
Commit
·
524f2f8
1
Parent(s):
c171fe2
changes
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- Path/.gitattributes +35 -0
- Path/README.md +3 -0
- Path/causal_video_vae/config.json +92 -0
- Path/causal_video_vae/diffusion_pytorch_model.safetensors +3 -0
- Path/diffusion_transformer_384p/config.json +20 -0
- Path/diffusion_transformer_384p/diffusion_pytorch_model.safetensors +3 -0
- Path/diffusion_transformer_768p/config.json +20 -0
- Path/diffusion_transformer_768p/diffusion_pytorch_model.safetensors +3 -0
- Path/text_encoder/config.json +24 -0
- Path/text_encoder/model.safetensors +3 -0
- Path/text_encoder_2/config.json +24 -0
- Path/text_encoder_2/model.safetensors +3 -0
- Path/text_encoder_3/config.json +31 -0
- Path/text_encoder_3/model-00001-of-00002.safetensors +3 -0
- Path/text_encoder_3/model-00002-of-00002.safetensors +3 -0
- Path/text_encoder_3/model.safetensors.index.json +226 -0
- Path/tokenizer/merges.txt +0 -0
- Path/tokenizer/special_tokens_map.json +30 -0
- Path/tokenizer/tokenizer_config.json +30 -0
- Path/tokenizer/vocab.json +0 -0
- Path/tokenizer_2/merges.txt +0 -0
- Path/tokenizer_2/special_tokens_map.json +30 -0
- Path/tokenizer_2/tokenizer_config.json +38 -0
- Path/tokenizer_2/vocab.json +0 -0
- Path/tokenizer_3/special_tokens_map.json +125 -0
- Path/tokenizer_3/spiece.model +3 -0
- Path/tokenizer_3/tokenizer.json +0 -0
- Path/tokenizer_3/tokenizer_config.json +940 -0
- annotation/image_text.jsonl +20 -0
- annotation/video_text.jsonl +17 -0
- app.py +356 -0
- app_multigpu.py +143 -0
- assets/motivation.jpg +0 -0
- assets/the_great_wall.jpg +0 -0
- assets/user_study.jpg +0 -0
- assets/vbench.jpg +0 -0
- causal_video_vae_demo.ipynb +221 -0
- dataset/__init__.py +12 -0
- dataset/bucket_loader.py +148 -0
- dataset/dataloaders.py +190 -0
- dataset/dataset_cls.py +377 -0
- diffusion_schedulers/__init__.py +2 -0
- diffusion_schedulers/scheduling_cosine_ddpm.py +137 -0
- diffusion_schedulers/scheduling_flow_matching.py +297 -0
- docs/DiT.md +54 -0
- docs/VAE.md +43 -0
- image_generation_demo.ipynb +123 -0
- inference_multigpu.py +123 -0
- pyramid_dit/__init__.py +3 -0
- pyramid_dit/flux_modules/__init__.py +3 -0
Path/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
Path/README.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
---
|
Path/causal_video_vae/config.json
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "CausalVideoVAE",
|
| 3 |
+
"_diffusers_version": "0.29.2",
|
| 4 |
+
"add_post_quant_conv": true,
|
| 5 |
+
"decoder_act_fn": "silu",
|
| 6 |
+
"decoder_block_dropout": [
|
| 7 |
+
0.0,
|
| 8 |
+
0.0,
|
| 9 |
+
0.0,
|
| 10 |
+
0.0
|
| 11 |
+
],
|
| 12 |
+
"decoder_block_out_channels": [
|
| 13 |
+
128,
|
| 14 |
+
256,
|
| 15 |
+
512,
|
| 16 |
+
512
|
| 17 |
+
],
|
| 18 |
+
"decoder_in_channels": 16,
|
| 19 |
+
"decoder_layers_per_block": [
|
| 20 |
+
3,
|
| 21 |
+
3,
|
| 22 |
+
3,
|
| 23 |
+
3
|
| 24 |
+
],
|
| 25 |
+
"decoder_norm_num_groups": 32,
|
| 26 |
+
"decoder_out_channels": 3,
|
| 27 |
+
"decoder_spatial_up_sample": [
|
| 28 |
+
true,
|
| 29 |
+
true,
|
| 30 |
+
true,
|
| 31 |
+
false
|
| 32 |
+
],
|
| 33 |
+
"decoder_temporal_up_sample": [
|
| 34 |
+
true,
|
| 35 |
+
true,
|
| 36 |
+
true,
|
| 37 |
+
false
|
| 38 |
+
],
|
| 39 |
+
"decoder_type": "causal_vae_conv",
|
| 40 |
+
"decoder_up_block_types": [
|
| 41 |
+
"UpDecoderBlockCausal3D",
|
| 42 |
+
"UpDecoderBlockCausal3D",
|
| 43 |
+
"UpDecoderBlockCausal3D",
|
| 44 |
+
"UpDecoderBlockCausal3D"
|
| 45 |
+
],
|
| 46 |
+
"downsample_scale": 8,
|
| 47 |
+
"encoder_act_fn": "silu",
|
| 48 |
+
"encoder_block_dropout": [
|
| 49 |
+
0.0,
|
| 50 |
+
0.0,
|
| 51 |
+
0.0,
|
| 52 |
+
0.0
|
| 53 |
+
],
|
| 54 |
+
"encoder_block_out_channels": [
|
| 55 |
+
128,
|
| 56 |
+
256,
|
| 57 |
+
512,
|
| 58 |
+
512
|
| 59 |
+
],
|
| 60 |
+
"encoder_double_z": true,
|
| 61 |
+
"encoder_down_block_types": [
|
| 62 |
+
"DownEncoderBlockCausal3D",
|
| 63 |
+
"DownEncoderBlockCausal3D",
|
| 64 |
+
"DownEncoderBlockCausal3D",
|
| 65 |
+
"DownEncoderBlockCausal3D"
|
| 66 |
+
],
|
| 67 |
+
"encoder_in_channels": 3,
|
| 68 |
+
"encoder_layers_per_block": [
|
| 69 |
+
2,
|
| 70 |
+
2,
|
| 71 |
+
2,
|
| 72 |
+
2
|
| 73 |
+
],
|
| 74 |
+
"encoder_norm_num_groups": 32,
|
| 75 |
+
"encoder_out_channels": 16,
|
| 76 |
+
"encoder_spatial_down_sample": [
|
| 77 |
+
true,
|
| 78 |
+
true,
|
| 79 |
+
true,
|
| 80 |
+
false
|
| 81 |
+
],
|
| 82 |
+
"encoder_temporal_down_sample": [
|
| 83 |
+
true,
|
| 84 |
+
true,
|
| 85 |
+
true,
|
| 86 |
+
false
|
| 87 |
+
],
|
| 88 |
+
"encoder_type": "causal_vae_conv",
|
| 89 |
+
"interpolate": false,
|
| 90 |
+
"sample_size": 256,
|
| 91 |
+
"scaling_factor": 0.13025
|
| 92 |
+
}
|
Path/causal_video_vae/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c3e46120712f14a7e8a010264294754c113677085bab2b6cf051f1758cab238e
|
| 3 |
+
size 1341638684
|
Path/diffusion_transformer_384p/config.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "PyramidDiffusionMMDiT",
|
| 3 |
+
"_diffusers_version": "0.30.0",
|
| 4 |
+
"attention_head_dim": 64,
|
| 5 |
+
"caption_projection_dim": 1536,
|
| 6 |
+
"in_channels": 16,
|
| 7 |
+
"joint_attention_dim": 4096,
|
| 8 |
+
"max_num_frames": 200,
|
| 9 |
+
"num_attention_heads": 24,
|
| 10 |
+
"num_layers": 24,
|
| 11 |
+
"patch_size": 2,
|
| 12 |
+
"pooled_projection_dim": 2048,
|
| 13 |
+
"pos_embed_max_size": 192,
|
| 14 |
+
"pos_embed_type": "sincos",
|
| 15 |
+
"qk_norm": "rms_norm",
|
| 16 |
+
"sample_size": 128,
|
| 17 |
+
"use_flash_attn": false,
|
| 18 |
+
"use_gradient_checkpointing": false,
|
| 19 |
+
"use_temporal_causal": true
|
| 20 |
+
}
|
Path/diffusion_transformer_384p/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:59eeee86ade2c2765a6703e628c81e09b7c5e7191775aa80c5fb552313cc33be
|
| 3 |
+
size 8339919144
|
Path/diffusion_transformer_768p/config.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "PyramidDiffusionMMDiT",
|
| 3 |
+
"_diffusers_version": "0.30.0",
|
| 4 |
+
"attention_head_dim": 64,
|
| 5 |
+
"caption_projection_dim": 1536,
|
| 6 |
+
"in_channels": 16,
|
| 7 |
+
"joint_attention_dim": 4096,
|
| 8 |
+
"max_num_frames": 200,
|
| 9 |
+
"num_attention_heads": 24,
|
| 10 |
+
"num_layers": 24,
|
| 11 |
+
"patch_size": 2,
|
| 12 |
+
"pooled_projection_dim": 2048,
|
| 13 |
+
"pos_embed_max_size": 192,
|
| 14 |
+
"pos_embed_type": "sincos",
|
| 15 |
+
"qk_norm": "rms_norm",
|
| 16 |
+
"sample_size": 128,
|
| 17 |
+
"use_flash_attn": false,
|
| 18 |
+
"use_gradient_checkpointing": false,
|
| 19 |
+
"use_temporal_causal": true
|
| 20 |
+
}
|
Path/diffusion_transformer_768p/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7262ac5271e549ea87b8b05610663f16cf490eec19f525d4e2709c929cf52665
|
| 3 |
+
size 8339919144
|
Path/text_encoder/config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"CLIPTextModelWithProjection"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 0,
|
| 7 |
+
"dropout": 0.0,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "quick_gelu",
|
| 10 |
+
"hidden_size": 768,
|
| 11 |
+
"initializer_factor": 1.0,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 3072,
|
| 14 |
+
"layer_norm_eps": 1e-05,
|
| 15 |
+
"max_position_embeddings": 77,
|
| 16 |
+
"model_type": "clip_text_model",
|
| 17 |
+
"num_attention_heads": 12,
|
| 18 |
+
"num_hidden_layers": 12,
|
| 19 |
+
"pad_token_id": 1,
|
| 20 |
+
"projection_dim": 768,
|
| 21 |
+
"torch_dtype": "float16",
|
| 22 |
+
"transformers_version": "4.41.2",
|
| 23 |
+
"vocab_size": 49408
|
| 24 |
+
}
|
Path/text_encoder/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:71e183d11db0c6b6282a4d9e0abb74125edc8692393e89ed8ee5571005f35cb1
|
| 3 |
+
size 247323896
|
Path/text_encoder_2/config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"CLIPTextModelWithProjection"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 0,
|
| 7 |
+
"dropout": 0.0,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "gelu",
|
| 10 |
+
"hidden_size": 1280,
|
| 11 |
+
"initializer_factor": 1.0,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 5120,
|
| 14 |
+
"layer_norm_eps": 1e-05,
|
| 15 |
+
"max_position_embeddings": 77,
|
| 16 |
+
"model_type": "clip_text_model",
|
| 17 |
+
"num_attention_heads": 20,
|
| 18 |
+
"num_hidden_layers": 32,
|
| 19 |
+
"pad_token_id": 1,
|
| 20 |
+
"projection_dim": 1280,
|
| 21 |
+
"torch_dtype": "float16",
|
| 22 |
+
"transformers_version": "4.41.2",
|
| 23 |
+
"vocab_size": 49408
|
| 24 |
+
}
|
Path/text_encoder_2/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec310df2af79c318e24d20511b601a591ca8cd4f1fce1d8dff822a356bcdb1f4
|
| 3 |
+
size 1389382176
|
Path/text_encoder_3/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"T5EncoderModel"
|
| 4 |
+
],
|
| 5 |
+
"classifier_dropout": 0.0,
|
| 6 |
+
"d_ff": 10240,
|
| 7 |
+
"d_kv": 64,
|
| 8 |
+
"d_model": 4096,
|
| 9 |
+
"decoder_start_token_id": 0,
|
| 10 |
+
"dense_act_fn": "gelu_new",
|
| 11 |
+
"dropout_rate": 0.1,
|
| 12 |
+
"eos_token_id": 1,
|
| 13 |
+
"feed_forward_proj": "gated-gelu",
|
| 14 |
+
"initializer_factor": 1.0,
|
| 15 |
+
"is_encoder_decoder": true,
|
| 16 |
+
"is_gated_act": true,
|
| 17 |
+
"layer_norm_epsilon": 1e-06,
|
| 18 |
+
"model_type": "t5",
|
| 19 |
+
"num_decoder_layers": 24,
|
| 20 |
+
"num_heads": 64,
|
| 21 |
+
"num_layers": 24,
|
| 22 |
+
"output_past": true,
|
| 23 |
+
"pad_token_id": 0,
|
| 24 |
+
"relative_attention_max_distance": 128,
|
| 25 |
+
"relative_attention_num_buckets": 32,
|
| 26 |
+
"tie_word_embeddings": false,
|
| 27 |
+
"torch_dtype": "float16",
|
| 28 |
+
"transformers_version": "4.41.2",
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"vocab_size": 32128
|
| 31 |
+
}
|
Path/text_encoder_3/model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f2751ceeb2a96edd693e539dc5d6bba0b8d3814f49a9b3798403a0cec4b2e3d
|
| 3 |
+
size 4994582104
|
Path/text_encoder_3/model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f63154532130422309532ff56f11945fbea8266c958e3133e8e5aef85c6293c7
|
| 3 |
+
size 4530066248
|
Path/text_encoder_3/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 9524621312
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"encoder.block.0.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 7 |
+
"encoder.block.0.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"encoder.block.0.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 9 |
+
"encoder.block.0.layer.0.SelfAttention.relative_attention_bias.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"encoder.block.0.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 11 |
+
