cuda")
attention_mask = inputs.attention_mask.to("cuda")
outputs = bert2bert.generate(input_ids, attention_mask=attention_mask)
output_str = tokenizer.batch_decode(outputs, skip_special_tokens=True)
batch["pred_summary"] = output_str
return batch
Let's run the map function to obtain the results dictionary that has the model's predicted summary stored for each sample. Executing the following cell may take ca. 10min ☕.
batch_size = 16 # change to 64 for full evaluation
results = test_data.map(generate_summary, batched=True, batch_size=batch_size, remove_columns=["article"])
Finally, we compute the ROUGE score.
rouge.compute(predictions=results["pred_summary"], references=results["highlights"], rouge_types=["rouge2"])["rouge2"].mid
OUTPUT:
-------
Score(precision=0.10389454113300968, recall=0.1564771201053348, fmeasure=0.12175271663717585)
That's it. We've shown how to warm-start a BERT2BERT model and fine-tune/evaluate it on the CNN/Dailymail dataset.
The fully trained BERT2BERT model is uploaded to the 🤗model hub under patrickvonplaten/bert2bert_cnn_daily_mail.
The model achieves a ROUGE-2 score of 18.22 on the full evaluation data, which is even a little better than reported in the paper.
For some summarization examples, the reader is advised to use the online inference API of the model, here.
Thanks a lot to Sascha Rothe, Shashi Narayan, and Aliaksei Severyn from Google Research, and Victor Sanh, Sylvain Gugger, and Thomas Wolf from 🤗Hugging Face for proof-reading and giving very much appreciated feedback.





