
Upload 41 files
Browse files- .gitattributes +2 -0
- LICENSE +201 -0
- README.md +64 -3
- __pycache__/dataset.cpython-39.pyc +0 -0
- __pycache__/detector.cpython-39.pyc +0 -0
- data.txt +0 -0
- data/.DS_Store +0 -0
- data/enron/enron_spam_data.csv +3 -0
- data/enron/preprocess.py +19 -0
- data/sms/sms_spam.csv +0 -0
- data/spam_message_test.csv +0 -0
- data/spam_message_train.csv +3 -0
- data/spam_message_val.csv +0 -0
- data/telegram/preprocess.py +16 -0
- data/telegram/telegram_spam_dataset.csv +0 -0
- data/utils/merge.py +21 -0
- data/utils/split.py +45 -0
- data/utils/visualize.py +31 -0
- dataset.py +35 -0
- demo.ipynb +230 -0
- detector.py +272 -0
- plots/confusion_matrix.png +0 -0
- plots/evaluate_metrics.txt +4 -0
- plots/test_set_distribution.jpg +0 -0
- plots/train_losses.txt +10 -0
- plots/train_set_distribution.jpg +0 -0
- plots/train_validation_loss.jpg +0 -0
- plots/val_accuracies.txt +10 -0
- plots/val_f1_scores.txt +10 -0
- plots/val_losses.txt +10 -0
- plots/val_precisions.txt +10 -0
- plots/val_recalls.txt +10 -0
- plots/val_set_distribution.jpg +0 -0
- plots/validation_accuracy.jpg +0 -0
- plots/validation_precision_recall.jpg +0 -0
- requirements.txt +6 -0
- utils/__pycache__/metrics.cpython-39.pyc +0 -0
- utils/__pycache__/plotting.cpython-39.pyc +0 -0
- utils/__pycache__/seed.cpython-39.pyc +0 -0
- utils/metrics.py +70 -0
- utils/plotting.py +61 -0
- utils/seed.py +12 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
data/enron/enron_spam_data.csv filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
data/spam_message_train.csv filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2023 Michael Shenoda. All rights reserved.
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,3 +1,64 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# RoBERTa based Spam Message Detection
|
| 2 |
+
Spam messages frequently carry malicious links or phishing attempts posing significant threats to both organizations and their users. By choosing our RoBERTa-based spam message detection system, organizations can greatly enhance their security infrastructure. Our system effectively detects and filters out spam messages, adding an extra layer of security that safeguards organizations against potential financial losses, legal consequences, and reputational harm.
|
| 3 |
+
|
| 4 |
+
## Dataset
|
| 5 |
+
The dataset is composed of messages labeled by ham or spam, merged from three data sources:
|
| 6 |
+
1. SMS Spam Collection https://www.kaggle.com/datasets/uciml/sms-spam-collection-dataset
|
| 7 |
+
2. Telegram Spam Ham https://huggingface.co/datasets/thehamkercat/telegram-spam-ham/tree/main
|
| 8 |
+
3. Enron Spam: https://huggingface.co/datasets/SetFit/enron_spam/tree/main (only used message column and labels)
|
| 9 |
+
|
| 10 |
+
The prepare script for enron is available at https://github.com/mshenoda/roberta-spam/tree/main/data/enron.
|
| 11 |
+
The data is split 80% train 10% validation, and 10% test sets; the scripts used to split and merge of the three data sources are available at: https://github.com/mshenoda/roberta-spam/tree/main/data/utils.
|
| 12 |
+
|
| 13 |
+
### Dataset Class Distribution
|
| 14 |
+
|
| 15 |
+
Training 80% | Validation 10% | Testing 10%
|
| 16 |
+
:-------------------------:|:-------------------------:|:-------------------------:
|
| 17 |
+
 Class Distribution |  Class Distribution |  Class Distribution
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
## Model Architecture
|
| 21 |
+
The model is fine tuned RoBERTa base
|
| 22 |
+
|
| 23 |
+
roberta-base: https://huggingface.co/roberta-base
|
| 24 |
+
|
| 25 |
+
paper: https://arxiv.org/abs/1907.11692
|
| 26 |
+
|
| 27 |
+
my model is hosted at huggingface
|
| 28 |
+
roberta-spam: https://huggingface.co/mshenoda/roberta-spam
|
| 29 |
+
|
| 30 |
+
## Metrics
|
| 31 |
+
Loss | Accuracy | Precision / Recall | Confusion Matrix
|
| 32 |
+
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
|
| 33 |
+
 Train / Validation |  Validation |  Validation |  Testing Set
|
| 34 |
+
|
| 35 |
+
## Required Packages
|
| 36 |
+
- numpy
|
| 37 |
+
- torch
|
| 38 |
+
- transformers
|
| 39 |
+
- pandas
|
| 40 |
+
- tqdm
|
| 41 |
+
- matplotlib
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
### Install
|
| 45 |
+
```
|
| 46 |
+
pip3 install -r requirements.txt
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
## Directory Structure
|
| 50 |
+
Place all the files in same directory as the following:
|
| 51 |
+
```
|
| 52 |
+
├─── data/ contains csv data files
|
| 53 |
+
├─── plots/ contains metrics results and plots
|
| 54 |
+
├─── roberta-spam trained model weights
|
| 55 |
+
├─── utils/ contains helper functions
|
| 56 |
+
├─── demo.ipynb jupyter notebook run the demo
|
| 57 |
+
├─── detector.py SpamMessageDetector with methods train, evaluate, detect
|
| 58 |
+
└─── dataset.py custom dataset class for spam messages
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
## Running Demo
|
| 62 |
+
To run the demo, please run the following Jupyter Notebook: demo.ipynb
|
| 63 |
+
|
| 64 |
+
** Recommend using VSCode https://code.visualstudio.com for running the demo notebook
|
__pycache__/dataset.cpython-39.pyc
ADDED
|
Binary file (1.45 kB). View file
|
|
|
__pycache__/detector.cpython-39.pyc
ADDED
|
Binary file (7.3 kB). View file
|
|
|
data.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
data/enron/enron_spam_data.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:009c86359b5bd6ec142a9b9ca85075ec864fd8c7c1c378c9a430e9427d0f7d57
|
| 3 |
+
size 51690056
|
data/enron/preprocess.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
|
| 3 |
+
# Read the CSV file
|
| 4 |
+
df = pd.read_csv('enron_spam_data.csv')
|
| 5 |
+
|
| 6 |
+
# Filter the desired columns
|
| 7 |
+
df_filtered = df[['Spam/Ham', 'Message']]
|
| 8 |
+
|
| 9 |
+
# Rename the column headers
|
| 10 |
+
df_filtered.rename(columns={'Spam/Ham': 'label', 'Message': 'text'}, inplace=True)
|
| 11 |
+
|
| 12 |
+
# Drop rows with empty message values
|
| 13 |
+
df_filtered.dropna(subset=['text'], inplace=True)
|
| 14 |
+
|
| 15 |
+
# Convert cells to a single line
|
| 16 |
+
df_filtered['text'] = df_filtered['text'].apply(lambda x: x.replace('\n', ' ') if isinstance(x, str) else x)
|
| 17 |
+
|
| 18 |
+
# Save the filtered and modified DataFrame to a new CSV file
|
| 19 |
+
df_filtered.to_csv('enron_spam.csv', index=False)
|
data/sms/sms_spam.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/spam_message_test.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/spam_message_train.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21974c720ffb7372806a9b90bc51b02f012b298271ed110a82cc38b85f9f3281
|
| 3 |
+
size 45108305
|
data/spam_message_val.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/telegram/preprocess.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import argparse
|
| 3 |
+
|
| 4 |
+
def remove_newlines(input_file, output_file):
|
| 5 |
+
df = pd.read_csv(input_file)
|
| 6 |
+
df = df.replace('\n', '', regex=True)
|
| 7 |
+
df.to_csv(output_file, index=False)
|
| 8 |
+
print("Newlines removed successfully!")
