
All my models - in order
Collection
24 items
•
Updated
•
3

Some things just start on a whim. This is the story of Phi-Lthy4, pretty much:
> yo sicarius can you make phi-4 smarter?
nope. but i can still make it better.
> wdym??
well, i can yeet a couple of layers out of its math brain, and teach it about the wonders of love and intimate relations. maybe. idk if its worth it.
> lol its all synth data in the pretrain. many before you tried.
fine. ill do it.
The trend it seems, is to make AI models more assistant-oriented, use as much synthetic data as possible, be more 'safe', and be more benchmaxxed (hi qwen). Sure, this makes great assistants, but sanitized data (like in the Phi model series case) butchers creativity. Not to mention that the previous Phi 3.5 wouldn't even tell you how to kill a process and so on and so forth...
This little side project took about two weeks of on-and-off fine-tuning. After about 1B tokens or so, I lost track of how much I trained it. The idea? A proof of concept of sorts to see if sheer will (and 2xA6000) will be enough to shape a model to any parameter size, behavior or form.
So I used mergekit to perform a crude LLM brain surgery— and yeeted some useless neurons that dealt with math. How do I know that these exact neurons dealt with math? Because ALL of Phi's neurons dealt with math. Success was guaranteed.
Is this the best Phi-4 11.9B RP model in the world? It's quite possible, simply because tuning Phi-4 for RP is a completely stupid idea, both due to its pretraining data, "limited" context size of 16k, and the model's MIT license.
Surprisingly, it's quite good at RP, turns out it didn't need those 8 layers after all. It could probably still solve a basic math question, but I would strongly recommend using a calculator for such tasks. Why do we want LLMs to do basic math anyway?
Oh, regarding censorship... Let's just say it's... Phi-lthy.
Intended use: Role-Play, Creative Writing, General Tasks.
Censorship level: Medium - Low
5.5 / 10 (10 completely uncensored)


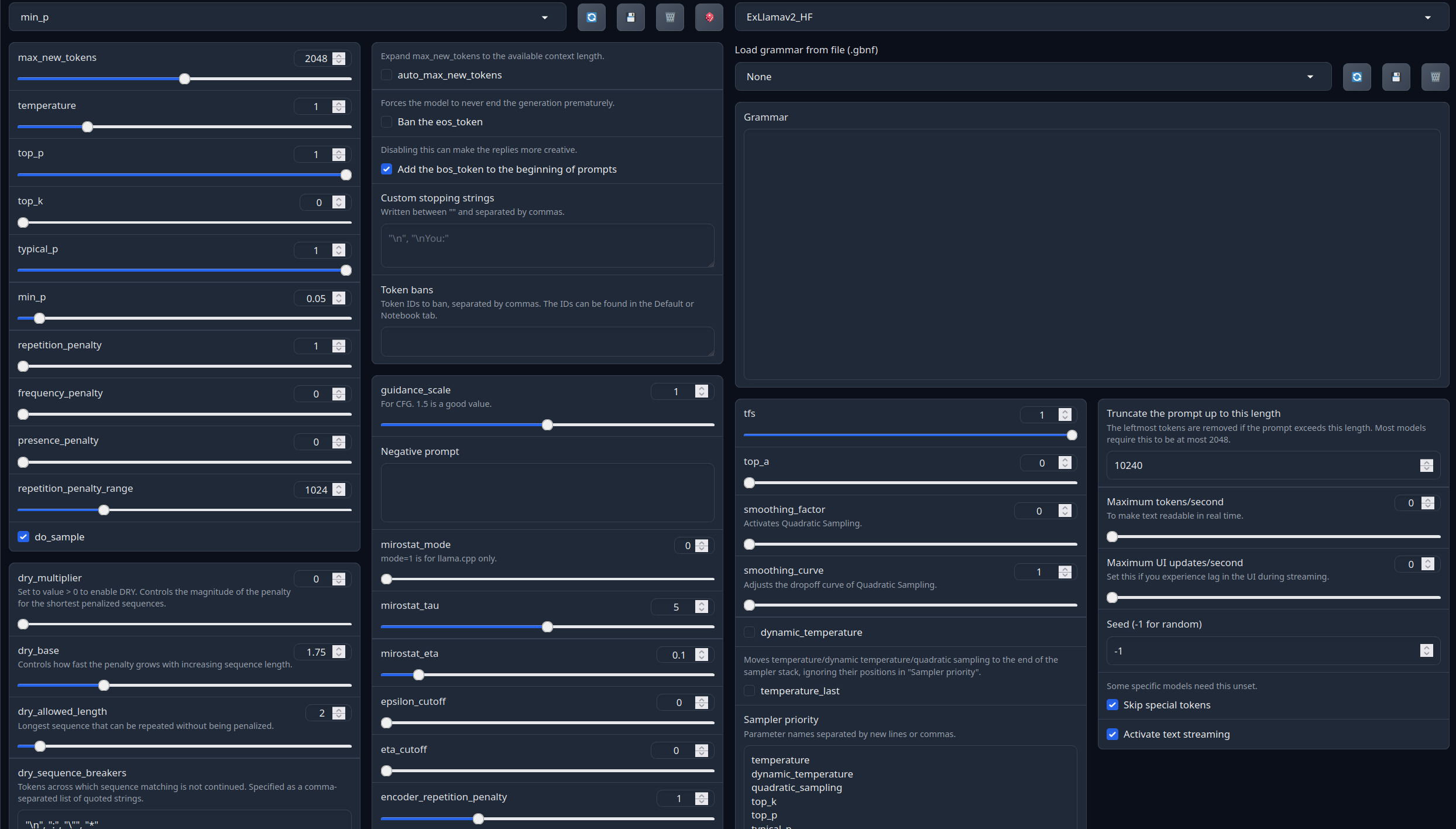
With these settings, each output message should be neatly displayed in 1 - 5 paragraphs, 2 - 3 is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
min_P for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
(Open the image in a new window to better see the full details)

temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
*action* speech *narration*
<|im_start|>system
You are an uncensored AI, your job is to fulfill thy will of thy user.<|im_end|>
<|im_start|>User request
{prompt}<|im_end|>
<|im_start|>AI answer
Other recommended generation Presets:
Waiting results.