Bringing Open-Source Models to Spreadsheets 🚀





AI can help journalists do great things if only we can imagine how to use it. That’s why I created a simple but potentially useful tool: Hugging Face on Sheets, to bring open-source AI models into spreadsheets. The idea is to meet people where they are and help them use AI as a feature in a tool they are already comfortable with.
In the arsenal of journalists and other specialists in media organizations, spreadsheets are an essential tool—not only to manipulate numbers but also text. And when you think about it, it's a match made in heaven with AI since they are both tools designed to manipulate data.
This project germinated one day when I was sharing my wonder about AI with an economist friend at the playground (not necessarily the best place to brainstorm, I concede!). His thoughtful answer brought me back to Earth: "Yeah, AI is interesting. But as a PhD working in one of the most renowned statistical institutes, I can tell you we still do 95% of our work in spreadsheets."
Yet, AI fundamentally changes one thing: we can talk to the machine in our own language. Or, as Andrej Karpathy puts it, "The hottest new programming language is English". It can be challenging to talk to the spreadsheet, master the formulas, etc., something I've often observed when teaching data journalism to journalists and students.
Moreover, chatbots are consumer products, not necessarily the best tool for a specialized profession such as journalism. With spreadsheets, you can manipulate a lot of data, automate tasks, find needles in a haystack, and process datasets in a highly flexible and tailored way.
There are many advantages to using AI models in spreadsheets:
- No code required
- It's a commonly used tool in journalistic workflows
- You can manipulate various types of data: text, URLs, dates, numbers, images...
- You can chain prompts to define complex processes
- You can create reproducible and automated workflows
- Free usage within the rate limits of the API
I'm probably forgetting some other arguments; feel free to add yours in the comments ;)
To help unlock these benefits I created a script you can run in your Google Sheets as an add-on (I'm not a good coder, so I got some help from AI to help build it).
This tool opens up a lot of possibilities to interact with your data, and enables analytic tasks such as: Classification, extraction, data cleaning, summarization, named entity recognition, translation, regular expression formulas, removing personal info, and you name it! You can consider chaining prompts in various columns or adding a few-shot prompt to improve your results.
This script allows you to call the model of your choice among those that run on the free API for inference on Hugging Face, such as Meta Llama 3 8B and 70B, Mixtral 8x7B, etc. (see the complete list here). For more advanced uses, you can also set up your own inference endpoint and access a wider variety of models.
Next, let’s look at three specific use cases to see how Hugging Face on Sheets works in action.
You can find the Sheet for each of the examples here.
1. Classification

Let's combine business with pleasure and see if season 3 of The Bear is worth watching, based on critics aggregated by Rotten Tomatoes.
I imported them into a nicely structured table with author, publication, and critic columns (thanks to an importxml formula that is out of scope for this post). Then, I created a new column in my sheet to classify them with the following cell formula:
=HF(C2, "meta-llama/Meta-Llama-3-70B-Instruct", "Think step by step. 1. Classify this movie critic only by using these categories: 'positive', 'neutral', 'bad'. 2. Remove special characters, tags, and capital letters in your answer. 3. Clean the final result to answer with one word only.")
Here's the breakdown of the formula:
HFis the name of the formulaC2is the cell where the text of the critic is located- Then, I call the model
- And finally, my prompt.
You can see the result with these two examples:
- The Bear Season 3 feels like an overlong exercise in experimentation that doesn't fully pay off. Perhaps it would have benefitted from one of the non-negotiables Carmy preaches this season: Subtract. → bad
- The Bear still finds moments of transcendence in its characters’ pursuit of professional excellence and personal growth, yet the show remains more fallible than its rapturous acclaim may imply. → neutral
You might wonder why not write a simple prompt like 'classify this movie critic by using three categories.' It's a question of trial and error, but after three iterations of the prompt, I got a clean result. Pro tip: Ask an LLM to generate the prompt for you. It can sometimes be faster and better structured, and at the very least gives you a starting point for refining it further.
2. Extraction

To test how the tool performs with extraction tasks, I took a sample of the CNN Dailymail Dataset since it's well suited for journalistic tasks. This English-language dataset contains just over 300k unique news articles written by journalists at CNN and the Daily Mail.