"encoder.block.0.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 13 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 14 |
+
"encoder.block.0.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"encoder.block.0.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"encoder.block.1.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 17 |
+
"encoder.block.1.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"encoder.block.1.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 19 |
+
"encoder.block.1.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"encoder.block.1.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 21 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 23 |
+
"encoder.block.1.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"encoder.block.1.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"encoder.block.10.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"encoder.block.10.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 27 |
+
"encoder.block.10.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"encoder.block.10.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 29 |
+
"encoder.block.10.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 31 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"encoder.block.10.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 33 |
+
"encoder.block.10.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"encoder.block.11.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 35 |
+
"encoder.block.11.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"encoder.block.11.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 37 |
+
"encoder.block.11.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"encoder.block.11.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 39 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 41 |
+
"encoder.block.11.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"encoder.block.11.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 43 |
+
"encoder.block.12.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"encoder.block.12.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 45 |
+
"encoder.block.12.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"encoder.block.12.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 47 |
+
"encoder.block.12.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 48 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 49 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 50 |
+
"encoder.block.12.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 51 |
+
"encoder.block.12.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 52 |
+
"encoder.block.13.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 53 |
+
"encoder.block.13.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 54 |
+
"encoder.block.13.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 55 |
+
"encoder.block.13.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 56 |
+
"encoder.block.13.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 57 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 58 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 59 |
+
"encoder.block.13.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 60 |
+
"encoder.block.13.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 61 |
+
"encoder.block.14.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 62 |
+
"encoder.block.14.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 63 |
+
"encoder.block.14.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 64 |
+
"encoder.block.14.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 65 |
+
"encoder.block.14.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 66 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 67 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 68 |
+
"encoder.block.14.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 69 |
+
"encoder.block.14.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 70 |
+
"encoder.block.15.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 71 |
+
"encoder.block.15.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 72 |
+
"encoder.block.15.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 73 |
+
"encoder.block.15.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 74 |
+
"encoder.block.15.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 75 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 76 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 77 |
+
"encoder.block.15.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 78 |
+
"encoder.block.15.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 79 |
+
"encoder.block.16.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 80 |
+
"encoder.block.16.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 81 |
+
"encoder.block.16.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 82 |
+
"encoder.block.16.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 83 |
+
"encoder.block.16.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 84 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 85 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 86 |
+
"encoder.block.16.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 87 |
+
"encoder.block.16.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 88 |
+
"encoder.block.17.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 89 |
+
"encoder.block.17.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 90 |
+
"encoder.block.17.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 91 |
+
"encoder.block.17.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 92 |
+
"encoder.block.17.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 93 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 94 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 95 |
+
"encoder.block.17.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 96 |
+
"encoder.block.17.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 97 |
+
"encoder.block.18.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 98 |
+
"encoder.block.18.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 99 |
+
"encoder.block.18.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 100 |
+
"encoder.block.18.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 101 |
+
"encoder.block.18.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 102 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 103 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 104 |
+
"encoder.block.18.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 105 |
+
"encoder.block.18.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 106 |
+
"encoder.block.19.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 107 |
+
"encoder.block.19.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 108 |
+
"encoder.block.19.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 109 |
+
"encoder.block.19.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 110 |
+
"encoder.block.19.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 111 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 112 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 113 |
+
"encoder.block.19.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 114 |
+
"encoder.block.19.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 115 |
+
"encoder.block.2.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"encoder.block.2.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 117 |
+
"encoder.block.2.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"encoder.block.2.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 119 |
+
"encoder.block.2.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 121 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 122 |
+
"encoder.block.2.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 123 |
+
"encoder.block.2.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 124 |
+
"encoder.block.20.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 125 |
+
"encoder.block.20.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 126 |
+
"encoder.block.20.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 127 |
+
"encoder.block.20.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 128 |
+
"encoder.block.20.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 129 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 130 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 131 |
+
"encoder.block.20.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 132 |
+
"encoder.block.20.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 133 |
+
"encoder.block.21.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 134 |
+
"encoder.block.21.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 135 |
+
"encoder.block.21.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 136 |
+
"encoder.block.21.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 137 |
+
"encoder.block.21.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 138 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 139 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 140 |
+
"encoder.block.21.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 141 |
+
"encoder.block.21.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 142 |
+
"encoder.block.22.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 143 |
+
"encoder.block.22.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 144 |
+
"encoder.block.22.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 145 |
+
"encoder.block.22.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 146 |
+
"encoder.block.22.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 147 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 148 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 149 |
+
"encoder.block.22.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 150 |
+
"encoder.block.22.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 151 |
+
"encoder.block.23.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 152 |
+
"encoder.block.23.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 153 |
+
"encoder.block.23.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 154 |
+
"encoder.block.23.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 155 |
+
"encoder.block.23.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 156 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 157 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 158 |
+
"encoder.block.23.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 159 |
+
"encoder.block.23.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 160 |
