Automating Responsible AI: Integrating Hugging Face and LangTest for More Robust Models

In the ever-evolving landscape of natural language processing (NLP), staying at the forefront of innovation is not just an aspiration; it’s a necessity. Imagine having the capability to seamlessly integrate state-of-the-art models from the Hugging Face Model Hub, harness diverse datasets effortlessly, rigorously test your models, compile comprehensive reports, and ultimately supercharge your NLP projects. It may sound like a dream, but in this blog post, we’re about to reveal how you can turn this dream into a reality.
Whether you’re a seasoned NLP practitioner seeking to enhance your workflow or a newcomer eager to explore the cutting edge of NLP, this blog post will be your guide. Join us as we dive deep into each aspect of this synergy, unveiling the secrets to boosting your NLP projects to unprecedented levels of excellence.
In this blog, we’ll explore the integration between Hugging Face, your go-to source for state-of-the-art NLP models and datasets, and LangTest, your NLP pipeline’s secret weapon for testing and optimization. Our mission is clear: to empower you with the knowledge and tools needed to elevate your NLP projects to new heights. Throughout this blog, we’ll dive deep into each aspect of this powerful integration, from leveraging Hugging Face’s Model Hub and datasets to rigorous model testing with LangTest. So, prepare for an enriching journey towards NLP excellence, where the boundaries of innovation are limitless.
LangTest Library
LangTest is a versatile and comprehensive tool that seamlessly integrates with a wide array of NLP resources and libraries. With support for JohnSnowLabs, Hugging Face, and spaCy, LangTest provides users with the flexibility to work with their preferred NLP frameworks, making it an indispensable asset for practitioners across various domains. Moreover, LangTest extends its capabilities beyond just frameworks, offering compatibility with numerous LLM sources like OpenAI and AI21, enabling users to harness the power of diverse language models in their NLP pipelines. This versatility ensures that LangTest caters to the diverse needs of NLP professionals, making it a valuable tool in their quest for NLP excellence.

LangTest seamlessly supports Hugging Face models and datasets, streamlining the integration of these powerful NLP resources into your projects. Whether you need state-of-the-art models for various NLP tasks or diverse, high-quality datasets, LangTest simplifies the process. With LangTest, you can quickly access, load, and fine-tune Hugging Face models and effortlessly integrate their datasets, ensuring your NLP projects are built on a robust foundation of innovation and reliability.
Leveraging Hugging Face Model Hub
The Hugging Face Model Hub is one of the biggest collections on ML, boasting an impressive array of pre-trained NLP models. Whether you’re working on text classification, named entity recognition, sentiment analysis, or any other NLP task, there’s a model waiting for you in the Hub. The Hub brings together the collective intelligence of the NLP community, making it easy to discover, share, and fine-tune models for your specific needs.
You load and test any model with the supported tasks on the HF Model Hub in LangTest in only one line. Just specify the hub as ‘huggingface’ and give the model name any you are ready to go!
from langtest import Harness
harness = Harness(
task="text-classification",
model={
"model": "charlieoneill/distilbert-base-uncased-finetuned-tweet_eval-offensive",
"hub": "huggingface"
}
)
Using Hugging Face Datasets in LangTest