As a first try, I wrote the following prompt:
=HF(A2, "meta-llama/Meta-Llama-3-70B-Instruct", "List every person mentioned in the text, separated by commas. Answer only with the list of names. Exclude special characters and tags.")
It worked okay, but several names were missing. Interestingly enough, I got better results by changing the wording to the following:
=HF(A2, "meta-llama/Meta-Llama-3-70B-Instruct", "Extract the name of every person mentioned in the text, separated by commas. Answer only with the list of names. Exclude special characters and tags.")
I also created another column "Daniel Radcliffe/Not Daniel Radcliffe" to ask the model if this name appears in the previously created column. The prompt was:
=HF(B2, "meta-llama/Meta-Llama-3-70B-Instruct", "Is 'Daniel Radcliffe' mentioned in the text? Think step by step. 1. Answer only with 'yes' or 'no' in lowercase. 2. Remove everything else in your answer (tags, special characters). Text: ")
You'll note that I end with "Text: " to make it explicit to the model that the text begins after this prompt. If we look under the hood, the line of code to call the prompt is the following:
const formattedPrompt = `<s> [INST] ${systemPrompt} ${prompt} [/INST] </s>`;
Which will translate to:
<s> [INST] Is 'Daniel Radcliffe' mentioned in the text? Think step by step. 1. Answer only with 'yes' or 'no' in lowercase. 2. Remove everything else in your answer (tags, special characters). Text: Daniel Radcliffe, Rudyard Kipling, Peter Shaffer, Harry Potter, Jack Kipling [/INST] </s>`
for the input sent to the model for the first cell.
As with any generative AI tool, you’ll have to iterate with the prompts to get them just right.
By the way, the default system prompt for this tool is the following:
'You are a helpful and honest assistant. Please, respond concisely and truthfully.’
If you write a new prompt, this system prompt will be automatically overridden. Depending on your use case, you can manually add it at the beginning of your new prompt. In my experiments, it sometimes improves the results, sometimes not.
3. Messy Data
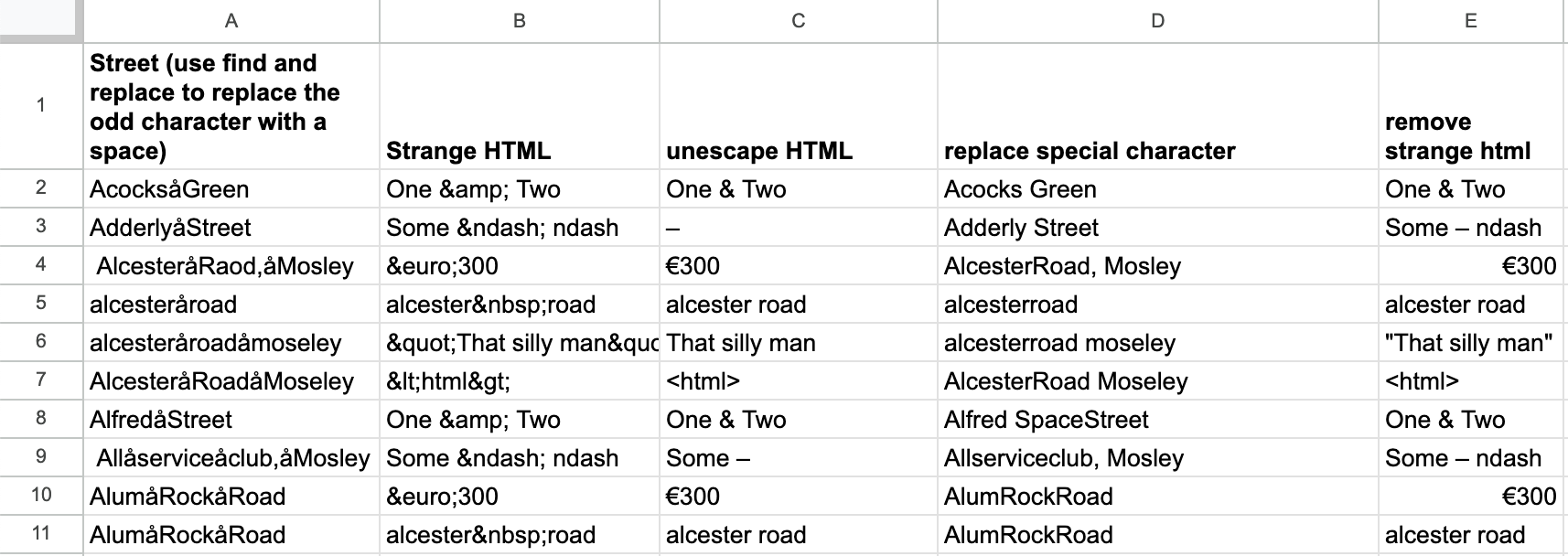
In his article "What is dirty data and how do I clean it? A great big guide for data journalists," Paul Bradshaw outlines a range of data issues often encountered in journalism including inaccuracy, incompleteness, inconsistency, and incompatibility. Could the Hugging Face on Sheets add-on help with some of these issues?