+
"encoder.block.3.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 161 |
+
"encoder.block.3.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 162 |
+
"encoder.block.3.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 163 |
+
"encoder.block.3.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"encoder.block.3.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 165 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 166 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 167 |
+
"encoder.block.3.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 168 |
+
"encoder.block.3.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 169 |
+
"encoder.block.4.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 170 |
+
"encoder.block.4.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 171 |
+
"encoder.block.4.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 172 |
+
"encoder.block.4.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 173 |
+
"encoder.block.4.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 174 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 175 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 176 |
+
"encoder.block.4.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 177 |
+
"encoder.block.4.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 178 |
+
"encoder.block.5.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 179 |
+
"encoder.block.5.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 180 |
+
"encoder.block.5.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 181 |
+
"encoder.block.5.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 182 |
+
"encoder.block.5.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 183 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 184 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 185 |
+
"encoder.block.5.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 186 |
+
"encoder.block.5.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 187 |
+
"encoder.block.6.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 188 |
+
"encoder.block.6.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 189 |
+
"encoder.block.6.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 190 |
+
"encoder.block.6.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 191 |
+
"encoder.block.6.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 192 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 193 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 194 |
+
"encoder.block.6.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 195 |
+
"encoder.block.6.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 196 |
+
"encoder.block.7.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 197 |
+
"encoder.block.7.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 198 |
+
"encoder.block.7.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 199 |
+
"encoder.block.7.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 200 |
+
"encoder.block.7.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 201 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 202 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 203 |
+
"encoder.block.7.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 204 |
+
"encoder.block.7.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 205 |
+
"encoder.block.8.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 206 |
+
"encoder.block.8.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 207 |
+
"encoder.block.8.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 208 |
+
"encoder.block.8.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 209 |
+
"encoder.block.8.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 210 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 211 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 212 |
+
"encoder.block.8.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 213 |
+
"encoder.block.8.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 214 |
+
"encoder.block.9.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 215 |
+
"encoder.block.9.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 216 |
+
"encoder.block.9.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 217 |
+
"encoder.block.9.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 218 |
+
"encoder.block.9.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 219 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 220 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 221 |
+
"encoder.block.9.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 222 |
+
"encoder.block.9.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 223 |
+
"encoder.final_layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 224 |
+
"shared.weight": "model-00001-of-00002.safetensors"
|
| 225 |
+
}
|
| 226 |
+
}
|
Path/tokenizer/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Path/tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|endoftext|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<|endoftext|>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
Path/tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"49406": {
|
| 5 |
+
"content": "<|startoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": true,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"49407": {
|
| 13 |
+
"content": "<|endoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
}
|
| 20 |
+
},
|
| 21 |
+
"bos_token": "<|startoftext|>",
|
| 22 |
+
"clean_up_tokenization_spaces": true,
|
| 23 |
+
"do_lower_case": true,
|
| 24 |
+
"eos_token": "<|endoftext|>",
|
| 25 |
+
"errors": "replace",
|
| 26 |
+
"model_max_length": 77,
|
| 27 |
+
"pad_token": "<|endoftext|>",
|
| 28 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 29 |
+
"unk_token": "<|endoftext|>"
|
| 30 |
+
}
|
Path/tokenizer/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Path/tokenizer_2/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Path/tokenizer_2/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "!",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<|endoftext|>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
Path/tokenizer_2/tokenizer_config.json
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"0": {
|
| 5 |
+
"content": "!",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"49406": {
|
| 13 |
+
"content": "<|startoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"49407": {
|
| 21 |
+
"content": "<|endoftext|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"bos_token": "<|startoftext|>",
|
| 30 |
+
"clean_up_tokenization_spaces": true,
|
| 31 |
+
"do_lower_case": true,
|
| 32 |
+
"eos_token": "<|endoftext|>",
|
| 33 |
+
"errors": "replace",
|
| 34 |
+
"model_max_length": 77,
|
| 35 |
+
"pad_token": "!",
|
| 36 |
+
"tokenizer_class": "CLIPTokenizer",
|
| 37 |
+
"unk_token": "<|endoftext|>"
|
| 38 |
+
}
|
Path/tokenizer_2/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Path/tokenizer_3/special_tokens_map.json
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<extra_id_0>",
|
| 4 |
+
"<extra_id_1>",
|
| 5 |
+
"<extra_id_2>",
|
| 6 |
+
"<extra_id_3>",
|
| 7 |
+
"<extra_id_4>",
|
| 8 |
+
"<extra_id_5>",
|
| 9 |
+
"<extra_id_6>",
|
| 10 |
+
"<extra_id_7>",
|
| 11 |
+
"<extra_id_8>",
|
| 12 |
+
"<extra_id_9>",
|
| 13 |
+
"<extra_id_10>",
|
| 14 |
+
"<extra_id_11>",
|
| 15 |
+
"<extra_id_12>",
|
| 16 |
+
"<extra_id_13>",
|
| 17 |
+
"<extra_id_14>",
|
| 18 |
+
"<extra_id_15>",
|
| 19 |
+
"<extra_id_16>",
|
| 20 |
+
"<extra_id_17>",
|
| 21 |
+
"<extra_id_18>",
|
| 22 |
+
"<extra_id_19>",
|
| 23 |
+
"<extra_id_20>",
|
| 24 |
+
"<extra_id_21>",
|
| 25 |
+
"<extra_id_22>",
|
| 26 |
+
"<extra_id_23>",
|
| 27 |
+
"<extra_id_24>",
|
| 28 |
+
"<extra_id_25>",
|
| 29 |
+
"<extra_id_26>",
|
| 30 |
+
"<extra_id_27>",
|
| 31 |
+
"<extra_id_28>",
|
| 32 |
+
"<extra_id_29>",
|
| 33 |
+
"<extra_id_30>",
|
| 34 |
+
"<extra_id_31>",
|
| 35 |
+
"<extra_id_32>",
|
| 36 |
+
"<extra_id_33>",
|
| 37 |
+
"<extra_id_34>",
|
| 38 |
+
"<extra_id_35>",
|
| 39 |
+
"<extra_id_36>",
|
| 40 |
+
"<extra_id_37>",
|
| 41 |
+
"<extra_id_38>",
|
| 42 |
+
"<extra_id_39>",
|
| 43 |
+
"<extra_id_40>",
|
| 44 |
+
"<extra_id_41>",
|
| 45 |
+
"<extra_id_42>",
|
| 46 |
+
"<extra_id_43>",
|
| 47 |
+
"<extra_id_44>",
|
| 48 |
+
"<extra_id_45>",
|
| 49 |
+
"<extra_id_46>",
|
| 50 |
+
"<extra_id_47>",
|
| 51 |
+
"<extra_id_48>",
|
| 52 |
+
"<extra_id_49>",
|
| 53 |
+
"<extra_id_50>",
|
| 54 |
+
"<extra_id_51>",
|
| 55 |
+
"<extra_id_52>",
|
| 56 |
+
"<extra_id_53>",
|
| 57 |
+
"<extra_id_54>",
|
| 58 |
+
"<extra_id_55>",
|
| 59 |
+
"<extra_id_56>",
|
| 60 |
+
"<extra_id_57>",
|
| 61 |
+
"<extra_id_58>",
|
| 62 |
+
"<extra_id_59>",
|
| 63 |
+
"<extra_id_60>",
|
| 64 |
+
"<extra_id_61>",
|
| 65 |
+
"<extra_id_62>",
|
| 66 |
+
"<extra_id_63>",
|
| 67 |
+
"<extra_id_64>",
|
| 68 |
+
"<extra_id_65>",
|
| 69 |
+
"<extra_id_66>",
|
| 70 |
+
"<extra_id_67>",
|
| 71 |
+
"<extra_id_68>",
|
| 72 |
+
"<extra_id_69>",
|
| 73 |
+
"<extra_id_70>",
|
| 74 |
+
"<extra_id_71>",
|
| 75 |
+
"<extra_id_72>",
|
| 76 |
+
"<extra_id_73>",
|
| 77 |
+
"<extra_id_74>",
|
| 78 |
+
"<extra_id_75>",
|
| 79 |
+
"<extra_id_76>",
|
| 80 |
+
"<extra_id_77>",
|
| 81 |
+
"<extra_id_78>",
|
| 82 |
+
"<extra_id_79>",
|
| 83 |
+
"<extra_id_80>",
|
| 84 |
+
"<extra_id_81>",
|
| 85 |
+
"<extra_id_82>",
|
| 86 |
+
"<extra_id_83>",
|
| 87 |
+
"<extra_id_84>",
|
| 88 |
+
"<extra_id_85>",
|
| 89 |
+
"<extra_id_86>",
|
| 90 |
+
"<extra_id_87>",
|
| 91 |
+
"<extra_id_88>",
|
| 92 |
+
"<extra_id_89>",
|
| 93 |
+
"<extra_id_90>",
|
| 94 |
+
"<extra_id_91>",
|
| 95 |
+
"<extra_id_92>",
|
| 96 |
+
"<extra_id_93>",
|
| 97 |
+
"<extra_id_94>",
|
| 98 |
+
"<extra_id_95>",
|
| 99 |
+
"<extra_id_96>",
|
| 100 |
+
"<extra_id_97>",
|
| 101 |
+
"<extra_id_98>",
|
| 102 |
+
"<extra_id_99>"
|
| 103 |
+
],
|
| 104 |
+
"eos_token": {
|
| 105 |
+
"content": "</s>",
|
| 106 |
+
"lstrip": false,
|
| 107 |
+
"normalized": false,
|
| 108 |
+
"rstrip": false,
|
| 109 |
+
"single_word": false
|
| 110 |
+
},
|
| 111 |
+
"pad_token": {
|
| 112 |
+
"content": "<pad>",
|
| 113 |
+
"lstrip": false,
|
| 114 |
+
"normalized": false,
|
| 115 |
+
"rstrip": false,
|
| 116 |
+
"single_word": false
|
| 117 |
+
},
|
| 118 |
+
"unk_token": {
|
| 119 |
+
"content": "<unk>",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": false,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false
|
| 124 |
+
}
|
| 125 |
+
}
|
Path/tokenizer_3/spiece.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d60acb128cf7b7f2536e8f38a5b18a05535c9e14c7a355904270e15b0945ea86