|
| 9 |
+
|
| 10 |
+
if __name__ == '__main__':
|
| 11 |
+
parser = argparse.ArgumentParser(description='Remove newlines from each row in a CSV file')
|
| 12 |
+
parser.add_argument('input', help='Input CSV file')
|
| 13 |
+
parser.add_argument('output', help='Output CSV file')
|
| 14 |
+
args = parser.parse_args()
|
| 15 |
+
|
| 16 |
+
remove_newlines(args.input, args.output)
|
data/telegram/telegram_spam_dataset.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/utils/merge.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import pandas as pd
|
| 3 |
+
|
| 4 |
+
def merge_csv(input_files, output_file):
|
| 5 |
+
dfs = []
|
| 6 |
+
for file in input_files:
|
| 7 |
+
df = pd.read_csv(file)
|
| 8 |
+
dfs.append(df)
|
| 9 |
+
|
| 10 |
+
merged_df = pd.concat(dfs)
|
| 11 |
+
merged_df.to_csv(output_file, index=False)
|
| 12 |
+
print("Merged CSV files saved successfully as", output_file)
|
| 13 |
+
|
| 14 |
+
if __name__ == "__main__":
|
| 15 |
+
# python merge_csv.py input1.csv input2.csv input3.csv output.csv
|
| 16 |
+
parser = argparse.ArgumentParser(description="Merge multiple CSV files into a single CSV output file.")
|
| 17 |
+
parser.add_argument("input_files", nargs="+", help="Input CSV files to merge")
|
| 18 |
+
parser.add_argument("output_file", help="Output CSV file")
|
| 19 |
+
args = parser.parse_args()
|
| 20 |
+
|
| 21 |
+
merge_csv(args.input_files, args.output_file)
|
data/utils/split.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import random
|
| 3 |
+
import math
|
| 4 |
+
import argparse
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
def split_dataset(filename, train_ratio):
|
| 8 |
+
df = pd.read_csv(filename)
|
| 9 |
+
|
| 10 |
+
# Shuffle the dataset
|
| 11 |
+
df = df.sample(frac=1, random_state=42).reset_index(drop=True)
|
| 12 |
+
|
| 13 |
+
train_size = math.floor(len(df) * train_ratio)
|
| 14 |
+
remaining_data = df.iloc[train_size:]
|
| 15 |
+
|
| 16 |
+
val_size = test_size = math.floor(len(remaining_data) / 2)
|
| 17 |
+
|
| 18 |
+
train_data = df.iloc[:train_size]
|
| 19 |
+
val_data = remaining_data.iloc[:val_size]
|
| 20 |
+
test_data = remaining_data.iloc[val_size:]
|
| 21 |
+
|
| 22 |
+
base_filename = os.path.splitext(os.path.basename(filename))[0]
|
| 23 |
+
output_dir = os.path.dirname(filename)
|
| 24 |
+
|
| 25 |
+
train_filename = os.path.join(output_dir, base_filename + '_train.csv')
|
| 26 |
+
val_filename = os.path.join(output_dir, base_filename + '_val.csv')
|
| 27 |
+
test_filename = os.path.join(output_dir, base_filename + '_test.csv')
|
| 28 |
+
|
| 29 |
+
train_data.to_csv(train_filename, index=False)
|
| 30 |
+
val_data.to_csv(val_filename, index=False)
|
| 31 |
+
test_data.to_csv(test_filename, index=False)
|
| 32 |
+
|
| 33 |
+
print("Dataset split completed.")
|
| 34 |
+
print("Train data saved as:", train_filename)
|
| 35 |
+
print("Validation data saved as:", val_filename)
|
| 36 |
+
print("Test data saved as:", test_filename)
|
| 37 |
+
|
| 38 |
+
if __name__ == '__main__':
|
| 39 |
+
parser = argparse.ArgumentParser(description='Split a CSV dataset into train, validation, and test sets.')
|
| 40 |
+
parser.add_argument('filename', type=str, help='the filename of the CSV dataset')
|
| 41 |
+
parser.add_argument('train_ratio', type=float, help='the split ratio for the train set')
|
| 42 |
+
|
| 43 |
+
args = parser.parse_args()
|
| 44 |
+
|
| 45 |
+
split_dataset(args.filename, args.train_ratio)
|
data/utils/visualize.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import matplotlib.pyplot as plt
|
| 4 |
+
|
| 5 |
+
def visualize_class_distribution(csv_file, class_column, title):
|
| 6 |
+
# Load the CSV dataset using pandas
|
| 7 |
+
df = pd.read_csv(csv_file)
|
| 8 |
+
|
| 9 |
+
# Count the occurrences of each class
|
| 10 |
+
class_counts = df[class_column].value_counts()
|
| 11 |
+
|
| 12 |
+
# Plot the class distribution
|
| 13 |
+
plt.figure(figsize=(10, 6))
|
| 14 |
+
class_counts.plot(kind='bar')
|
| 15 |
+
plt.title(title) #'Class Distribution'
|
| 16 |
+
plt.xlabel('Class')
|
| 17 |
+
plt.ylabel('Count')
|
| 18 |
+
plt.show()
|
| 19 |
+
|
| 20 |
+
if __name__ == "__main__":
|
| 21 |
+
# Create argument parser
|
| 22 |
+
parser = argparse.ArgumentParser(description='Visualize class distribution in a CSV file.')