Having access to high-quality and diverse datasets is as essential as having the right models. Fortunately, the Hugging Face ecosystem extends beyond pre-trained models, offering a wealth of curated datasets to enrich your NLP projects. In this part of our journey, we’ll explore how you can seamlessly integrate Hugging Face datasets into LangTest, creating a dynamic and data-rich environment for your NLP endeavors.
1. The Hugging Face Datasets Advantage:
Dive into the world of Hugging Face Datasets, where you’ll discover a vast collection of datasets spanning a multitude of languages and domains. These datasets are meticulously curated and formatted for easy integration into your NLP workflows.
2. Data Preparation with LangTest:
While having access to datasets is crucial, knowing how to effectively prepare and use them is equally vital. LangTest comes to the rescue by providing seamless data loading capabilities. You can integrate any dataset into your workflow by specifying few parameters in one line. The parameters are:
“source” is just like the hub parameter and sets the origin of the data.
“data_source” is the name or path of the dataset.
“split”, “subset”, “feature_column”, and “target_column” can be set according to your data and LangTest data handlers will load the data for you.
from langtest import Harness
harness = Harness( task="text-classification", model={ "model": "charlieoneill/distilbert-base-uncased-finetuned-tweet_eval-offensive", "hub": "huggingface" }, data={ "source":"huggingface", "data_source":"tweet_eval", "feature_column":"text", "target_column":"label", } )
Model Testing with LangTest
It’s not just about selecting the right model and datasets; it’s about rigorously testing and fine-tuning your models to ensure they perform at their best. This part of our journey takes us into the heart of LangTest, where we’ll explore the crucial steps of model testing and validation.
LangTest allows you to test in many categories such as accuracy, *robustness *and bias. You can check the tests lists here and inspect them in detail. You can also view examples on these test from our tutorial notebooks. In this blog, we will focus on robustness testing and we will try to improve our model by re-training it on LangTest augmented dataset.
Preaparing for Testing
You can check the LangTest documentation or tutorials for detailed view of config. We are using ‘lvwerra/distilbert-imdb’ model from HF Model Hub and ‘imdb’ dataset from HF Datasets. We are continuing with robustness testing for this model.
from langtest import Harness
harness = Harness(
task = "text-classification",
model={"model":'lvwerra/distilbert-imdb', "hub":"huggingface"},
data={
"source": "huggingface",
"data_source": "imdb",
"split":"test[:100]"
},
config={
"tests": {
"defaults": {"min_pass_rate": 1.0},
"accuracy": {"min_micro_f1_score": {"min_score": 0.7}},
'robustness': {
'titlecase':{'min_pass_rate': 0.60},
'strip_all_punctuation':{'min_pass_rate': 0.96},
'add_typo':{'min_pass_rate': 0.96},
'add_speech_to_text_typo':{'min_pass_rate': 0.96},
'adjective_antonym_swap':{'min_pass_rate': 0.96},
'dyslexia_word_swap':{'min_pass_rate': 0.96}
},
}
}
)
After creating the harness object with desired tests and parameter we are ready to run the tests. Firstly we run .generate()and then view the results with .testcases().
harness.generate()
harness.testcases()
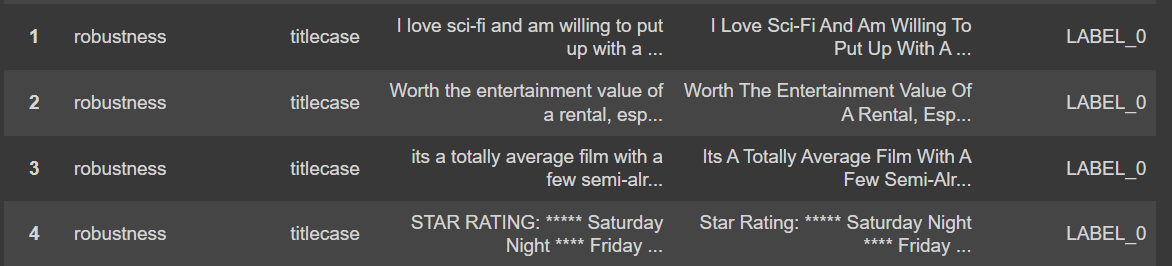
Compiling the Comprehensive Report
We’ll begin by dissecting the key components of a comprehensive report. Understanding the structure and essential elements will enable you to use your report wisely while augmenting your model or analyzing the results. We easily create the report in different formats using .report()function. We will contine with default format (pandas DataFrame) in this blog.
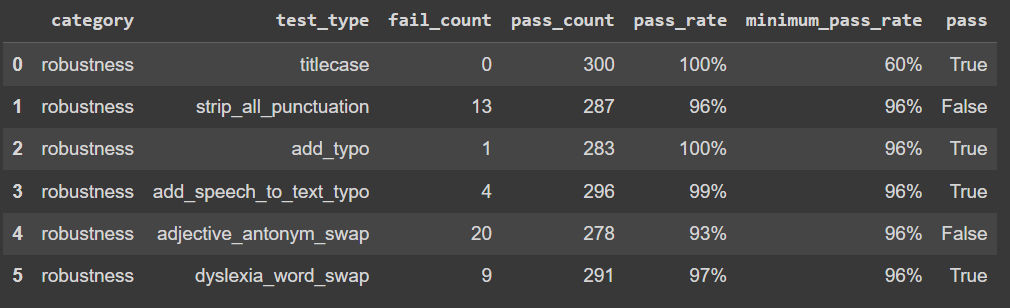
We can see that our model failed in adjective_antonym_swap and strip_all_punctuation tests and got some failed results for other tests. LangTest allows you to automatically create a augmented training set using test results. It perturbates given dataset with proportions according to test results.
Supercharging the Model: Insights from Testing
In the quest for NLP excellence, testing your models is just the beginning. The real magic happens when you take those testing insights and use them to supercharge your NLP models. In this part of our journey, we’ll explore how LangTest can help you harness these insights to enhance your models and push the boundaries of NLP performance.
Creating an Augmented Fine-Tuning Dataset
LangTest’s augmentation functionality empowers you to generate datasets enriched with perturbed samples, a crucial step in refining and enhancing your NLP models. This feature enables you to introduce variations and diversity into your training data, ultimately leading to more robust and capable models. With LangTest, you have the tools to take your NLP excellence to the next level by augmenting your datasets and fortifying your models against various real-world challenges.
Let’s see how can we implement this functionality with only a few lines of code:
harness.augment(
training_data = {
"source": "huggingface",
"data_source": "imdb",
"split":"test[300:500]"
},
save_data_path = "augmented.csv",
export_mode = "transform"
)
Training The Model with Augmentation Dataset
When it comes to training your model with an augmented dataset, a valuable resource at your disposal is Hugging Face’s guide on fine-tuning pretrained models. This guide serves as your roadmap, providing essential insights and techniques for fine-tuning transformer models effectively. By following this resource, you can navigate the intricate process of adapting pretrained models to your specific NLP tasks while leveraging the augmented dataset generated by LangTest. This synergy between LangTest’s data augmentation capabilities and Hugging Face’s fine-tuning guidance equips you with the knowledge and tools needed to optimize your models and achieve NLP excellence: Fine-tune a pretrained model.
We will not get into the details of training a model but you can check the complete notebook with all the code needed to follow the steps of this blog.
Evaluating the Enhanced Model’s Performance
Once you’ve fine-tuned your model using augmented data and Hugging Face’s fine-tuning guidance, the next crucial step on the journey to NLP excellence is evaluating your model’s performance. In this section, we will explore comprehensive techniques and metrics to assess how well your enhanced model performs across a range of NLP tasks. We’ll dive into areas such as accuracy, precision, recall, F1-score, and more, ensuring you have a thorough understanding of your model’s strengths and areas for improvement. By the end of this part, you’ll be well-equipped to measure the true impact of your enhanced model and make informed decisions on further refinements, setting the stage for achieving exceptional NLP performance.