|
| 3 |
+
size 791656
|
Path/tokenizer_3/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Path/tokenizer_3/tokenizer_config.json
ADDED
|
@@ -0,0 +1,940 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": true,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"0": {
|
| 5 |
+
"content": "<pad>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"1": {
|
| 13 |
+
"content": "</s>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"2": {
|
| 21 |
+
"content": "<unk>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"32000": {
|
| 29 |
+
"content": "<extra_id_99>",
|
| 30 |
+
"lstrip": true,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": true,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"32001": {
|
| 37 |
+
"content": "<extra_id_98>",
|
| 38 |
+
"lstrip": true,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": true,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"32002": {
|
| 45 |
+
"content": "<extra_id_97>",
|
| 46 |
+
"lstrip": true,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": true,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"32003": {
|
| 53 |
+
"content": "<extra_id_96>",
|
| 54 |
+
"lstrip": true,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": true,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"32004": {
|
| 61 |
+
"content": "<extra_id_95>",
|
| 62 |
+
"lstrip": true,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": true,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"32005": {
|
| 69 |
+
"content": "<extra_id_94>",
|
| 70 |
+
"lstrip": true,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": true,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"32006": {
|
| 77 |
+
"content": "<extra_id_93>",
|
| 78 |
+
"lstrip": true,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": true,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"32007": {
|
| 85 |
+
"content": "<extra_id_92>",
|
| 86 |
+
"lstrip": true,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": true,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"32008": {
|
| 93 |
+
"content": "<extra_id_91>",
|
| 94 |
+
"lstrip": true,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": true,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"32009": {
|
| 101 |
+
"content": "<extra_id_90>",
|
| 102 |
+
"lstrip": true,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": true,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"32010": {
|
| 109 |
+
"content": "<extra_id_89>",
|
| 110 |
+
"lstrip": true,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": true,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
},
|
| 116 |
+
"32011": {
|
| 117 |
+
"content": "<extra_id_88>",
|
| 118 |
+
"lstrip": true,
|
| 119 |
+
"normalized": false,
|
| 120 |
+
"rstrip": true,
|
| 121 |
+
"single_word": false,
|
| 122 |
+
"special": true
|
| 123 |
+
},
|
| 124 |
+
"32012": {
|
| 125 |
+
"content": "<extra_id_87>",
|
| 126 |
+
"lstrip": true,
|
| 127 |
+
"normalized": false,
|
| 128 |
+
"rstrip": true,
|
| 129 |
+
"single_word": false,
|
| 130 |
+
"special": true
|
| 131 |
+
},
|
| 132 |
+
"32013": {
|
| 133 |
+
"content": "<extra_id_86>",
|
| 134 |
+
"lstrip": true,
|
| 135 |
+
"normalized": false,
|
| 136 |
+
"rstrip": true,
|
| 137 |
+
"single_word": false,
|
| 138 |
+
"special": true
|
| 139 |
+
},
|
| 140 |
+
"32014": {
|
| 141 |
+
"content": "<extra_id_85>",
|
| 142 |
+
"lstrip": true,
|
| 143 |
+
"normalized": false,
|
| 144 |
+
"rstrip": true,
|
| 145 |
+
"single_word": false,
|
| 146 |
+
"special": true
|
| 147 |
+
},
|
| 148 |
+
"32015": {
|
| 149 |
+
"content": "<extra_id_84>",
|
| 150 |
+
"lstrip": true,
|
| 151 |
+
"normalized": false,
|
| 152 |
+
"rstrip": true,
|
| 153 |
+
"single_word": false,
|
| 154 |
+
"special": true
|
| 155 |
+
},
|
| 156 |
+
"32016": {
|
| 157 |
+
"content": "<extra_id_83>",
|
| 158 |
+
"lstrip": true,
|
| 159 |
+
"normalized": false,
|
| 160 |
+
"rstrip": true,
|
| 161 |
+
"single_word": false,
|
| 162 |
+
"special": true
|
| 163 |
+
},
|
| 164 |
+
"32017": {
|
| 165 |
+
"content": "<extra_id_82>",
|
| 166 |
+
"lstrip": true,
|
| 167 |
+
"normalized": false,
|
| 168 |
+
"rstrip": true,
|
| 169 |
+
"single_word": false,
|
| 170 |
+
"special": true
|
| 171 |
+
},
|
| 172 |
+
"32018": {
|
| 173 |
+
"content": "<extra_id_81>",
|
| 174 |
+
"lstrip": true,
|
| 175 |
+
"normalized": false,
|
| 176 |
+
"rstrip": true,
|
| 177 |
+
"single_word": false,
|
| 178 |
+
"special": true
|
| 179 |
+
},
|
| 180 |
+
"32019": {
|
| 181 |
+
"content": "<extra_id_80>",
|
| 182 |
+
"lstrip": true,
|
| 183 |
+
"normalized": false,
|
| 184 |
+
"rstrip": true,
|
| 185 |
+
"single_word": false,
|
| 186 |
+
"special": true
|
| 187 |
+
},
|
| 188 |
+
"32020": {
|
| 189 |
+
"content": "<extra_id_79>",
|
| 190 |
+
"lstrip": true,
|
| 191 |
+
"normalized": false,
|
| 192 |
+
"rstrip": true,
|
| 193 |
+
"single_word": false,
|
| 194 |
+
"special": true
|
| 195 |
+
},
|
| 196 |
+
"32021": {
|
| 197 |
+
"content": "<extra_id_78>",
|
| 198 |
+
"lstrip": true,
|
| 199 |
+
"normalized": false,
|
| 200 |
+
"rstrip": true,
|
| 201 |
+
"single_word": false,
|
| 202 |
+
"special": true
|
| 203 |
+
},
|
| 204 |
+
"32022": {
|
| 205 |
+
"content": "<extra_id_77>",
|
| 206 |
+
"lstrip": true,
|
| 207 |
+
"normalized": false,
|
| 208 |
+
"rstrip": true,
|
| 209 |
+
"single_word": false,
|
| 210 |
+
"special": true
|
| 211 |
+
},
|
| 212 |
+
"32023": {
|
| 213 |
+
"content": "<extra_id_76>",
|
| 214 |
+
"lstrip": true,
|
| 215 |
+
"normalized": false,
|
| 216 |
+
"rstrip": true,
|
| 217 |
+
"single_word": false,
|
| 218 |
+
"special": true
|
| 219 |
+
},
|
| 220 |
+
"32024": {
|
| 221 |
+
"content": "<extra_id_75>",
|
| 222 |
+
"lstrip": true,
|
| 223 |
+
"normalized": false,
|
| 224 |
+
"rstrip": true,
|
| 225 |
+
"single_word": false,
|
| 226 |
+
"special": true
|
| 227 |
+
},
|
| 228 |
+
"32025": {
|
| 229 |
+
"content": "<extra_id_74>",
|
| 230 |
+
"lstrip": true,
|
| 231 |
+
"normalized": false,
|
| 232 |
+
"rstrip": true,
|
| 233 |
+
"single_word": false,
|
| 234 |
+
"special": true
|
| 235 |
+
},
|
| 236 |
+
"32026": {
|
| 237 |
+
"content": "<extra_id_73>",
|
| 238 |
+
"lstrip": true,
|
| 239 |
+
"normalized": false,
|
| 240 |
+
"rstrip": true,
|
| 241 |
+
"single_word": false,
|
| 242 |
+
"special": true
|
| 243 |
+
},
|
| 244 |
+
"32027": {
|
| 245 |
+
"content": "<extra_id_72>",
|
| 246 |
+
"lstrip": true,
|
| 247 |
+
"normalized": false,
|
| 248 |
+
"rstrip": true,
|
| 249 |
+
"single_word": false,
|
| 250 |
+
"special": true
|
| 251 |
+
},
|
| 252 |
+
"32028": {
|
| 253 |
+
"content": "<extra_id_71>",
|
| 254 |
+
"lstrip": true,
|
| 255 |
+
"normalized": false,
|
| 256 |
+
"rstrip": true,
|
| 257 |
+
"single_word": false,
|
| 258 |
+
"special": true
|
| 259 |
+
},
|
| 260 |
+
"32029": {
|
| 261 |
+
"content": "<extra_id_70>",
|
| 262 |
+
"lstrip": true,
|
| 263 |
+
"normalized": false,
|
| 264 |
+
"rstrip": true,
|
| 265 |
+
"single_word": false,
|
| 266 |
+
"special": true
|
| 267 |
+
},
|
| 268 |
+
"32030": {
|
| 269 |
+
"content": "<extra_id_69>",
|
| 270 |
+
"lstrip": true,
|
| 271 |
+
"normalized": false,
|
| 272 |
+
"rstrip": true,
|
| 273 |
+
"single_word": false,
|
| 274 |
+
"special": true
|
| 275 |
+
},
|
| 276 |
+
"32031": {
|
| 277 |
+
"content": "<extra_id_68>",
|
| 278 |
+
"lstrip": true,
|
| 279 |
+
"normalized": false,
|
| 280 |
+
"rstrip": true,
|
| 281 |
+
"single_word": false,
|
| 282 |
+
"special": true
|
| 283 |
+
},
|
| 284 |
+
"32032": {
|
| 285 |
+
"content": "<extra_id_67>",
|
| 286 |
+
"lstrip": true,
|
| 287 |
+
"normalized": false,
|
| 288 |
+
"rstrip": true,
|
| 289 |
+
"single_word": false,
|
| 290 |
+
"special": true
|
| 291 |
+
},
|
| 292 |
+
"32033": {
|
| 293 |
+
"content": "<extra_id_66>",
|
| 294 |
+
"lstrip": true,
|
| 295 |
+
"normalized": false,
|
| 296 |
+
"rstrip": true,
|
| 297 |
+
"single_word": false,
|
| 298 |
+
"special": true
|
| 299 |
+
},
|
| 300 |
+
"32034": {
|
| 301 |
+
"content": "<extra_id_65>",
|
| 302 |
+
"lstrip": true,
|
| 303 |
+
"normalized": false,
|
| 304 |
+
"rstrip": true,
|
| 305 |
+
"single_word": false,
|
| 306 |
+
"special": true
|
| 307 |
+
},
|
| 308 |
+
"32035": {
|
| 309 |
+
"content": "<extra_id_64>",
|
| 310 |
+
"lstrip": true,
|
| 311 |
+
"normalized": false,
|
| 312 |
+
"rstrip": true,
|
| 313 |
+
"single_word": false,
|
| 314 |
+
"special": true
|
| 315 |
+
},
|
| 316 |
+
"32036": {
|
| 317 |
+
"content": "<extra_id_63>",
|
| 318 |
+
"lstrip": true,
|
| 319 |
+
"normalized": false,
|
| 320 |
+
"rstrip": true,
|
| 321 |
+
"single_word": false,
|
| 322 |
+
"special": true
|
| 323 |
+
},
|
| 324 |
+
"32037": {
|
| 325 |
+
"content": "<extra_id_62>",
|
| 326 |
+
"lstrip": true,
|
| 327 |
+
"normalized": false,
|
| 328 |
+
"rstrip": true,
|
| 329 |
+
"single_word": false,
|
| 330 |
+
"special": true
|
| 331 |
+
},
|
| 332 |
+
"32038": {
|
| 333 |
+
"content": "<extra_id_61>",
|
| 334 |
+
"lstrip": true,
|
| 335 |
+
"normalized": false,
|
| 336 |
+
"rstrip": true,
|
| 337 |
+
"single_word": false,
|
| 338 |
+
"special": true
|
| 339 |
+
},
|
| 340 |
+
"32039": {
|
| 341 |
+
"content": "<extra_id_60>",
|
| 342 |
+
"lstrip": true,
|
| 343 |
+
"normalized": false,
|
| 344 |
+
"rstrip": true,
|
| 345 |
+
"single_word": false,
|
| 346 |
+
"special": true
|
| 347 |
+
},
|
| 348 |
+
"32040": {
|
| 349 |
+
"content": "<extra_id_59>",
|
| 350 |
+
"lstrip": true,
|
| 351 |
+
"normalized": false,
|
| 352 |
+
"rstrip": true,
|
| 353 |
+
"single_word": false,
|
| 354 |
+
"special": true
|
| 355 |
+
},
|
| 356 |
+
"32041": {
|
| 357 |
+
"content": "<extra_id_58>",
|
| 358 |
+
"lstrip": true,
|
| 359 |
+
"normalized": false,
|
| 360 |
+
"rstrip": true,
|
| 361 |
+
"single_word": false,
|
| 362 |
+
"special": true
|
| 363 |
+
},
|
| 364 |
+
"32042": {
|
| 365 |
+
"content": "<extra_id_57>",
|
| 366 |
+
"lstrip": true,
|
| 367 |
+
"normalized": false,
|
| 368 |
+
"rstrip": true,
|
| 369 |
+
"single_word": false,
|
| 370 |
+
"special": true
|
| 371 |
+
},
|
| 372 |
+
"32043": {
|
| 373 |
+
"content": "<extra_id_56>",
|
| 374 |
+
"lstrip": true,
|
| 375 |
+
"normalized": false,
|
| 376 |
+
"rstrip": true,
|
| 377 |
+
"single_word": false,
|
| 378 |
+
"special": true
|
| 379 |
+
},
|
| 380 |
+
"32044": {
|
| 381 |
+
"content": "<extra_id_55>",
|
| 382 |
+
"lstrip": true,
|
| 383 |
+
"normalized": false,
|
| 384 |
+
"rstrip": true,
|
| 385 |
+
"single_word": false,
|
| 386 |
+
"special": true
|
| 387 |
+
},
|
| 388 |
+
"32045": {
|
| 389 |
+
"content": "<extra_id_54>",
|
| 390 |
+
"lstrip": true,
|
| 391 |
+
"normalized": false,