|
| 23 |
+
parser.add_argument('csv_file', type=str, help='Path to the CSV file')
|
| 24 |
+
parser.add_argument('class_column', type=str, help='Name of the column containing class labels')
|
| 25 |
+
parser.add_argument('title', type=str, help='Plot Title')
|
| 26 |
+
|
| 27 |
+
# Parse command-line arguments
|
| 28 |
+
args = parser.parse_args()
|
| 29 |
+
|
| 30 |
+
# Call the visualization function
|
| 31 |
+
visualize_class_distribution(args.csv_file, args.class_column, args.title)
|
dataset.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils.data import Dataset
|
| 3 |
+
|
| 4 |
+
class SpamMessageDataset(Dataset):
|
| 5 |
+
def __init__(self, text, labels, tokenizer, max_length):
|
| 6 |
+
self.text = text
|
| 7 |
+
labels = [1 if label == 'spam' else 0 for label in labels]
|
| 8 |
+
self.labels = torch.tensor(labels, dtype=torch.long)
|
| 9 |
+
self.tokenizer = tokenizer
|
| 10 |
+
self.max_length = max_length
|
| 11 |
+
|
| 12 |
+
def __len__(self):
|
| 13 |
+
return len(self.text)
|
| 14 |
+
|
| 15 |
+
def __getitem__(self, idx):
|
| 16 |
+
text = str(self.text[idx])
|
| 17 |
+
label = self.labels[idx].clone().detach()
|
| 18 |
+
|
| 19 |
+
encoding = self.tokenizer.encode_plus(
|
| 20 |
+
text,
|
| 21 |
+
add_special_tokens=True,
|
| 22 |
+
max_length=self.max_length,
|
| 23 |
+
padding='max_length',
|
| 24 |
+
truncation=True,
|
| 25 |
+
return_tensors='pt'
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
input_ids = encoding['input_ids'].squeeze()
|
| 29 |
+
attention_mask = encoding['attention_mask'].squeeze()
|
| 30 |
+
|
| 31 |
+
return {
|
| 32 |
+
'input_ids': input_ids,
|
| 33 |
+
'attention_mask': attention_mask,
|
| 34 |
+
'label': label
|
| 35 |
+
}
|
demo.ipynb
ADDED
|
@@ -0,0 +1,230 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"attachments": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"### RoBERTa based Spam Message Detection"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "code",
|
| 13 |
+
"execution_count": 2,
|
| 14 |
+
"metadata": {},
|
| 15 |
+
"outputs": [],
|
| 16 |
+
"source": [
|
| 17 |
+
"from detector import SpamMessageDetector"
|
| 18 |
+
]
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"attachments": {},
|
| 22 |
+
"cell_type": "markdown",
|
| 23 |
+
"metadata": {},
|
| 24 |
+
"source": [
|
| 25 |
+
"#### Training roberta-spam model: to start training, set TRAIN=True, you may skip for Demo"
|
| 26 |
+
]
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"cell_type": "code",
|
| 30 |
+
"execution_count": 3,
|
| 31 |
+
"metadata": {},
|
| 32 |
+
"outputs": [],
|
| 33 |
+
"source": [
|
| 34 |
+
"TRAIN = False\n",
|
| 35 |
+
"if TRAIN:\n",
|
| 36 |
+
" spam_detector = SpamMessageDetector(\"roberta-base\", max_length=512, seed=0)\n",
|
| 37 |
+
" train_data_path = 'spam_message_train.csv'\n",
|
| 38 |
+
" val_data_path = 'spam_message_val.csv'\n",
|
| 39 |
+
" spam_detector.train(train_data_path, val_data_path, num_epochs=10, batch_size=32, learning_rate=2e-5)\n",
|
| 40 |
+
" model_path = 'roberta-spam'\n",
|
| 41 |
+
" spam_detector.save_model(model_path)"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"attachments": {},
|
| 46 |
+
"cell_type": "markdown",
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"source": [
|
| 49 |
+
"#### Training Results\n",
|
| 50 |
+
"\n",
|
| 51 |
+
"Loss | Accuracy | Precision / Recall \n",
|
| 52 |
+
":-------------------------:|:-------------------------:|:-------------------------: \n",
|
| 53 |
+
" Train / Validation |  Validation |  Validation\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"\n"
|
| 57 |
+
]
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"attachments": {},
|
| 61 |
+
"cell_type": "markdown",
|
| 62 |
+
"metadata": {},
|
| 63 |
+
"source": [
|
| 64 |
+
"#### Evaluating the roberta-spam model"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "code",
|
| 69 |
+
"execution_count": 4,
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"outputs": [],
|
| 72 |
+
"source": [
|
| 73 |
+
"spam_detector = SpamMessageDetector(\"mshenoda/roberta-spam\")\n",
|
| 74 |
+
"spam_detector.evaluate(\"data/spam_message_test.csv\")"
|
| 75 |
+
]
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"attachments": {},
|
| 79 |
+
"cell_type": "markdown",
|
| 80 |
+
"metadata": {},
|
| 81 |
+
"source": [
|
| 82 |
+
"#### Testing individual example messages"
|
| 83 |
+
]
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"cell_type": "code",
|
| 87 |
+
"execution_count": null,
|
| 88 |
+
"metadata": {},
|
| 89 |
+
"outputs": [
|
| 90 |
+
{
|
| 91 |
+
"ename": "NameError",
|
| 92 |
+
"evalue": "name 'spam_detector' is not defined",
|
| 93 |
+
"output_type": "error",
|
| 94 |
+
"traceback": [
|
| 95 |
+
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 96 |
+
"\u001b[0;31mNameError\u001b[0m Traceback (most recent call last)",
|
| 97 |
+