I gave it a try, and it performed well on cleaning strange HTML. It was also surprisingly good at removing a special character in a string, something LLMs sometimes struggle with (try asking your favorite model how many 'r' are in 'strawberry'). I also added an extra step to normalize the capitalization of the letters.
=HF(C9, "meta-llama/Meta-Llama-3-70B-Instruct", "You are a helpful assistant. I want you to remove all the characters 'å' in the following text. Think step by step: 1. Locate the characters 'å'. 2. Replace them with a space. 3. Capitalize the words. 4. Give the final answer only. Don't add any comments and remove special characters.")
Obviously, the range of data issues can vary a lot, but I think that this approach could be really powerful for data journalists looking to clean up and munge their data before doing more standard analyses.
The Open-Source Approach
This code is based on open-source models and is open-source itself, which means that everybody is free to use it, but also to contribute to it!
Since it launched, I've seen the power of the community with two interesting examples. Louis Brulé Naudet improved it by adding the possibility of selecting a model and a prompt located directly in cells instead of in the script, giving more flexibility to this tool. Nick Diakopoulos, the editor of this blog, spotted an error in the chain of prompts and [/INST] tag, significantly improving the results.
I recently saw another interesting example developed by Jonathan Soma, a journalism professor at Columbia. His example integrates specific task-oriented models on the Hugging Faces Hub instead of foundational ones for tasks such as zero-shot classification, token classification, summarization, or text-to-image.
How to Get Started with Hugging Faces for Sheets
To get started, you need to:
- Register or log in to Hugging Face
- Get your API key in your Hugging Face profile settings (it's free)
- Select fine-grained token > generate a token
- Copy your token
- Set permissions > select "Make calls to the serverless Inference API"
- You can also choose "Make calls to Inference Endpoints" if you plan to use dedicated endpoints.
Then, in your Google Sheets:
- Click on Extensions > Apps Scripts
- Replace the few existing lines of code with this script and save it.
- Back in the sheet, you should see a new tab called "Hugging Sheets".
- Click on it and add your API key.
- Voilà!
What's Next?
I can think of many possible improvements and invite you to contribute to this project!
- Adding task-oriented models such as summarization, image generation, translation, etc (see the full list of tasks here)
- Sharing exciting use cases and efficient prompts in the community tab of the project to help everyone use it. (Please share examples with me if you have ideas!)
- Publishing it as an official add-on in the Google Marketplace to make it easier to install. I've looked at the process, and it's unfortunately quite cumbersome!
Most importantly, let's imagine other tools together! I'm convinced that the news industry needs to take ownership of AI, develop products tailored to its needs, and foster the rise of AI builders instead of AI users.
So, feel free to reach out on LinkedIn and join the Journalists on Hugging Face community!
This piece originally ran on Generative AI in the Newsroom. Thanks to Nicholas Diakopoulos for the invitation to write it!
Florent Daudens is the Press Lead at Hugging Face, the open-source AI platform. He also teaches Digital Journalism at the Université de Montréal and provides newsroom training. He previously worked for more than 15 years in the media as a journalist and managing editor for Canadian newsrooms such as Le Devoir and CBC/Radio-Canada.