|
| 392 |
+
"rstrip": true,
|
| 393 |
+
"single_word": false,
|
| 394 |
+
"special": true
|
| 395 |
+
},
|
| 396 |
+
"32046": {
|
| 397 |
+
"content": "<extra_id_53>",
|
| 398 |
+
"lstrip": true,
|
| 399 |
+
"normalized": false,
|
| 400 |
+
"rstrip": true,
|
| 401 |
+
"single_word": false,
|
| 402 |
+
"special": true
|
| 403 |
+
},
|
| 404 |
+
"32047": {
|
| 405 |
+
"content": "<extra_id_52>",
|
| 406 |
+
"lstrip": true,
|
| 407 |
+
"normalized": false,
|
| 408 |
+
"rstrip": true,
|
| 409 |
+
"single_word": false,
|
| 410 |
+
"special": true
|
| 411 |
+
},
|
| 412 |
+
"32048": {
|
| 413 |
+
"content": "<extra_id_51>",
|
| 414 |
+
"lstrip": true,
|
| 415 |
+
"normalized": false,
|
| 416 |
+
"rstrip": true,
|
| 417 |
+
"single_word": false,
|
| 418 |
+
"special": true
|
| 419 |
+
},
|
| 420 |
+
"32049": {
|
| 421 |
+
"content": "<extra_id_50>",
|
| 422 |
+
"lstrip": true,
|
| 423 |
+
"normalized": false,
|
| 424 |
+
"rstrip": true,
|
| 425 |
+
"single_word": false,
|
| 426 |
+
"special": true
|
| 427 |
+
},
|
| 428 |
+
"32050": {
|
| 429 |
+
"content": "<extra_id_49>",
|
| 430 |
+
"lstrip": true,
|
| 431 |
+
"normalized": false,
|
| 432 |
+
"rstrip": true,
|
| 433 |
+
"single_word": false,
|
| 434 |
+
"special": true
|
| 435 |
+
},
|
| 436 |
+
"32051": {
|
| 437 |
+
"content": "<extra_id_48>",
|
| 438 |
+
"lstrip": true,
|
| 439 |
+
"normalized": false,
|
| 440 |
+
"rstrip": true,
|
| 441 |
+
"single_word": false,
|
| 442 |
+
"special": true
|
| 443 |
+
},
|
| 444 |
+
"32052": {
|
| 445 |
+
"content": "<extra_id_47>",
|
| 446 |
+
"lstrip": true,
|
| 447 |
+
"normalized": false,
|
| 448 |
+
"rstrip": true,
|
| 449 |
+
"single_word": false,
|
| 450 |
+
"special": true
|
| 451 |
+
},
|
| 452 |
+
"32053": {
|
| 453 |
+
"content": "<extra_id_46>",
|
| 454 |
+
"lstrip": true,
|
| 455 |
+
"normalized": false,
|
| 456 |
+
"rstrip": true,
|
| 457 |
+
"single_word": false,
|
| 458 |
+
"special": true
|
| 459 |
+
},
|
| 460 |
+
"32054": {
|
| 461 |
+
"content": "<extra_id_45>",
|
| 462 |
+
"lstrip": true,
|
| 463 |
+
"normalized": false,
|
| 464 |
+
"rstrip": true,
|
| 465 |
+
"single_word": false,
|
| 466 |
+
"special": true
|
| 467 |
+
},
|
| 468 |
+
"32055": {
|
| 469 |
+
"content": "<extra_id_44>",
|
| 470 |
+
"lstrip": true,
|
| 471 |
+
"normalized": false,
|
| 472 |
+
"rstrip": true,
|
| 473 |
+
"single_word": false,
|
| 474 |
+
"special": true
|
| 475 |
+
},
|
| 476 |
+
"32056": {
|
| 477 |
+
"content": "<extra_id_43>",
|
| 478 |
+
"lstrip": true,
|
| 479 |
+
"normalized": false,
|
| 480 |
+
"rstrip": true,
|
| 481 |
+
"single_word": false,
|
| 482 |
+
"special": true
|
| 483 |
+
},
|
| 484 |
+
"32057": {
|
| 485 |
+
"content": "<extra_id_42>",
|
| 486 |
+
"lstrip": true,
|
| 487 |
+
"normalized": false,
|
| 488 |
+
"rstrip": true,
|
| 489 |
+
"single_word": false,
|
| 490 |
+
"special": true
|
| 491 |
+
},
|
| 492 |
+
"32058": {
|
| 493 |
+
"content": "<extra_id_41>",
|
| 494 |
+
"lstrip": true,
|
| 495 |
+
"normalized": false,
|
| 496 |
+
"rstrip": true,
|
| 497 |
+
"single_word": false,
|
| 498 |
+
"special": true
|
| 499 |
+
},
|
| 500 |
+
"32059": {
|
| 501 |
+
"content": "<extra_id_40>",
|
| 502 |
+
"lstrip": true,
|
| 503 |
+
"normalized": false,
|
| 504 |
+
"rstrip": true,
|
| 505 |
+
"single_word": false,
|
| 506 |
+
"special": true
|
| 507 |
+
},
|
| 508 |
+
"32060": {
|
| 509 |
+
"content": "<extra_id_39>",
|
| 510 |
+
"lstrip": true,
|
| 511 |
+
"normalized": false,
|
| 512 |
+
"rstrip": true,
|
| 513 |
+
"single_word": false,
|
| 514 |
+
"special": true
|
| 515 |
+
},
|
| 516 |
+
"32061": {
|
| 517 |
+
"content": "<extra_id_38>",
|
| 518 |
+
"lstrip": true,
|
| 519 |
+
"normalized": false,
|
| 520 |
+
"rstrip": true,
|
| 521 |
+
"single_word": false,
|
| 522 |
+
"special": true
|
| 523 |
+
},
|
| 524 |
+
"32062": {
|
| 525 |
+
"content": "<extra_id_37>",
|
| 526 |
+
"lstrip": true,
|
| 527 |
+
"normalized": false,
|
| 528 |
+
"rstrip": true,
|
| 529 |
+
"single_word": false,
|
| 530 |
+
"special": true
|
| 531 |
+
},
|
| 532 |
+
"32063": {
|
| 533 |
+
"content": "<extra_id_36>",
|
| 534 |
+
"lstrip": true,
|
| 535 |
+
"normalized": false,
|
| 536 |
+
"rstrip": true,
|
| 537 |
+
"single_word": false,
|
| 538 |
+
"special": true
|
| 539 |
+
},
|
| 540 |
+
"32064": {
|
| 541 |
+
"content": "<extra_id_35>",
|
| 542 |
+
"lstrip": true,
|
| 543 |
+
"normalized": false,
|
| 544 |
+
"rstrip": true,
|
| 545 |
+
"single_word": false,
|
| 546 |
+
"special": true
|
| 547 |
+
},
|
| 548 |
+
"32065": {
|
| 549 |
+
"content": "<extra_id_34>",
|
| 550 |
+
"lstrip": true,
|
| 551 |
+
"normalized": false,
|
| 552 |
+
"rstrip": true,
|
| 553 |
+
"single_word": false,
|
| 554 |
+
"special": true
|
| 555 |
+
},
|
| 556 |
+
"32066": {
|
| 557 |
+
"content": "<extra_id_33>",
|
| 558 |
+
"lstrip": true,
|
| 559 |
+
"normalized": false,
|
| 560 |
+
"rstrip": true,
|
| 561 |
+
"single_word": false,
|
| 562 |
+
"special": true
|
| 563 |
+
},
|
| 564 |
+
"32067": {
|
| 565 |
+
"content": "<extra_id_32>",
|
| 566 |
+
"lstrip": true,
|
| 567 |
+
"normalized": false,
|
| 568 |
+
"rstrip": true,
|
| 569 |
+
"single_word": false,
|
| 570 |
+
"special": true
|
| 571 |
+
},
|
| 572 |
+
"32068": {
|
| 573 |
+
"content": "<extra_id_31>",
|
| 574 |
+
"lstrip": true,
|
| 575 |
+
"normalized": false,
|
| 576 |
+
"rstrip": true,
|
| 577 |
+
"single_word": false,
|
| 578 |
+
"special": true
|
| 579 |
+
},
|
| 580 |
+
"32069": {
|
| 581 |
+
"content": "<extra_id_30>",
|
| 582 |
+
"lstrip": true,
|
| 583 |
+
"normalized": false,
|
| 584 |
+
"rstrip": true,
|
| 585 |
+
"single_word": false,
|
| 586 |
+
"special": true
|
| 587 |
+
},
|
| 588 |
+
"32070": {
|
| 589 |
+
"content": "<extra_id_29>",
|
| 590 |
+
"lstrip": true,
|
| 591 |
+
"normalized": false,
|
| 592 |
+
"rstrip": true,
|
| 593 |
+
"single_word": false,
|
| 594 |
+
"special": true
|
| 595 |
+
},
|
| 596 |
+
"32071": {
|
| 597 |
+
"content": "<extra_id_28>",
|
| 598 |
+
"lstrip": true,
|
| 599 |
+
"normalized": false,
|
| 600 |
+
"rstrip": true,
|
| 601 |
+
"single_word": false,
|
| 602 |
+
"special": true
|
| 603 |
+
},
|
| 604 |
+
"32072": {
|
| 605 |
+
"content": "<extra_id_27>",
|
| 606 |
+
"lstrip": true,
|
| 607 |
+
"normalized": false,
|
| 608 |
+
"rstrip": true,
|
| 609 |
+
"single_word": false,
|
| 610 |
+
"special": true
|
| 611 |
+
},
|
| 612 |
+
"32073": {
|
| 613 |
+
"content": "<extra_id_26>",
|
| 614 |
+
"lstrip": true,
|
| 615 |
+
"normalized": false,
|
| 616 |
+
"rstrip": true,
|
| 617 |
+
"single_word": false,
|
| 618 |
+
"special": true
|
| 619 |
+
},
|
| 620 |
+
"32074": {
|
| 621 |
+
"content": "<extra_id_25>",
|
| 622 |
+
"lstrip": true,
|
| 623 |
+
"normalized": false,
|
| 624 |
+
"rstrip": true,
|
| 625 |
+
"single_word": false,
|
| 626 |
+
"special": true
|
| 627 |
+
},
|
| 628 |
+
"32075": {
|
| 629 |
+
"content": "<extra_id_24>",
|
| 630 |
+
"lstrip": true,
|
| 631 |
+
"normalized": false,
|
| 632 |
+
"rstrip": true,
|
| 633 |
+
"single_word": false,
|
| 634 |
+
"special": true
|
| 635 |
+
},
|
| 636 |
+
"32076": {
|
| 637 |
+
"content": "<extra_id_23>",
|
| 638 |
+
"lstrip": true,
|
| 639 |
+
"normalized": false,
|
| 640 |
+
"rstrip": true,
|
| 641 |
+
"single_word": false,
|
| 642 |
+
"special": true
|
| 643 |
+
},
|
| 644 |
+
"32077": {
|
| 645 |
+
"content": "<extra_id_22>",
|
| 646 |
+
"lstrip": true,
|
| 647 |
+
"normalized": false,
|
| 648 |
+
"rstrip": true,
|
| 649 |
+
"single_word": false,
|
| 650 |
+
"special": true
|
| 651 |
+
},
|
| 652 |
+
"32078": {
|
| 653 |
+
"content": "<extra_id_21>",
|
| 654 |
+
"lstrip": true,
|
| 655 |
+
"normalized": false,
|
| 656 |
+
"rstrip": true,
|
| 657 |
+
"single_word": false,
|
| 658 |
+
"special": true
|
| 659 |
+
},
|
| 660 |
+
"32079": {
|
| 661 |
+
"content": "<extra_id_20>",
|
| 662 |
+
"lstrip": true,
|
| 663 |
+
"normalized": false,
|
| 664 |
+
"rstrip": true,
|
| 665 |
+
"single_word": false,
|
| 666 |
+
"special": true
|
| 667 |
+
},
|
| 668 |
+
"32080": {
|
| 669 |
+
"content": "<extra_id_19>",
|
| 670 |
+
"lstrip": true,
|
| 671 |
+
"normalized": false,
|
| 672 |
+
"rstrip": true,
|
| 673 |
+
"single_word": false,
|
| 674 |
+
"special": true
|
| 675 |
+
},
|
| 676 |
+
"32081": {
|
| 677 |
+
"content": "<extra_id_18>",
|
| 678 |
+
"lstrip": true,
|
| 679 |
+
"normalized": false,
|
| 680 |
+
"rstrip": true,
|
| 681 |
+
"single_word": false,
|
| 682 |
+
"special": true
|
| 683 |
+
},
|
| 684 |
+
"32082": {
|
| 685 |
+
"content": "<extra_id_17>",
|
| 686 |
+
"lstrip": true,
|
| 687 |
+
"normalized": false,
|
| 688 |
+
"rstrip": true,
|
| 689 |
+
"single_word": false,
|
| 690 |
+
"special": true
|
| 691 |
+
},
|
| 692 |
+
"32083": {
|
| 693 |
+
"content": "<extra_id_16>",
|
| 694 |
+
"lstrip": true,
|
| 695 |
+
"normalized": false,
|
| 696 |
+
"rstrip": true,
|
| 697 |
+
"single_word": false,
|
| 698 |
+
"special": true
|
| 699 |
+
},
|
| 700 |
+
"32084": {
|
| 701 |
+
"content": "<extra_id_15>",
|
| 702 |
+
"lstrip": true,
|
| 703 |
+
"normalized": false,
|
| 704 |
+
"rstrip": true,
|
| 705 |
+
"single_word": false,
|
| 706 |
+
"special": true
|
| 707 |
+
},
|
| 708 |
+
"32085": {
|
| 709 |
+
"content": "<extra_id_14>",
|
| 710 |
+
"lstrip": true,
|
| 711 |
+
"normalized": false,
|
| 712 |
+
"rstrip": true,
|
| 713 |
+
"single_word": false,
|
| 714 |
+
"special": true
|
| 715 |
+
},
|
| 716 |
+
"32086": {
|
| 717 |
+
"content": "<extra_id_13>",
|
| 718 |
+
"lstrip": true,
|
| 719 |
+
"normalized": false,
|
| 720 |
+
"rstrip": true,
|
| 721 |
+
"single_word": false,
|
| 722 |
+
"special": true
|
| 723 |
+
},
|
| 724 |
+
"32087": {
|
| 725 |
+
"content": "<extra_id_12>",
|
| 726 |
+
"lstrip": true,
|
| 727 |
+
"normalized": false,
|
| 728 |
+
"rstrip": true,
|
| 729 |
+
"single_word": false,
|
| 730 |
+
"special": true
|
| 731 |
+
},
|
| 732 |
+
"32088": {
|
| 733 |
+
"content": "<extra_id_11>",
|
| 734 |
+
"lstrip": true,
|
| 735 |
+
"normalized": false,
|
| 736 |
+
"rstrip": true,
|
| 737 |
+
"single_word": false,
|
| 738 |
+
"special": true
|
| 739 |
+
},
|
| 740 |
+
"32089": {
|
| 741 |
+
"content": "<extra_id_10>",
|
| 742 |
+
"lstrip": true,
|
| 743 |
+
"normalized": false,
|
| 744 |
+
"rstrip": true,
|
| 745 |
+
"single_word": false,
|
| 746 |
+
"special": true
|
| 747 |
+
},
|
| 748 |
+
"32090": {
|
| 749 |
+
"content": "<extra_id_9>",
|
| 750 |
+
"lstrip": true,
|
| 751 |
+
"normalized": false,
|
| 752 |
+
"rstrip": true,
|
| 753 |
+
"single_word": false,
|
| 754 |
+
"special": true
|
| 755 |
+
},
|
| 756 |
+
"32091": {
|
| 757 |
+
"content": "<extra_id_8>",
|
| 758 |
+
"lstrip": true,
|
| 759 |
+
"normalized": false,
|
| 760 |
+
"rstrip": true,