"Cell \u001b[0;32mIn[1], line 2\u001b[0m\n\u001b[1;32m 1\u001b[0m message1 \u001b[38;5;241m=\u001b[39m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mHey so this sat are we going for the intro pilates only? Or the kickboxing too?\u001b[39m\u001b[38;5;124m\"\u001b[39m\n\u001b[0;32m----> 2\u001b[0m detection \u001b[38;5;241m=\u001b[39m \u001b[43mspam_detector\u001b[49m\u001b[38;5;241m.\u001b[39mdetect(message1)\n\u001b[1;32m 4\u001b[0m \u001b[38;5;28mprint\u001b[39m(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;130;01m\\n\u001b[39;00m\u001b[38;5;124mExample 1\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[1;32m 5\u001b[0m \u001b[38;5;28mprint\u001b[39m(\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mInput Message: \u001b[39m\u001b[38;5;124m\"\u001b[39m, message1)\n",
|
| 98 |
+
"\u001b[0;31mNameError\u001b[0m: name 'spam_detector' is not defined"
|
| 99 |
+
]
|
| 100 |
+
}
|
| 101 |
+
],
|
| 102 |
+
"source": [
|
| 103 |
+
"message1 = \"Hey so this sat are we going for the intro pilates only? Or the kickboxing too?\"\n",
|
| 104 |
+
"detection = spam_detector.detect(message1)\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"print(\"\\nExample 1\")\n",
|
| 107 |
+
"print(\"Input Message: \", message1)\n",
|
| 108 |
+
"print(\"Detected Spam?: \", bool(detection))\n",
|
| 109 |
+
"\n",
|
| 110 |
+
"message2 = \"U have a secret admirer. REVEAL who thinks U R So special. Call 09065174042. To opt out Reply REVEAL STOP. 1.50 per msg recd.\"\n",
|
| 111 |
+
"detection = spam_detector.detect(message2)\n",
|
| 112 |
+
"\n",
|
| 113 |
+
"print(\"\\nExample 2\")\n",
|
| 114 |
+
"print(\"Input Message: \", message2)\n",
|
| 115 |
+
"print(\"Detected Spam: \", bool(detection))\n",
|
| 116 |
+
"\n",
|
| 117 |
+
"message3 = \"Dude im no longer a pisces. Im an aquarius now.\"\n",
|
| 118 |
+
"detection = spam_detector.detect(message3)\n",
|
| 119 |
+
"\n",
|
| 120 |
+
"print(\"\\nExample 3\")\n",
|
| 121 |
+
"print(\"Input Message: \", message3)\n",
|
| 122 |
+
"print(\"Detected Spam?: \", bool(detection))\n",
|
| 123 |
+
"\n",
|
| 124 |
+
"message4 = \"Great News! Call FREEFONE 08006344447 to claim your guaranteed $1000 CASH or $2000 gift. Speak to a live operator NOW!\"\n",
|
| 125 |
+
"detection = spam_detector.detect(message4)\n",
|
| 126 |
+
"\n",
|
| 127 |
+
"print(\"\\nExample 4 \")\n",
|
| 128 |
+
"print(\"Input Message: \", message4)\n",
|
| 129 |
+
"print(\"Detected Spam?: \", bool(detection))"
|
| 130 |
+
]
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"attachments": {},
|
| 134 |
+
"cell_type": "markdown",
|
| 135 |
+
"metadata": {},
|
| 136 |
+
"source": [
|
| 137 |
+
"#### Batch Processing is supported for processing multiple messages at once"
|
| 138 |
+
]
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"cell_type": "code",
|
| 142 |
+
"execution_count": null,
|
| 143 |
+
"metadata": {},
|
| 144 |
+
"outputs": [],
|
| 145 |
+
"source": [
|
| 146 |
+
"messages = [message1, message2, message3, message4]"
|
| 147 |
+
]
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"cell_type": "code",
|
| 151 |
+
"execution_count": null,
|
| 152 |
+
"metadata": {},
|
| 153 |
+
"outputs": [
|
| 154 |
+
{
|
| 155 |
+
"name": "stdout",
|
| 156 |
+
"output_type": "stream",
|
| 157 |
+
"text": [
|
| 158 |
+
"\n",
|
| 159 |
+
"Example 1\n",
|
| 160 |
+
"Input Message: Hey so this sat are we going for the intro pilates only? Or the kickboxing too?\n",
|
| 161 |
+
"detected spam: False\n",
|
| 162 |
+
"\n",
|
| 163 |
+
"Example 2\n",
|
| 164 |
+
"Input Message: U have a secret admirer. REVEAL who thinks U R So special. Call 09065174042. To opt out Reply REVEAL STOP. 1.50 per msg recd.\n",
|
| 165 |
+
"detected spam: True\n",
|
| 166 |
+
"\n",
|
| 167 |
+
"Example 3\n",
|
| 168 |
+
"Input Message: Dude im no longer a pisces. Im an aquarius now.\n",
|
| 169 |
+
"detected spam: False\n",
|
| 170 |
+
"\n",
|
| 171 |
+
"Example 4\n",
|
| 172 |
+
"Input Message: Great News! Call FREEFONE 08006344447 to claim your guaranteed $1000 CASH or $2000 gift. Speak to a live operator NOW!\n",
|
| 173 |
+
"detected spam: True\n"
|
| 174 |
+
]
|
| 175 |
+
}
|
| 176 |
+
],
|
| 177 |
+
"source": [
|
| 178 |
+
"\n",
|
| 179 |
+
"detections = spam_detector.detect(messages)\n",
|
| 180 |
+
"for i, message in enumerate(messages):\n",
|
| 181 |
+
" print(\"\\nExample \", f\"{i+1}\")\n",
|
| 182 |
+
" print(\"Input Message: \", message)\n",
|
| 183 |
+
" print(\"detected spam: \", bool(detections[i]))\n"
|
| 184 |
+
]
|
| 185 |
+
},
|
| 186 |
+
{
|
| 187 |
+
"cell_type": "code",
|
| 188 |
+
"execution_count": null,
|
| 189 |
+
"metadata": {},
|
| 190 |
+
"outputs": [],
|
| 191 |
+
"source": []
|
| 192 |
+
},
|
| 193 |
+
{
|
| 194 |
+
"cell_type": "code",
|
| 195 |
+
"execution_count": null,
|
| 196 |
+
"metadata": {},
|
| 197 |
+
"outputs": [],
|
| 198 |
+
"source": []
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"cell_type": "code",
|
| 202 |
+
"execution_count": null,
|
| 203 |
+
"metadata": {},
|
| 204 |
+
"outputs": [],
|
| 205 |
+
"source": []
|
| 206 |
+
}
|
| 207 |
+
],
|
| 208 |
+
"metadata": {
|
| 209 |
+
"kernelspec": {
|
| 210 |
+
"display_name": "Python 3",
|
| 211 |
+
"language": "python",
|
| 212 |
+
"name": "python3"
|
| 213 |
+
},
|
| 214 |
+
"language_info": {
|
| 215 |
+
"codemirror_mode": {
|
| 216 |
+
"name": "ipython",
|
| 217 |
+
"version": 3
|
| 218 |
+
},
|
| 219 |
+
