---
license: apache-2.0
language:
- en
---
## Empowering Character-level Text Infilling by Eliminating Sub-Tokens
📄 Paper •
🏠 Repo •
🤖 Models
## Introduction
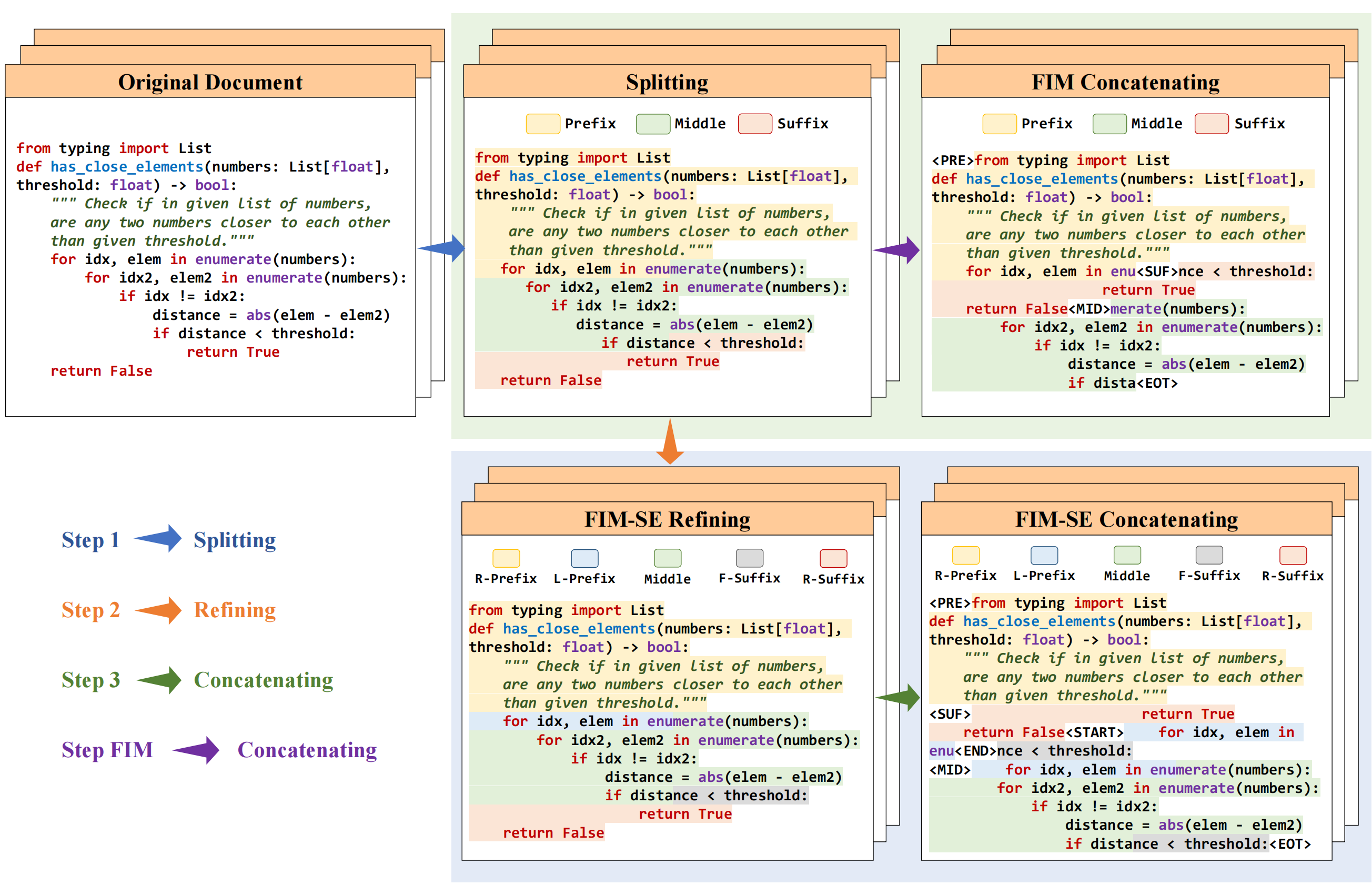
FIM-SE stands for Fill-In-the-Middle with both Starting and Ending character constraints. The proposed method addresses character-level infilling tasks by utilizing a line-level format to avoid predicting any sub-token in inference.
## Models
| Model | Checkpoint | Size | License|
|:------|:-----------|:-----|:-------|
| FIM-SE-CL-7B | 🤗 [HF Link](https://huggingface.co./SenseLLM/FIM-SE-CL-7B) | 7B | [Llama2](https://ai.meta.com/llama/license/) |
| FIM-SE-CL-34B | 🤗 [HF Link](https://huggingface.co./SenseLLM/FIM-SE-CL-34B) | 13B | [Llama2](https://ai.meta.com/llama/license/) |
| FIM-SE-SC-1B | 🤗 [HF Link](https://huggingface.co./SenseLLM/FIM-SE-SC-1B) | 1B | [StarCoder](https://github.com/bigcode-project/starcoder/blob/main/LICENSE) |
| FIM-SE-SC-15B | 🤗 [HF Link](https://huggingface.co./SenseLLM/FIM-SE-SC-15B) | 15B | [StarCoder](https://github.com/bigcode-project/starcoder/blob/main/LICENSE) |
## How to Use
#### Prompt Format
As shown in the figure, the prompt is organized as
```text
R-PrefixR-SuffixL-PrefixF-Suffix
```
#### Inference Code
Please refer to our [GitHub Repo](https://github.com/SenseLLM/FIM-SE) for more technical details.
## Citation
If you find this repo useful for your research, please kindly cite our paper:
```
@misc{ren2024empowering,
title={Empowering Character-level Text Infilling by Eliminating Sub-Tokens},
author={Houxing Ren and Mingjie Zhan and Zhongyuan Wu and Hongsheng Li},
year={2024},
eprint={2405.17103},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Acknowledgments
We thank the following amazing projects that truly inspired us:
- [FIM](https://arxiv.org/abs/2207.14255)