|
| 761 |
+
"single_word": false,
|
| 762 |
+
"special": true
|
| 763 |
+
},
|
| 764 |
+
"32092": {
|
| 765 |
+
"content": "<extra_id_7>",
|
| 766 |
+
"lstrip": true,
|
| 767 |
+
"normalized": false,
|
| 768 |
+
"rstrip": true,
|
| 769 |
+
"single_word": false,
|
| 770 |
+
"special": true
|
| 771 |
+
},
|
| 772 |
+
"32093": {
|
| 773 |
+
"content": "<extra_id_6>",
|
| 774 |
+
"lstrip": true,
|
| 775 |
+
"normalized": false,
|
| 776 |
+
"rstrip": true,
|
| 777 |
+
"single_word": false,
|
| 778 |
+
"special": true
|
| 779 |
+
},
|
| 780 |
+
"32094": {
|
| 781 |
+
"content": "<extra_id_5>",
|
| 782 |
+
"lstrip": true,
|
| 783 |
+
"normalized": false,
|
| 784 |
+
"rstrip": true,
|
| 785 |
+
"single_word": false,
|
| 786 |
+
"special": true
|
| 787 |
+
},
|
| 788 |
+
"32095": {
|
| 789 |
+
"content": "<extra_id_4>",
|
| 790 |
+
"lstrip": true,
|
| 791 |
+
"normalized": false,
|
| 792 |
+
"rstrip": true,
|
| 793 |
+
"single_word": false,
|
| 794 |
+
"special": true
|
| 795 |
+
},
|
| 796 |
+
"32096": {
|
| 797 |
+
"content": "<extra_id_3>",
|
| 798 |
+
"lstrip": true,
|
| 799 |
+
"normalized": false,
|
| 800 |
+
"rstrip": true,
|
| 801 |
+
"single_word": false,
|
| 802 |
+
"special": true
|
| 803 |
+
},
|
| 804 |
+
"32097": {
|
| 805 |
+
"content": "<extra_id_2>",
|
| 806 |
+
"lstrip": true,
|
| 807 |
+
"normalized": false,
|
| 808 |
+
"rstrip": true,
|
| 809 |
+
"single_word": false,
|
| 810 |
+
"special": true
|
| 811 |
+
},
|
| 812 |
+
"32098": {
|
| 813 |
+
"content": "<extra_id_1>",
|
| 814 |
+
"lstrip": true,
|
| 815 |
+
"normalized": false,
|
| 816 |
+
"rstrip": true,
|
| 817 |
+
"single_word": false,
|
| 818 |
+
"special": true
|
| 819 |
+
},
|
| 820 |
+
"32099": {
|
| 821 |
+
"content": "<extra_id_0>",
|
| 822 |
+
"lstrip": true,
|
| 823 |
+
"normalized": false,
|
| 824 |
+
"rstrip": true,
|
| 825 |
+
"single_word": false,
|
| 826 |
+
"special": true
|
| 827 |
+
}
|
| 828 |
+
},
|
| 829 |
+
"additional_special_tokens": [
|
| 830 |
+
"<extra_id_0>",
|
| 831 |
+
"<extra_id_1>",
|
| 832 |
+
"<extra_id_2>",
|
| 833 |
+
"<extra_id_3>",
|
| 834 |
+
"<extra_id_4>",
|
| 835 |
+
"<extra_id_5>",
|
| 836 |
+
"<extra_id_6>",
|
| 837 |
+
"<extra_id_7>",
|
| 838 |
+
"<extra_id_8>",
|
| 839 |
+
"<extra_id_9>",
|
| 840 |
+
"<extra_id_10>",
|
| 841 |
+
"<extra_id_11>",
|
| 842 |
+
"<extra_id_12>",
|
| 843 |
+
"<extra_id_13>",
|
| 844 |
+
"<extra_id_14>",
|
| 845 |
+
"<extra_id_15>",
|
| 846 |
+
"<extra_id_16>",
|
| 847 |
+
"<extra_id_17>",
|
| 848 |
+
"<extra_id_18>",
|
| 849 |
+
"<extra_id_19>",
|
| 850 |
+
"<extra_id_20>",
|
| 851 |
+
"<extra_id_21>",
|
| 852 |
+
"<extra_id_22>",
|
| 853 |
+
"<extra_id_23>",
|
| 854 |
+
"<extra_id_24>",
|
| 855 |
+
"<extra_id_25>",
|
| 856 |
+
"<extra_id_26>",
|
| 857 |
+
"<extra_id_27>",
|
| 858 |
+
"<extra_id_28>",
|
| 859 |
+
"<extra_id_29>",
|
| 860 |
+
"<extra_id_30>",
|
| 861 |
+
"<extra_id_31>",
|
| 862 |
+
"<extra_id_32>",
|
| 863 |
+
"<extra_id_33>",
|
| 864 |
+
"<extra_id_34>",
|
| 865 |
+
"<extra_id_35>",
|
| 866 |
+
"<extra_id_36>",
|
| 867 |
+
"<extra_id_37>",
|
| 868 |
+
"<extra_id_38>",
|
| 869 |
+
"<extra_id_39>",
|
| 870 |
+
"<extra_id_40>",
|
| 871 |
+
"<extra_id_41>",
|
| 872 |
+
"<extra_id_42>",
|
| 873 |
+
"<extra_id_43>",
|
| 874 |
+
"<extra_id_44>",
|
| 875 |
+
"<extra_id_45>",
|
| 876 |
+
"<extra_id_46>",
|
| 877 |
+
"<extra_id_47>",
|
| 878 |
+
"<extra_id_48>",
|
| 879 |
+
"<extra_id_49>",
|
| 880 |
+
"<extra_id_50>",
|
| 881 |
+
"<extra_id_51>",
|
| 882 |
+
"<extra_id_52>",
|
| 883 |
+
"<extra_id_53>",
|
| 884 |
+
"<extra_id_54>",
|
| 885 |
+
"<extra_id_55>",
|
| 886 |
+
"<extra_id_56>",
|
| 887 |
+
"<extra_id_57>",
|
| 888 |
+
"<extra_id_58>",
|
| 889 |
+
"<extra_id_59>",
|
| 890 |
+
"<extra_id_60>",
|
| 891 |
+
"<extra_id_61>",
|
| 892 |
+
"<extra_id_62>",
|
| 893 |
+
"<extra_id_63>",
|
| 894 |
+
"<extra_id_64>",
|
| 895 |
+
"<extra_id_65>",
|
| 896 |
+
"<extra_id_66>",
|
| 897 |
+
"<extra_id_67>",
|
| 898 |
+
"<extra_id_68>",
|
| 899 |
+
"<extra_id_69>",
|
| 900 |
+
"<extra_id_70>",
|
| 901 |
+
"<extra_id_71>",
|
| 902 |
+
"<extra_id_72>",
|
| 903 |
+
"<extra_id_73>",
|
| 904 |
+
"<extra_id_74>",
|
| 905 |
+
"<extra_id_75>",
|
| 906 |
+
"<extra_id_76>",
|
| 907 |
+
"<extra_id_77>",
|
| 908 |
+
"<extra_id_78>",
|
| 909 |
+
"<extra_id_79>",
|
| 910 |
+
"<extra_id_80>",
|
| 911 |
+
"<extra_id_81>",
|
| 912 |
+
"<extra_id_82>",
|
| 913 |
+
"<extra_id_83>",
|
| 914 |
+
"<extra_id_84>",
|
| 915 |
+
"<extra_id_85>",
|
| 916 |
+
"<extra_id_86>",
|
| 917 |
+
"<extra_id_87>",
|
| 918 |
+
"<extra_id_88>",
|
| 919 |
+
"<extra_id_89>",
|
| 920 |
+
"<extra_id_90>",
|
| 921 |
+
"<extra_id_91>",
|
| 922 |
+
"<extra_id_92>",
|
| 923 |
+
"<extra_id_93>",
|
| 924 |
+
"<extra_id_94>",
|
| 925 |
+
"<extra_id_95>",
|
| 926 |
+
"<extra_id_96>",
|
| 927 |
+
"<extra_id_97>",
|
| 928 |
+
"<extra_id_98>",
|
| 929 |
+
"<extra_id_99>"
|
| 930 |
+
],
|
| 931 |
+
"clean_up_tokenization_spaces": true,
|
| 932 |
+
"eos_token": "</s>",
|
| 933 |
+
"extra_ids": 100,
|
| 934 |
+
"legacy": true,
|
| 935 |
+
"model_max_length": 512,
|
| 936 |
+
"pad_token": "<pad>",
|
| 937 |
+
"sp_model_kwargs": {},
|
| 938 |
+
"tokenizer_class": "T5Tokenizer",
|
| 939 |
+
"unk_token": "<unk>"
|
| 940 |
+
}
|
annotation/image_text.jsonl
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"image": "SAM_filter/000424/sa_4749867.jpg", "text": "a cityscape with a large body of water, such as a lake or a river, in the foreground"}
|
| 2 |
+
{"image": "SAM_filter/000311/sa_3490721.jpg", "text": "a large, stately building with a white and blue color scheme, which gives it a grand and elegant appearance"}
|
| 3 |
+
{"image": "SAM_filter/000273/sa_3059407.jpg", "text": "a close-up of a green bag containing a package of Japanese soybeans, along with a bottle of sake, a traditional Japanese alcoholic beverage"}
|
| 4 |
+
{"image": "SAM_filter/000745/sa_8344729.jpg", "text": "a large, old-fashioned building with a red and white color scheme"}
|
| 5 |
+
{"image": "SAM_filter/000832/sa_9310794.jpg", "text": "a cityscape with a large tower, likely the Eiffel Tower, as the main focal point"}
|
| 6 |
+
{"image": "SAM_filter/000427/sa_4779422.jpg", "text": "a large cruise ship, specifically a Royal Caribbean cruise ship, docked at a pier in a harbor"}
|
| 7 |
+
{"image": "SAM_filter/000105/sa_1178255.jpg", "text": "a close-up view of a computer screen with a magnifying glass placed over it"}
|
| 8 |
+
{"image": "SAM_filter/000765/sa_8560467.jpg", "text": "a tree with a sign attached to it, which is located in a lush green field"}
|
| 9 |
+
{"image": "SAM_filter/000216/sa_2417372.jpg", "text": "a large airport terminal with a long blue and white rope-style security line"}
|
| 10 |
+
{"image": "SAM_filter/000385/sa_4308806.jpg", "text": "a close-up of a cell phone screen displaying a blue and white logo, which appears to be a bank logo"}
|
| 11 |
+
{"image": "SAM_filter/000931/sa_10425835.jpg", "text": "a large body of water, possibly a lake, with a lush green landscape surrounding it"}
|
| 12 |
+
{"image": "SAM_filter/000364/sa_4079002.jpg", "text": "a large, empty airport terminal with a long row of gray metal chairs arranged in a straight line"}
|
| 13 |
+
{"image": "SAM_filter/000474/sa_5306222.jpg", "text": "a large, modern building with a tall, glass structure, which is likely a museum"}
|
| 14 |
+
{"image": "SAM_filter/000584/sa_6536849.jpg", "text": "a city street scene with a black car parked in a parking lot, a building with a balcony, and a city skyline in the background"}
|
| 15 |
+
{"image": "SAM_filter/000188/sa_2104485.jpg", "text": "a large jet fighter airplane flying through the sky, captured in a high-quality photograph"}
|
| 16 |
+
{"image": "SAM_filter/000219/sa_2458908.jpg", "text": "a stone structure with a tall tower, which is situated in a lush green garden"}
|
| 17 |
+
{"image": "SAM_filter/000440/sa_4929413.jpg", "text": "a large city street with a mix of architectural styles, including a Gothic-style building and a modern building"}
|
| 18 |
+
{"image": "SAM_filter/000739/sa_8279296.jpg", "text": "a vintage blue and white bus parked on the side of a dirt road, with a building in the background"}
|
| 19 |
+
{"image": "SAM_filter/000809/sa_9052304.jpg", "text": "a large, old stone building with a clock tower, which is situated in a small town"}
|
| 20 |
+
{"image": "SAM_filter/000294/sa_3300200.jpg", "text": "a table with various utensils, including a bowl, spoon, and fork, placed on a wooden surface"}
|
annotation/video_text.jsonl
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"video": "webvid10m/train/010451_010500/23388121.mp4", "text": "the serene beauty of a valley with a river, mountains, and clouds", "latent": "webvid10m/train/010451_010500/23388121-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/010451_010500/23388121-text.pt"}
|
| 2 |
+
{"video": "pexels/8440980-uhd_3840_2160_25fps.mp4", "text": "A group of people, including two men and two women, are seen sitting at a table, smiling and waving at the camera, and appear to be in a good mood", "latent": "pexels/8440980-uhd_3840_2160_25fps-latent-384-2.pt", "text_fea": "text_feature/pexels/8440980-uhd_3840_2160_25fps-text.pt"}
|
| 3 |
+
{"video": "webvid10m/train/176251_176300/1011015221.mp4", "text": "an aerial view of a large wheat field with a road running through it, and a car driving on the road", "latent": "webvid10m/train/176251_176300/1011015221-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/176251_176300/1011015221-text.pt"}
|
| 4 |
+
{"video": "webvid10m/train/005801_005850/22143805.mp4", "text": "a close-up of paint mixing in water, creating swirling patterns", "latent": "webvid10m/train/005801_005850/22143805-latent-384-8.pt", "text_fea": "text_feature/webvid10m/train/005801_005850/22143805-text.pt"}
|
| 5 |
+
{"video": "OpenVid-1M/videos/qsXY7FkNFwE_2_0to743.mp4", "text": "A baby girl in a pink shirt and striped pants sits in a high chair, eats a piece of bread, and looks at the camera", "latent": "OpenVid-1M/videos/qsXY7FkNFwE_2_0to743-latent-384-0.pt", "text_fea": "text_feature/OpenVid-1M/videos/qsXY7FkNFwE_2_0to743-text.pt"}
|
| 6 |
+
{"video": "webvid10m/train/134901_134950/1037990273.mp4", "text": "a field of green wheat waving in the wind", "latent": "webvid10m/train/134901_134950/1037990273-latent-384-6.pt", "text_fea": "text_feature/webvid10m/train/134901_134950/1037990273-text.pt"}
|
| 7 |
+
{"video": "pexels/5263258-uhd_2160_4096_30fps.mp4", "text": "A dog sits patiently in front of its bowl, waiting for it to be filled with food", "latent": "pexels/5263258-uhd_2160_4096_30fps-latent-384-6.pt", "text_fea": "text_feature/pexels/5263258-uhd_2160_4096_30fps-text.pt"}