"file_extension": ".py",
|
| 220 |
+
"mimetype": "text/x-python",
|
| 221 |
+
"name": "python",
|
| 222 |
+
"nbconvert_exporter": "python",
|
| 223 |
+
"pygments_lexer": "ipython3",
|
| 224 |
+
"version": "3.9.12"
|
| 225 |
+
},
|
| 226 |
+
"orig_nbformat": 4
|
| 227 |
+
},
|
| 228 |
+
"nbformat": 4,
|
| 229 |
+
"nbformat_minor": 2
|
| 230 |
+
}
|
detector.py
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import torch
|
| 3 |
+
from torch.utils.data import DataLoader, random_split
|
| 4 |
+
from transformers import RobertaTokenizer, RobertaForSequenceClassification, get_linear_schedule_with_warmup
|
| 5 |
+
from dataset import SpamMessageDataset
|
| 6 |
+
from utils.metrics import compute_metrics, confusion_matrix
|
| 7 |
+
from utils.plotting import plot_heatmap
|
| 8 |
+
from utils.seed import random_seed
|
| 9 |
+
|
| 10 |
+
import matplotlib.pyplot as plt
|
| 11 |
+
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
def save_list_to_file(lst, filename):
|
| 15 |
+
with open(filename, 'w') as file:
|
| 16 |
+
for item in lst:
|
| 17 |
+
file.write(str(item) + '\n')
|
| 18 |
+
|
| 19 |
+
class SpamMessageDetector:
|
| 20 |
+
def __init__(self, model_path, max_length=512, seed=0):
|
| 21 |
+
random_seed(seed)
|
| 22 |
+
self.seed = seed
|
| 23 |
+
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 24 |
+
self.tokenizer = RobertaTokenizer.from_pretrained(model_path)
|
| 25 |
+
self.model = RobertaForSequenceClassification.from_pretrained(model_path, num_labels=2)
|
| 26 |
+
self.model = self.model.to(self.device)
|
| 27 |
+
self.max_length = max_length
|
| 28 |
+
|
| 29 |
+
def train(self, train_data_path, val_data_path=None, num_epochs=5, batch_size=32, learning_rate=2e-5):
|
| 30 |
+
random_seed(self.seed)
|
| 31 |
+
|
| 32 |
+
if(val_data_path is None): # no validation dataset, split the given data
|
| 33 |
+
# Load and preprocess the training data
|
| 34 |
+
data = pd.read_csv(train_data_path)
|
| 35 |
+
text = data['text'].values
|
| 36 |
+
labels = data['label'].values
|
| 37 |
+
|
| 38 |
+
# Create the dataset
|
| 39 |
+
dataset = SpamMessageDataset(text, labels, self.tokenizer, max_length=self.max_length)
|
| 40 |
+
# Split the dataset into training and validation sets
|
| 41 |
+
train_size = int(0.8 * len(dataset))
|
| 42 |
+
val_size = len(dataset) - train_size
|
| 43 |
+
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
|
| 44 |
+
else:
|
| 45 |
+
# Load and preprocess the training data
|
| 46 |
+
train_data = pd.read_csv(train_data_path)
|
| 47 |
+
train_text = train_data['text'].values
|
| 48 |
+
train_labels = train_data['label'].values
|
| 49 |
+
train_dataset = SpamMessageDataset(train_text, train_labels, self.tokenizer, max_length=self.max_length)
|
| 50 |
+
val_data = pd.read_csv(train_data_path)
|
| 51 |
+
val_text = val_data['text'].values
|
| 52 |
+
val_labels = val_data['label'].values
|
| 53 |
+
val_dataset = SpamMessageDataset(val_text, val_labels, self.tokenizer, max_length=self.max_length)
|
| 54 |
+
|
| 55 |
+
# Create data loaders
|
| 56 |
+
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
|
| 57 |
+
val_loader = DataLoader(val_dataset, batch_size=batch_size)
|
| 58 |
+
|
| 59 |
+
# Define the optimizer
|
| 60 |
+
optimizer = torch.optim.AdamW(self.model.parameters(), lr=learning_rate)
|
| 61 |
+
total_steps = len(train_loader) * num_epochs
|
| 62 |
+
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=100, num_training_steps=total_steps)
|
| 63 |
+
|
| 64 |
+
# Fine-tuning loop
|
| 65 |
+
train_losses = list()
|
| 66 |
+
val_losses = list()
|
| 67 |
+
val_accuracies = list()
|
| 68 |
+
val_precisions = list()
|
| 69 |
+
val_recalls = list()
|
| 70 |
+
val_f1_scores = list()
|
| 71 |
+
|
| 72 |
+
for epoch in range(num_epochs):
|
| 73 |
+
self.model.train()
|
| 74 |
+
train_loss = 0.0
|
| 75 |
+
|
| 76 |
+
progress_bar = tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs}', leave=False)
|
| 77 |
+
for batch in progress_bar:
|
| 78 |
+
input_ids = batch['input_ids'].to(self.device)
|
| 79 |
+
attention_mask = batch['attention_mask'].to(self.device)
|
| 80 |
+
labels = batch['label'].to(self.device)
|
| 81 |
+
|
| 82 |
+
optimizer.zero_grad()
|
| 83 |
+
|
| 84 |
+
outputs = self.model(input_ids, attention_mask=attention_mask, labels=labels)
|
| 85 |
+
|
| 86 |
+
loss = outputs.loss
|
| 87 |
+
train_loss += loss.item()
|
| 88 |
+
|
| 89 |
+
loss.backward()
|
| 90 |
+
|
| 91 |
+
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1.0)
|
| 92 |
+
|
| 93 |
+
optimizer.step()
|
| 94 |
+
scheduler.step()
|
| 95 |
+
|
| 96 |
+
# Update the progress bar
|
| 97 |
+
progress_bar.set_postfix({'Training Loss': train_loss / (batch_size * (progress_bar.n + 1))})
|
| 98 |
+
|
| 99 |
+
train_loss /= len(train_loader)
|
| 100 |
+
train_losses.append(train_loss)
|
| 101 |
+
|
| 102 |
+
# Evaluation on the validation set
|
| 103 |
+
self.model.eval()
|
| 104 |
+
val_loss = 0.0
|
| 105 |
+
total_val_loss = 0.0
|
| 106 |
+
val_accuracy = 0.0
|
| 107 |
+
val_precision = 0.0
|
| 108 |
+
val_recall = 0.0
|
| 109 |
+
|
| 110 |
+
with torch.no_grad():
|
| 111 |
+
y_true = []
|
| 112 |
+
y_pred = []
|
| 113 |
