---
license: apache-2.0
datasets:
- REILX/neo_sft_phase2_conversations
- REILX/neo_sft_phase2_multi
- REILX/neo_sft_phase2_single
language:
- en
- zh
pipeline_tag: text-generation
tags:
- text-generation-inference
- qwen
- chat
- sft
- conversational
- lora
---
### 基础模型:
https://huggingface.co./Qwen/Qwen2-7B-Instruct
### 数据集
以 m-a-p/neo_sft_phase2 数据集为基石,构建了三个子数据集,分别如下:
1. REILX/neo_sft_phase2_conversations
2. REILX/neo_sft_phase2_multi
3. REILX/neo_sft_phase2_single
### 数据集构建规则
**REILX/neo_sft_phase2_conversations**
* **方法:** 将每轮对话视作独立的问答对,融入上下文信息构建样本。
* **具体步骤:**
1. 针对每个“conversation”,逐一遍历其对话轮次。
2. 将当前“human”轮次的“value”与之前所有轮次的对话内容拼接,构成完整的“instruction”。
3. 将当前“gpt”轮次的“value”作为最终的“output”。
4. “input”可为空白,亦可注入适当的提示信息。
**REILX/neo_sft_phase2_multi**
* **方法:** 将每轮对话视作独立的问答对,利用上下文信息构建样本。
* **具体步骤:**
1. 针对每个“conversation”,逐一遍历其对话轮次。
2. 将每个“conversation”中所有“human”的“value”拼接,构成完整的“instruction”。
3. 将每个“conversation”中所有“gpt”的“value”拼接,构成最终的“output”。
4. “input”可为空白,亦可注入适当的提示信息。
**REILX/neo_sft_phase2_single**
* **具体步骤:**
1. 针对每个“conversation”,逐一遍历其对话轮次。
2. 仅保留包含一轮对话的“conversation”,舍弃多轮对话数据。
3. 将该“conversation”的“human”的“value”作为“instruction”。
4. 将该“conversation”的“gpt”的“value”作为“output”。
5. “input”可为空白,亦可注入适当的提示信息。
### 训练参数
REILX/neo_sft_phase2_conversations
- learning_rate: 5e-06
- train_batch_size: 1
- eval_batch_size: 8
- cutoff_len:8192
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
REILX/neo_sft_phase2_multi
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- cutoff_len:8192
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
REILX/neo_sft_phase2_single
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- cutoff_len:4096
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
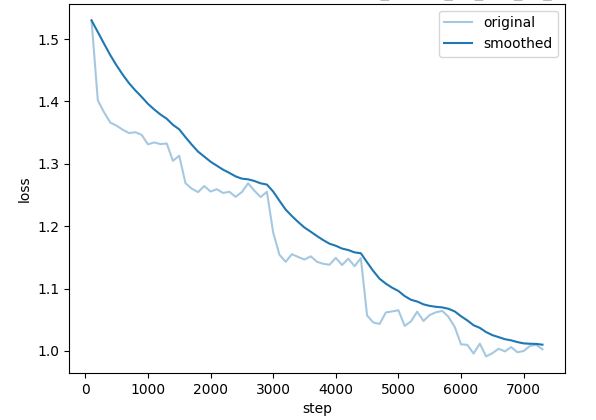
### 损失图
REILX/neo_sft_phase2_conversations
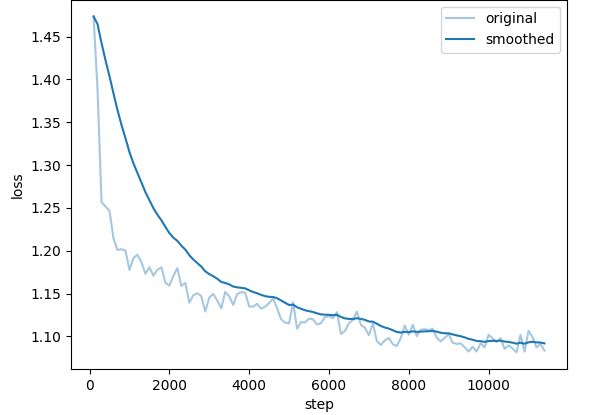 REILX/neo_sft_phase2_multi
REILX/neo_sft_phase2_multi
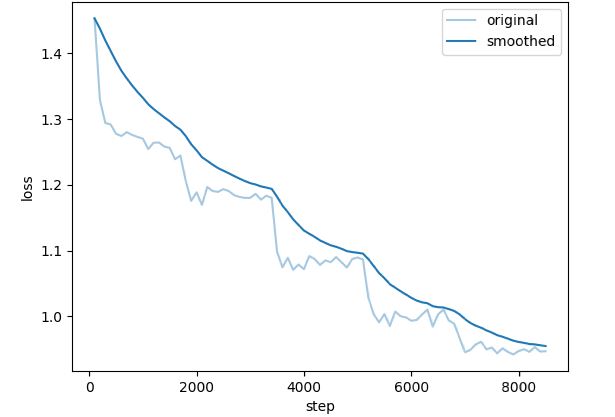 REILX/neo_sft_phase2_single
REILX/neo_sft_phase2_single