|
| 8 |
+
{"video": "webvid10m/train/117851_117900/6461432.mp4", "text": "A ladybug crawls along a blade of grass in a serene natural setting", "latent": "webvid10m/train/117851_117900/6461432-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/117851_117900/6461432-text.pt"}
|
| 9 |
+
{"video": "webvid10m/train/053051_053100/1058396656.mp4", "text": "a group of construction workers working on a rooftop, with a supervisor overseeing the work", "latent": "webvid10m/train/053051_053100/1058396656-latent-384-10.pt", "text_fea": "text_feature/webvid10m/train/053051_053100/1058396656-text.pt"}
|
| 10 |
+
{"video": "webvid10m/train/073651_073700/1021916425.mp4", "text": "an aerial view of a beautiful coastline with rocky islands, blue water, and a white cloud in the sky", "latent": "webvid10m/train/073651_073700/1021916425-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/073651_073700/1021916425-text.pt"}
|
| 11 |
+
{"video": "webvid10m/train/027051_027100/1032549941.mp4", "text": "a young woman waking up in bed, smiling at the camera, and then lying back down on the bed", "latent": "webvid10m/train/027051_027100/1032549941-latent-384-10.pt", "text_fea": "text_feature/webvid10m/train/027051_027100/1032549941-text.pt"}
|
| 12 |
+
{"video": "pexels/5564564-uhd_3840_2160_24fps.mp4", "text": "a person rolling out dough on a table using a rolling pin", "latent": "pexels/5564564-uhd_3840_2160_24fps-latent-384-8.pt", "text_fea": "text_feature/pexels/5564564-uhd_3840_2160_24fps-text.pt"}
|
| 13 |
+
{"video": "webvid10m/train/073701_073750/24008116.mp4", "text": "a cityscape with a moon in the sky, and the camera pans across the city", "latent": "webvid10m/train/073701_073750/24008116-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/073701_073750/24008116-text.pt"}
|
| 14 |
+
{"video": "webvid10m/train/118351_118400/23370991.mp4", "text": "a group of dolphins swimming in the ocean, with a person on a boat nearby", "latent": "webvid10m/train/118351_118400/23370991-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/118351_118400/23370991-text.pt"}
|
| 15 |
+
{"video": "webvid10m/train/022001_022050/1023013066.mp4", "text": "a bird's eye view of a beachfront city, highlighting the hotels, pools, and proximity to the ocean", "latent": "webvid10m/train/022001_022050/1023013066-latent-384-10.pt", "text_fea": "text_feature/webvid10m/train/022001_022050/1023013066-text.pt"}
|
| 16 |
+
{"video": "webvid10m/train/004601_004650/1015979020.mp4", "text": "a bridge over a body of water, with a boat passing under it", "latent": "webvid10m/train/004601_004650/1015979020-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/004601_004650/1015979020-text.pt"}
|
| 17 |
+
{"video": "webvid10m/train/149701_149750/1034525579.mp4", "text": "a group of owls and a moon, with the moon appearing to grow larger as the video progresses", "latent": "webvid10m/train/149701_149750/1034525579-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/149701_149750/1034525579-text.pt"}
|
app.py
ADDED
|
@@ -0,0 +1,356 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import uuid
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import torch
|
| 5 |
+
import PIL
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 8 |
+
from diffusers.utils import export_to_video
|
| 9 |
+
from huggingface_hub import snapshot_download
|
| 10 |
+
import threading
|
| 11 |
+
import random
|
| 12 |
+
|
| 13 |
+
# Global model cache
|
| 14 |
+
model_cache = {}
|
| 15 |
+
|
| 16 |
+
# Lock to ensure thread-safe access to the model cache
|
| 17 |
+
model_cache_lock = threading.Lock()
|
| 18 |
+
|
| 19 |
+
# Configuration
|
| 20 |
+
model_name = "pyramid_flux" # or pyramid_mmdit
|
| 21 |
+
model_repo = "rain1011/pyramid-flow-sd3" if model_name == "pyramid_mmdit" else "rain1011/pyramid-flow-miniflux"
|
| 22 |
+
|
| 23 |
+
model_dtype = "bf16" # Support bf16 and fp32
|
| 24 |
+
variants = {
|
| 25 |
+
'high': 'diffusion_transformer_768p', # For high-resolution version
|
| 26 |
+
'low': 'diffusion_transformer_384p' # For low-resolution version
|
| 27 |
+
}
|
| 28 |
+
required_file = 'config.json' # Ensure config.json is present
|
| 29 |
+
width_high = 1280
|
| 30 |
+
height_high = 768
|
| 31 |
+
width_low = 640
|
| 32 |
+
height_low = 384
|
| 33 |
+
cpu_offloading = True # enable cpu_offloading by default
|
| 34 |
+
|
| 35 |
+
# Get the current working directory and create a folder to store the model
|
| 36 |
+
current_directory = os.getcwd()
|
| 37 |
+
model_path = os.path.join(current_directory, "pyramid_flow_model") # Directory to store the model
|
| 38 |
+
|
| 39 |
+
# Download the model if not already present
|
| 40 |
+
def download_model_from_hf(model_repo, model_dir, variants, required_file):
|
| 41 |
+
need_download = False
|
| 42 |
+
if not os.path.exists(model_dir):
|
| 43 |
+
print(f"[INFO] Model directory '{model_dir}' does not exist. Initiating download...")
|
| 44 |
+
need_download = True
|
| 45 |
+
else:
|
| 46 |
+
# Check if all required files exist for each variant
|
| 47 |
+
for variant_key, variant_dir in variants.items():
|
| 48 |
+
variant_path = os.path.join(model_dir, variant_dir)
|
| 49 |
+
file_path = os.path.join(variant_path, required_file)
|
| 50 |
+
if not os.path.exists(file_path):
|
| 51 |
+
print(f"[WARNING] Required file '{required_file}' missing in '{variant_path}'.")
|
| 52 |
+
need_download = True
|
| 53 |
+
break
|
| 54 |
+
|
| 55 |
+
if need_download:
|
| 56 |
+
print(f"[INFO] Downloading model from '{model_repo}' to '{model_dir}'...")
|
| 57 |
+
try:
|
| 58 |
+
snapshot_download(
|
| 59 |
+
repo_id=model_repo,
|
| 60 |
+
local_dir=model_dir,
|
| 61 |
+
local_dir_use_symlinks=False,
|
| 62 |
+
repo_type='model'
|
| 63 |
+
)
|
| 64 |
+
print("[INFO] Model download complete.")
|
| 65 |
+
except Exception as e:
|
| 66 |
+
print(f"[ERROR] Failed to download the model: {e}")
|
| 67 |
+
raise
|
| 68 |
+
else:
|
| 69 |
+
print(f"[INFO] All required model files are present in '{model_dir}'. Skipping download.")
|
| 70 |
+
|
| 71 |
+
# Download model from Hugging Face if not present
|
| 72 |
+
download_model_from_hf(model_repo, model_path, variants, required_file)
|
| 73 |
+
|
| 74 |
+
# Function to initialize the model based on user options
|
| 75 |
+
def initialize_model(variant):
|
| 76 |
+
print(f"[INFO] Initializing model with variant='{variant}', using bf16 precision...")
|
| 77 |
+
|
| 78 |
+
# Determine the correct variant directory
|
| 79 |
+
variant_dir = variants['high'] if variant == '768p' else variants['low']
|
| 80 |
+
base_path = model_path # Pass the base model path
|
| 81 |
+
|
| 82 |
+
print(f"[DEBUG] Model base path: {base_path}")
|
| 83 |
+
|
| 84 |
+
# Verify that config.json exists in the variant directory
|
| 85 |
+
config_path = os.path.join(model_path, variant_dir, 'config.json')
|
| 86 |
+
if not os.path.exists(config_path):
|
| 87 |
+
print(f"[ERROR] config.json not found in '{os.path.join(model_path, variant_dir)}'.")
|
| 88 |
+
raise FileNotFoundError(f"config.json not found in '{os.path.join(model_path, variant_dir)}'.")
|
| 89 |
+
|
| 90 |
+
if model_dtype == "bf16":
|
| 91 |
+
torch_dtype_selected = torch.bfloat16
|
| 92 |
+
else:
|
| 93 |
+
torch_dtype_selected = torch.float32
|
| 94 |
+
|
| 95 |
+
# Initialize the model
|
| 96 |
+
try:
|
| 97 |
+
|
| 98 |
+
model = PyramidDiTForVideoGeneration(
|
| 99 |
+
base_path, # Pass the base model path
|
| 100 |
+
model_name=model_name, # set to pyramid_flux or pyramid_mmdit
|
| 101 |
+
model_dtype=model_dtype, # Use bf16
|
| 102 |
+
model_variant=variant_dir, # Pass the variant directory name
|
| 103 |
+
cpu_offloading=cpu_offloading, # Pass the CPU offloading flag
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
# Always enable tiling for the VAE
|
| 107 |
+
model.vae.enable_tiling()
|
| 108 |
+
|
| 109 |
+
# Remove manual device placement when using CPU offloading
|
| 110 |
+
# The components will be moved to the appropriate devices automatically
|
| 111 |
+
if torch.cuda.is_available():
|
| 112 |
+
torch.cuda.set_device(0)
|
| 113 |
+
# Manual device replacement when not using CPU offloading
|
| 114 |
+
if not cpu_offloading:
|
| 115 |
+
model.vae.to("cuda")
|
| 116 |
+
model.dit.to("cuda")
|
| 117 |
+
model.text_encoder.to("cuda")
|
| 118 |
+
else:
|
| 119 |
+
print("[WARNING] CUDA is not available. Proceeding without GPU.")
|
| 120 |
+
|
| 121 |
+
print("[INFO] Model initialized successfully.")
|
| 122 |
+
return model, torch_dtype_selected
|
| 123 |
+
except Exception as e:
|
| 124 |
+
print(f"[ERROR] Error initializing model: {e}")
|
| 125 |
+
raise
|
| 126 |
+
|
| 127 |
+
# Function to get the model from cache or initialize it
|
| 128 |
+
def initialize_model_cached(variant, seed):
|
| 129 |
+
key = variant
|
| 130 |
+
|
| 131 |
+
if seed == 0:
|
| 132 |
+
seed = random.randint(0, 2**8 - 1)
|
| 133 |
+
torch.manual_seed(seed)
|
| 134 |
+
if torch.cuda.is_available():
|
| 135 |
+
torch.cuda.manual_seed(seed)
|
| 136 |
+
torch.cuda.manual_seed_all(seed)
|
| 137 |
+
|
| 138 |
+
# Check if the model is already in the cache
|
| 139 |
+
if key not in model_cache:
|
| 140 |
+
with model_cache_lock:
|
| 141 |
+
# Double-checked locking to prevent race conditions
|
| 142 |
+
if key not in model_cache:
|
| 143 |
+
model, dtype = initialize_model(variant)
|
| 144 |
+
model_cache[key] = (model, dtype)
|
| 145 |
+
|
| 146 |
+
return model_cache[key]
|
| 147 |
+
|
| 148 |
+
def resize_crop_image(img: PIL.Image.Image, tgt_width, tgt_height):
|
| 149 |
+
ori_width, ori_height = img.width, img.height
|
| 150 |
+
scale = max(tgt_width / ori_width, tgt_height / ori_height)
|
| 151 |
+
resized_width = round(ori_width * scale)
|
| 152 |
+
resized_height = round(ori_height * scale)
|
| 153 |
+
img = img.resize((resized_width, resized_height), resample=PIL.Image.LANCZOS)
|
| 154 |
+
|
| 155 |
+
left = (resized_width - tgt_width) / 2
|
| 156 |
+
top = (resized_height - tgt_height) / 2
|
| 157 |
+
right = (resized_width + tgt_width) / 2
|
| 158 |
+
bottom = (resized_height + tgt_height) / 2
|
| 159 |
+
|
| 160 |
+
# Crop the center of the image
|
| 161 |
+
img = img.crop((left, top, right, bottom))
|
| 162 |
+
|
| 163 |
+
return img
|
| 164 |
+
|
| 165 |
+
# Function to generate text-to-video
|
| 166 |
+
def generate_text_to_video(prompt, temp, guidance_scale, video_guidance_scale, resolution, seed, progress=gr.Progress()):
|
| 167 |
+
progress(0, desc="Loading model")
|
| 168 |
+
print("[DEBUG] generate_text_to_video called.")