+
|
| 114 |
+
for batch in val_loader:
|
| 115 |
+
input_ids = batch['input_ids'].to(self.device)
|
| 116 |
+
attention_mask = batch['attention_mask'].to(self.device)
|
| 117 |
+
labels = batch['label'].to(self.device)
|
| 118 |
+
|
| 119 |
+
outputs = self.model(input_ids, attention_mask=attention_mask, labels=labels)
|
| 120 |
+
|
| 121 |
+
loss = outputs.loss
|
| 122 |
+
logits = outputs.logits
|
| 123 |
+
total_val_loss += loss.item()
|
| 124 |
+
|
| 125 |
+
predictions = torch.argmax(logits, dim=1)
|
| 126 |
+
|
| 127 |
+
y_true.extend(labels.tolist())
|
| 128 |
+
y_pred.extend(predictions.tolist())
|
| 129 |
+
|
| 130 |
+
val_loss = total_val_loss / len(val_loader)
|
| 131 |
+
val_losses.append(val_loss)
|
| 132 |
+
val_accuracy, val_precision, val_recall, val_f1 = compute_metrics(y_true, y_pred, 1, 0)
|
| 133 |
+
val_precisions.append(val_precision)
|
| 134 |
+
val_recalls.append(val_recall)
|
| 135 |
+
val_f1_scores.append(val_f1)
|
| 136 |
+
val_accuracies.append(val_accuracy)
|
| 137 |
+
|
| 138 |
+
# Print the metrics and confusion matrix for each epoch
|
| 139 |
+
print(f'Epoch {epoch + 1}/{num_epochs} - Train Loss: {train_loss:.4f} - Val Loss: {val_loss:.4f} - Val Accuracy: {val_accuracy:.4f} - Val Precision: {val_precision:.4f} - Val Recall: {val_recall:.4f}')
|
| 140 |
+
|
| 141 |
+
# Plots data
|
| 142 |
+
save_list_to_file(train_losses, "plots/train_losses.txt")
|
| 143 |
+
save_list_to_file(val_losses, "plots/val_losses.txt")
|
| 144 |
+
save_list_to_file(val_accuracies, "plots/val_accuracies.txt")
|
| 145 |
+
save_list_to_file(val_precisions, "plots/val_precisions.txt")
|
| 146 |
+
save_list_to_file(val_recalls, "plots/val_recalls.txt")
|
| 147 |
+
save_list_to_file(val_f1_scores, "plots/val_f1_scores.txt")
|
| 148 |
+
|
| 149 |
+
# Plots
|
| 150 |
+
plt.figure(figsize=(10, 6))
|
| 151 |
+
plt.plot(train_losses, label='Training Loss')
|
| 152 |
+
plt.plot(val_losses, label='Validation Loss')
|
| 153 |
+
plt.xlabel('Epoch')
|
| 154 |
+
plt.ylabel('Loss')
|
| 155 |
+
plt.title('Training and Validation Loss')
|
| 156 |
+
plt.legend()
|
| 157 |
+
plt.savefig('plots/train_validation_loss.jpg')
|
| 158 |
+
|
| 159 |
+
plt.figure(figsize=(10, 6))
|
| 160 |
+
plt.plot(val_accuracies, label='Validation Accuracy')
|
| 161 |
+
plt.xlabel('Epoch')
|
| 162 |
+
plt.ylabel('Accuracy')
|
| 163 |
+
plt.title('Accuracy')
|
| 164 |
+
plt.legend()
|
| 165 |
+
plt.savefig('plots/validation_accuracy.jpg')
|
| 166 |
+
|
| 167 |
+
plt.figure(figsize=(10, 6))
|
| 168 |
+
plt.plot(val_precisions, label='Validation Precision')
|
| 169 |
+
plt.plot(val_recalls, label='Validation Recall')
|
| 170 |
+
plt.xlabel('Epoch')
|
| 171 |
+
plt.ylabel('Precision / Recall')
|
| 172 |
+
plt.title('Precision / Recall')
|
| 173 |
+
plt.legend()
|
| 174 |
+
plt.savefig('plots/validation_precision_recall.jpg')
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
def evaluate(self, dataset_path):
|
| 178 |
+
random_seed(self.seed)
|
| 179 |
+
|
| 180 |
+
# Load and preprocess the dataset
|
| 181 |
+
dataset = pd.read_csv(dataset_path)
|
| 182 |
+
texts = dataset["text"].tolist()
|
| 183 |
+
labels = dataset["label"].tolist()
|
| 184 |
+
|
| 185 |
+
def preprocess(text):
|
| 186 |
+
inputs = self.tokenizer.encode_plus(
|
| 187 |
+
text,
|
| 188 |
+
add_special_tokens=True,
|
| 189 |
+
max_length=self.max_length,
|
| 190 |
+
padding="longest",
|
| 191 |
+
truncation=True,
|
| 192 |
+
return_tensors="pt"
|
| 193 |
+
)
|
| 194 |
+
return inputs["input_ids"].to(self.device), inputs["attention_mask"].to(self.device)
|
| 195 |
+
|
| 196 |
+
inputs = [preprocess(text) for text in texts]
|
| 197 |
+
|
| 198 |
+
# Make predictions on the dataset
|
| 199 |
+
predictions = []
|
| 200 |
+
with torch.no_grad():
|
| 201 |
+
for input_ids, attention_mask in inputs:
|
| 202 |
+
outputs = self.model(input_ids=input_ids, attention_mask=attention_mask)
|
| 203 |
+
logits = outputs.logits
|
| 204 |
+
predicted_label = torch.argmax(logits, dim=1).item()
|
| 205 |
+
if predicted_label == 0:
|
| 206 |
+
predictions.append("ham")
|
| 207 |
+
else:
|
| 208 |
+
predictions.append("spam")
|
| 209 |
+
|
| 210 |
+
# compute evaluation metrics
|
| 211 |
+
accuracy, precision, recall, f1 = compute_metrics(labels, predictions)
|
| 212 |
+
|
| 213 |
+
# Create confusion matrix
|
| 214 |
+
cm = confusion_matrix(labels, predictions)
|
| 215 |
+
labels_sorted = sorted(set(labels))
|
| 216 |
+
|
| 217 |
+
# Print evaluation metrics
|
| 218 |
+
print(f"Accuracy: {accuracy:.4f}")
|
| 219 |
+
print(f"Precision: {precision:.4f}")
|
| 220 |
+
print(f"Recall: {recall:.4f}")
|
| 221 |
+
print(f"F1 Score: {f1:.4f}")
|
| 222 |
+
|
| 223 |
+
# Plot the confusion matrix
|
| 224 |
+
plot_heatmap(cm, saveToFile="plots/confusion_matrix.png", annot=True, fmt="d", cmap="Blues", xticklabels=labels_sorted, yticklabels=labels_sorted)
|
| 225 |
+
|
| 226 |
+
def detect(self, text):
|
| 227 |
+
random_seed(self.seed)
|
| 228 |
+
is_str = True
|
| 229 |
+
if isinstance(text, str):
|
| 230 |
+
encoded_input = self.tokenizer.encode_plus(
|
| 231 |
+
text,
|
| 232 |
+
add_special_tokens=True,
|
| 233 |
+
max_length=self.max_length,
|
| 234 |
+
padding='max_length',
|
| 235 |
+
truncation=True,
|
| 236 |
+
return_tensors='pt'
|
| 237 |
+
)
|
| 238 |
+
elif isinstance(text, list):
|
| 239 |
+
is_str = False
|
| 240 |
+
encoded_input = self.tokenizer.batch_encode_plus(
|
| 241 |
+
text,
|
| 242 |
+
add_special_tokens=True,
|
| 243 |
+
max_length=self.max_length,
|
| 244 |
+
padding='max_length',
|
| 245 |
+
truncation=True,
|
| 246 |
+
return_tensors='pt'
|
| 247 |
+
)
|
| 248 |
+
else:
|
| 249 |
+
raise Exception("text type is unsupported, needs to be str or list(str)")
|
| 250 |
+
|
| 251 |
+
input_ids = encoded_input['input_ids'].to(self.device)
|
| 252 |
+
attention_mask = encoded_input['attention_mask'].to(self.device)
|
| 253 |
+
|
| 254 |
+
with torch.no_grad():
|
| 255 |
+
outputs = self.model(input_ids, attention_mask=attention_mask)
|
| 256 |
+
|
| 257 |
+
logits = outputs.logits
|
| 258 |
+
predicted_labels = torch.argmax(logits, dim=1).tolist()
|
| 259 |
+
|
| 260 |
+
if is_str:
|
| 261 |
+
return predicted_labels[0]
|
| 262 |
+
else:
|
| 263 |
+
return predicted_labels
|
| 264 |
+
|
| 265 |
+
def save_model(self, model_path):
|
| 266 |
+
self.model.save_pretrained(model_path)
|
| 267 |
+
self.tokenizer.save_pretrained(model_path)
|
| 268 |
+
|
| 269 |
+
def load_model(self, model_path):
|
| 270 |
+
self.model = RobertaForSequenceClassification.from_pretrained(model_path)
|
| 271 |
+
self.tokenizer = RobertaTokenizer.from_pretrained(model_path)
|
| 272 |
+
self.model = self.model.to(self.device)
|
plots/confusion_matrix.png
ADDED

|
plots/evaluate_metrics.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Accuracy: 0.9906
|
| 2 |
+
Precision: 0.9971
|
| 3 |
+
Recall: 0.9934
|
| 4 |
+
F1 Score: 0.9953
|
plots/test_set_distribution.jpg
ADDED

|
plots/train_losses.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0.11079490562241555
|
| 2 |
+
0.03817119520373899
|
| 3 |
+
0.019643469863645176
|
| 4 |
+
0.012463655557059031
|
| 5 |
+
0.007619202447094255
|
| 6 |
+
0.005367153772241598
|
| 7 |
+
0.004059059033329212
|
| 8 |
+
0.002393396928800571
|
| 9 |
+
0.0013649824395344915
|
| 10 |
+
0.00037574244409310114
|
plots/train_set_distribution.jpg
ADDED
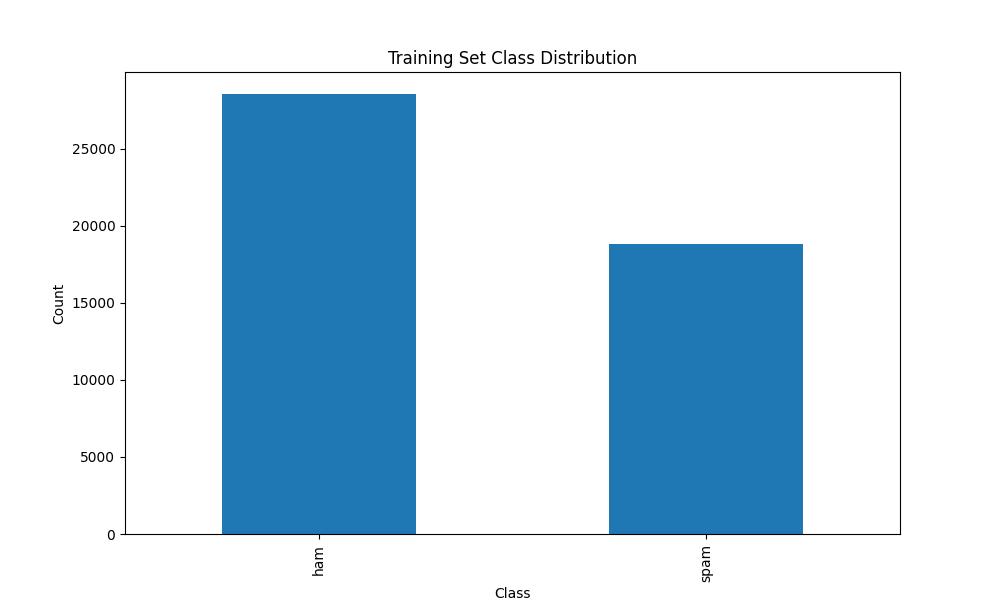
|
plots/train_validation_loss.jpg
ADDED

|
plots/val_accuracies.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0.9907790344361918
|
| 2 |
+
0.9958642808912896
|
| 3 |
+
0.9983963538149899
|
| 4 |
+
0.99957798784605
|
| 5 |
+
0.9995568872383525
|
| 6 |
+
0.999873396353815
|
| 7 |
+
0.99974679270763
|
| 8 |
+
0.9995146860229575
|
| 9 |
+
0.9999366981769074
|
| 10 |
+
0.999957798784605
|
plots/val_f1_scores.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0.9953681622097152
|
| 2 |
+
0.9979278555419291
|
| 3 |
+
0.9991975334713012
|
| 4 |
+
0.9997889493900638
|
| 5 |
+
0.9997783945210683
|
| 6 |
+
0.999936694169533
|
| 7 |
+
0.9998733803233022
|
| 8 |
+
0.9997572841147729
|
| 9 |
+
0.9999683480866419
|
| 10 |
+
0.9999788989470575
|
plots/val_losses.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0.03377506204298776
|
| 2 |
+
0.015607017114440963
|
| 3 |
+
0.005994615025463167
|
| 4 |
+
0.0013713277104528685
|
| 5 |
+
0.0014678094177459848
|
| 6 |
+
0.0005342433599496928
|
| 7 |
+
0.0011275661014885257
|
| 8 |
+
0.0027363823080638686
|
| 9 |
+
0.0001856036334957234
|
| 10 |
+
0.00012277685194798154
|
plots/val_precisions.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0.9982779147886726
|
| 2 |
+
0.9991320363274552
|
| 3 |
+
0.9996408425411446
|
| 4 |
+
0.9998311523849726
|
| 5 |
+
0.9997467446130469
|
| 6 |
+
0.9998944947352872
|
| 7 |
+
0.9999366861532617
|
| 8 |
+
0.9999577800764181
|
| 9 |
+
0.9999577978941149
|
| 10 |
+
0.999957798784605
|
plots/val_recalls.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0.9924753228636046
|
| 2 |
+
0.9967265738843952
|
| 3 |
+
0.998754617414248
|
| 4 |
+
0.9997467499577917
|
| 5 |
+
0.9998100464330941
|
| 6 |
+
0.9999788971658894
|
| 7 |
+
0.999810082508599
|
| 8 |
+
0.9995568685376661
|
| 9 |
+
0.9999788985017937
|
| 10 |
+
1.0
|
plots/val_set_distribution.jpg
ADDED

|
plots/validation_accuracy.jpg
ADDED

|
plots/validation_precision_recall.jpg
ADDED

|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
tqdm
|
| 2 |
+
matplotlib
|
| 3 |
+
numpy
|
| 4 |
+
pandas
|
| 5 |
+
torch
|
| 6 |
+
transformers
|
utils/__pycache__/metrics.cpython-39.pyc
ADDED
|
Binary file (1.88 kB). View file
|
|
|
utils/__pycache__/plotting.cpython-39.pyc
ADDED
|
Binary file (1.76 kB). View file
|
|
|
utils/__pycache__/seed.cpython-39.pyc
ADDED
|
Binary file (567 Bytes). View file
|
|
|
utils/metrics.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
def compute_metrics(y_true, y_pred, positive_label="spam", negative_label="ham"):
|
| 4 |
+
"""
|
| 5 |
+
Compute evaluation metrics for binary classification.
|
| 6 |
+
|
| 7 |
+
Parameters:
|
| 8 |
+
y_true (array-like): True labels.
|
| 9 |
+
y_pred (array-like): Predicted labels.
|
| 10 |
+
positive_label (optional): Value representing the positive label. Default is 1.
|
| 11 |
+
negative_label (optional): Value representing the negative label. Default is 0.
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
accuracy (float): Accuracy metric.
|
| 15 |
+
precision (float): Precision metric.
|
| 16 |
+
recall (float): Recall metric.
|
| 17 |
+
f1 (float): F1-score metric.
|
| 18 |
+
"""
|
| 19 |
+
y_true = np.array(y_true)
|
| 20 |
+
y_pred = np.array(y_pred)
|
| 21 |
+
|
| 22 |
+
# Calculate accuracy
|
| 23 |
+
accuracy = np.mean(y_true == y_pred)
|
| 24 |
+
|
| 25 |
+
# Calculate true positives, false positives, and false negatives
|
| 26 |
+
tp = np.sum(y_true == y_pred) # Count where true positive (both true and predicted labels are the same)
|
| 27 |
+
fp = np.sum((y_true != y_pred) & (y_pred == positive_label)) # Count where false positive (true label is negative, but predicted as positive)
|
| 28 |
+
fn = np.sum((y_true != y_pred) & (y_pred == negative_label)) # Count where false negative (true label is positive, but predicted as negative)
|
| 29 |
+
|
| 30 |
+
# Calculate precision, recall, and F1-score
|
| 31 |
+
precision = tp / (tp + fp)
|
| 32 |
+
recall = tp / (tp + fn)
|
| 33 |
+
f1 = 2 * (precision * recall) / (precision + recall)
|
| 34 |
+
|
| 35 |
+
return accuracy, precision, recall, f1
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def confusion_matrix(y_true, y_pred):
|
| 39 |
+
"""
|
| 40 |
+
Calculates the confusion matrix based on the ground truth and predicted labels.
|
| 41 |
+
|
| 42 |
+
Parameters:
|
| 43 |
+
y_true (list): The ground truth labels.
|
| 44 |
+
y_pred (list): The predicted labels.
|
| 45 |
+
|
| 46 |
+
Returns:
|
| 47 |
+
list of lists: The confusion matrix.
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
# Obtain the unique classes from y_true and y_pred
|
| 51 |
+
classes = list(set(y_true + y_pred))
|
| 52 |
+
classes.sort()
|
| 53 |
+
|
| 54 |
+
# Calculate the total number of unique classes
|
| 55 |
+
num_classes = len(classes)
|
| 56 |
+
|
| 57 |
+
# Initialize the confusion matrix as a 2D list of zeros
|
| 58 |
+
cm = [[0] * num_classes for _ in range(num_classes)]
|
| 59 |
+
|
| 60 |
+
# Iterate over each pair of true and predicted labels
|
| 61 |
+
for true, pred in zip(y_true, y_pred):
|
| 62 |
+
# Find the indices of true and predicted classes in the classes list
|
| 63 |
+
true_idx = classes.index(true)
|
| 64 |
+
pred_idx = classes.index(pred)
|
| 65 |
+
|
| 66 |
+
# Increment the corresponding cell in the confusion matrix
|
| 67 |
+
cm[true_idx][pred_idx] += 1
|
| 68 |
+
|
| 69 |
+
# Return the confusion matrix
|
| 70 |
+
return cm
|
utils/plotting.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
from matplotlib.colors import Normalize
|
| 4 |
+
|
| 5 |
+
def plot_heatmap(cm, saveToFile=None, annot=True, fmt="d", cmap="Blues", xticklabels=None, yticklabels=None):
|
| 6 |
+
"""
|
| 7 |
+
Plots a heatmap of the confusion matrix.
|
| 8 |
+
|
| 9 |
+
Parameters:
|
| 10 |
+
cm (list of lists): The confusion matrix.
|
| 11 |
+
annot (bool): Whether to annotate the heatmap with the cell values. Default is True.
|
| 12 |
+
fmt (str): The format specifier for cell value annotations. Default is "d" (integer).
|
| 13 |
+
cmap (str): The colormap for the heatmap. Default is "Blues".
|
| 14 |
+
xticklabels (list): Labels for the x-axis ticks. Default is None.
|
| 15 |
+
yticklabels (list): Labels for the y-axis ticks. Default is None.
|
| 16 |
+
|
| 17 |
+
Returns:
|
| 18 |
+
None
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
# Convert the confusion matrix to a NumPy array
|
| 22 |
+
cm = np.array(cm)
|
| 23 |
+
|
| 24 |
+
# Create a figure and axis for the heatmap
|
| 25 |
+
fig, ax = plt.subplots()
|
| 26 |
+
|
| 27 |
+
# Plot the heatmap
|
| 28 |
+
im = ax.imshow(cm, cmap=cmap)
|
| 29 |
+
|
| 30 |
+
# Display cell values as annotations
|
| 31 |
+
if annot:
|
| 32 |
+
# Normalize the colormap to get values between 0 and 1
|
| 33 |
+
norm = Normalize(vmin=cm.min(), vmax=cm.max())
|
| 34 |
+
for i in range(len(cm)):
|
| 35 |
+
for j in range(len(cm[i])):
|
| 36 |
+
value = cm[i, j]
|
| 37 |
+
# Determine text color based on cell value
|
| 38 |
+
text_color = 'white' if norm(value) > 0.5 else 'black'
|
| 39 |
+
text = ax.text(j, i, format(value, fmt), ha="center", va="center", color=text_color)
|
| 40 |
+
|
| 41 |
+
# Set x-axis and y-axis ticks and labels
|
| 42 |
+
if xticklabels:
|
| 43 |
+
ax.set_xticks(np.arange(len(xticklabels)))
|
| 44 |
+
ax.set_xticklabels(xticklabels)
|
| 45 |
+
if yticklabels:
|
| 46 |
+
ax.set_yticks(np.arange(len(yticklabels)))
|
| 47 |
+
ax.set_yticklabels(yticklabels)
|
| 48 |
+
|
| 49 |
+
# Set labels and title
|
| 50 |
+
ax.set_xlabel("Predicted")
|
| 51 |
+
ax.set_ylabel("True")
|
| 52 |
+
ax.set_title("Confusion Matrix Heatmap")
|
| 53 |
+
|
| 54 |
+
# Add a colorbar
|
| 55 |
+
cbar = ax.figure.colorbar(im, ax=ax)
|
| 56 |
+
|
| 57 |
+
# Show the plot
|
| 58 |
+
if(saveToFile is not None):
|
| 59 |
+
plt.savefig(saveToFile)
|
| 60 |
+
|
| 61 |
+
plt.show()
|
utils/seed.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
def random_seed(seed: int) -> None:
|
| 6 |
+
"""Set random seed for reproducibility."""
|
| 7 |
+
random.seed(seed)
|
| 8 |
+
np.random.seed(seed)
|
| 9 |
+
torch.manual_seed(seed)
|
| 10 |
+
torch.cuda.manual_seed_all(seed)
|
| 11 |
+
torch.backends.cudnn.deterministic = True
|
| 12 |
+
torch.backends.cudnn.benchmark = False
|