|
| 169 |
+
variant = '768p' if resolution == "768p" else '384p'
|
| 170 |
+
height = height_high if resolution == "768p" else height_low
|
| 171 |
+
width = width_high if resolution == "768p" else width_low
|
| 172 |
+
|
| 173 |
+
def progress_callback(i, m):
|
| 174 |
+
progress(i/m)
|
| 175 |
+
|
| 176 |
+
# Initialize model based on user options using cached function
|
| 177 |
+
try:
|
| 178 |
+
model, torch_dtype_selected = initialize_model_cached(variant, seed)
|
| 179 |
+
except Exception as e:
|
| 180 |
+
print(f"[ERROR] Model initialization failed: {e}")
|
| 181 |
+
return f"Model initialization failed: {e}"
|
| 182 |
+
|
| 183 |
+
try:
|
| 184 |
+
print("[INFO] Starting text-to-video generation...")
|
| 185 |
+
with torch.no_grad(), torch.autocast('cuda', dtype=torch_dtype_selected):
|
| 186 |
+
frames = model.generate(
|
| 187 |
+
prompt=prompt,
|
| 188 |
+
num_inference_steps=[20, 20, 20],
|
| 189 |
+
video_num_inference_steps=[10, 10, 10],
|
| 190 |
+
height=height,
|
| 191 |
+
width=width,
|
| 192 |
+
temp=temp,
|
| 193 |
+
guidance_scale=guidance_scale,
|
| 194 |
+
video_guidance_scale=video_guidance_scale,
|
| 195 |
+
output_type="pil",
|
| 196 |
+
cpu_offloading=cpu_offloading,
|
| 197 |
+
save_memory=True,
|
| 198 |
+
callback=progress_callback,
|
| 199 |
+
)
|
| 200 |
+
print("[INFO] Text-to-video generation completed.")
|
| 201 |
+
except Exception as e:
|
| 202 |
+
print(f"[ERROR] Error during text-to-video generation: {e}")
|
| 203 |
+
return f"Error during video generation: {e}"
|
| 204 |
+
|
| 205 |
+
video_path = f"{str(uuid.uuid4())}_text_to_video_sample.mp4"
|
| 206 |
+
try:
|
| 207 |
+
export_to_video(frames, video_path, fps=24)
|
| 208 |
+
print(f"[INFO] Video exported to {video_path}.")
|
| 209 |
+
except Exception as e:
|
| 210 |
+
print(f"[ERROR] Error exporting video: {e}")
|
| 211 |
+
return f"Error exporting video: {e}"
|
| 212 |
+
return video_path
|
| 213 |
+
|
| 214 |
+
# Function to generate image-to-video
|
| 215 |
+
def generate_image_to_video(image, prompt, temp, video_guidance_scale, resolution, seed, progress=gr.Progress()):
|
| 216 |
+
progress(0, desc="Loading model")
|
| 217 |
+
print("[DEBUG] generate_image_to_video called.")
|
| 218 |
+
variant = '768p' if resolution == "768p" else '384p'
|
| 219 |
+
height = height_high if resolution == "768p" else height_low
|
| 220 |
+
width = width_high if resolution == "768p" else width_low
|
| 221 |
+
|
| 222 |
+
try:
|
| 223 |
+
image = resize_crop_image(image, width, height)
|
| 224 |
+
print("[INFO] Image resized and cropped successfully.")
|
| 225 |
+
except Exception as e:
|
| 226 |
+
print(f"[ERROR] Error processing image: {e}")
|
| 227 |
+
return f"Error processing image: {e}"
|
| 228 |
+
|
| 229 |
+
def progress_callback(i, m):
|
| 230 |
+
progress(i/m)
|
| 231 |
+
|
| 232 |
+
# Initialize model based on user options using cached function
|
| 233 |
+
try:
|
| 234 |
+
model, torch_dtype_selected = initialize_model_cached(variant, seed)
|
| 235 |
+
except Exception as e:
|
| 236 |
+
print(f"[ERROR] Model initialization failed: {e}")
|
| 237 |
+
return f"Model initialization failed: {e}"
|
| 238 |
+
|
| 239 |
+
try:
|
| 240 |
+
print("[INFO] Starting image-to-video generation...")
|
| 241 |
+
with torch.no_grad(), torch.autocast('cuda', dtype=torch_dtype_selected):
|
| 242 |
+
frames = model.generate_i2v(
|
| 243 |
+
prompt=prompt,
|
| 244 |
+
input_image=image,
|
| 245 |
+
num_inference_steps=[10, 10, 10],
|
| 246 |
+
temp=temp,
|
| 247 |
+
video_guidance_scale=video_guidance_scale,
|
| 248 |
+
output_type="pil",
|
| 249 |
+
cpu_offloading=cpu_offloading,
|
| 250 |
+
save_memory=True,
|
| 251 |
+
callback=progress_callback,
|
| 252 |
+
)
|
| 253 |
+
print("[INFO] Image-to-video generation completed.")
|
| 254 |
+
except Exception as e:
|
| 255 |
+
print(f"[ERROR] Error during image-to-video generation: {e}")
|
| 256 |
+
return f"Error during video generation: {e}"
|
| 257 |
+
|
| 258 |
+
video_path = f"{str(uuid.uuid4())}_image_to_video_sample.mp4"
|
| 259 |
+
try:
|
| 260 |
+
export_to_video(frames, video_path, fps=24)
|
| 261 |
+
print(f"[INFO] Video exported to {video_path}.")
|
| 262 |
+
except Exception as e:
|
| 263 |
+
print(f"[ERROR] Error exporting video: {e}")
|
| 264 |
+
return f"Error exporting video: {e}"
|
| 265 |
+
return video_path
|
| 266 |
+
|
| 267 |
+
def update_slider(resolution):
|
| 268 |
+
if resolution == "768p":
|
| 269 |
+
return [gr.update(maximum=31), gr.update(maximum=31)]
|
| 270 |
+
else:
|
| 271 |
+
return [gr.update(maximum=16), gr.update(maximum=16)]
|
| 272 |
+
|
| 273 |
+
# Gradio interface
|
| 274 |
+
with gr.Blocks() as demo:
|
| 275 |
+
gr.Markdown(
|
| 276 |
+
"""
|
| 277 |
+
# Pyramid Flow Video Generation Demo
|
| 278 |
+
|
| 279 |
+
Pyramid Flow is a training-efficient **Autoregressive Video Generation** model based on **Flow Matching**. It is trained only on open-source datasets within 20.7k A100 GPU hours.
|
| 280 |
+
|
| 281 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page]](https://pyramid-flow.github.io) [[Code]](https://github.com/jy0205/Pyramid-Flow) [[Model]](https://huggingface.co/rain1011/pyramid-flow-sd3)
|
| 282 |
+
"""
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
# Shared settings
|
| 286 |
+
with gr.Row():
|
| 287 |
+
resolution_dropdown = gr.Dropdown(
|
| 288 |
+
choices=["768p", "384p"],
|
| 289 |
+
value="384p",
|
| 290 |
+
label="Model Resolution"
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
with gr.Tab("Text-to-Video"):
|
| 294 |
+
with gr.Row():
|
| 295 |
+
with gr.Column():
|
| 296 |
+
text_prompt = gr.Textbox(label="Prompt (Less than 128 words)", placeholder="Enter a text prompt for the video", lines=2)
|
| 297 |
+
temp_slider = gr.Slider(1, 16, value=16, step=1, label="Duration")
|
| 298 |
+
guidance_scale_slider = gr.Slider(1.0, 15.0, value=9.0, step=0.1, label="Guidance Scale")
|
| 299 |
+
video_guidance_scale_slider = gr.Slider(1.0, 10.0, value=5.0, step=0.1, label="Video Guidance Scale")
|
| 300 |
+
text_seed = gr.Number(label="Inference Seed (Enter a positive number, 0 for random)", value=0)
|
| 301 |
+
txt_generate = gr.Button("Generate Video")
|
| 302 |
+
with gr.Column():
|
| 303 |
+
txt_output = gr.Video(label="Generated Video")
|
| 304 |
+
gr.Examples(
|
| 305 |
+
examples=[
|
| 306 |
+
["A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors", 16, 7.0, 5.0, "384p"],
|
| 307 |
+
["Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes", 16, 7.0, 5.0, "384p"],
|
| 308 |
+
# ["Extreme close-up of chicken and green pepper kebabs grilling on a barbeque with flames. Shallow focus and light smoke. vivid colours", 31, 9.0, 5.0, "768p"],
|
| 309 |
+
],
|
| 310 |
+
inputs=[text_prompt, temp_slider, guidance_scale_slider, video_guidance_scale_slider, resolution_dropdown, text_seed],
|
| 311 |
+
outputs=[txt_output],
|
| 312 |
+
fn=generate_text_to_video,
|
| 313 |
+
cache_examples='lazy',
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
with gr.Tab("Image-to-Video"):
|
| 317 |
+
with gr.Row():
|
| 318 |
+
with gr.Column():
|
| 319 |
+
image_input = gr.Image(type="pil", label="Input Image")
|
| 320 |
+
image_prompt = gr.Textbox(label="Prompt (Less than 128 words)", placeholder="Enter a text prompt for the video", lines=2)
|
| 321 |
+
image_temp_slider = gr.Slider(2, 16, value=16, step=1, label="Duration")
|
| 322 |
+
image_video_guidance_scale_slider = gr.Slider(1.0, 7.0, value=4.0, step=0.1, label="Video Guidance Scale")
|
| 323 |
+
image_seed = gr.Number(label="Inference Seed (Enter a positive number, 0 for random)", value=0)
|
| 324 |
+
img_generate = gr.Button("Generate Video")
|
| 325 |
+
with gr.Column():
|
| 326 |
+
img_output = gr.Video(label="Generated Video")
|
| 327 |
+
gr.Examples(
|
| 328 |
+
examples=[
|
| 329 |
+
['assets/the_great_wall.jpg', 'FPV flying over the Great Wall', 16, 4.0, "384p"]
|
| 330 |
+
],
|
| 331 |
+
inputs=[image_input, image_prompt, image_temp_slider, image_video_guidance_scale_slider, resolution_dropdown, image_seed],
|
| 332 |
+
outputs=[img_output],
|
| 333 |
+
fn=generate_image_to_video,
|
| 334 |
+
cache_examples='lazy',
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
# Update generate functions to include resolution options
|
| 338 |
+
txt_generate.click(
|
| 339 |
+
generate_text_to_video,
|
| 340 |
+
inputs=[text_prompt, temp_slider, guidance_scale_slider, video_guidance_scale_slider, resolution_dropdown, text_seed],
|
| 341 |
+
outputs=txt_output
|
| 342 |
+
)
|
| 343 |
+
|
| 344 |
+
img_generate.click(
|
| 345 |
+
generate_image_to_video,
|
| 346 |
+
inputs=[image_input, image_prompt, image_temp_slider, image_video_guidance_scale_slider, resolution_dropdown, image_seed],
|
| 347 |
+
outputs=img_output
|
| 348 |
+
)
|
| 349 |
+
resolution_dropdown.change(
|
| 350 |
+
fn=update_slider,
|
| 351 |
+
inputs=resolution_dropdown,
|
| 352 |
+
outputs=[temp_slider, image_temp_slider]
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
# Launch Gradio app
|
| 356 |
+
demo.launch(share=False)
|
app_multigpu.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import uuid
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import subprocess
|
| 5 |
+
import tempfile
|
| 6 |
+
import shutil
|
| 7 |
+
|
| 8 |
+
def run_inference_multigpu(gpus, variant, model_path, temp, guidance_scale, video_guidance_scale, resolution, prompt):
|
| 9 |
+
"""
|
| 10 |
+
Runs the external multi-GPU inference script and returns the path to the generated video.
|
| 11 |
+
"""
|
| 12 |
+
# Create a temporary directory to store inputs and outputs
|
| 13 |
+
with tempfile.TemporaryDirectory() as tmpdir:
|
| 14 |
+
output_video = os.path.join(tmpdir, f"{uuid.uuid4()}_output.mp4")
|
| 15 |
+
|
| 16 |
+
# Path to the external shell script
|
| 17 |
+
script_path = "./scripts/app_multigpu_engine.sh" # Updated script path
|
| 18 |
+
|
| 19 |
+
# Prepare the command
|
| 20 |
+
cmd = [
|
| 21 |
+
script_path,
|
| 22 |
+
str(gpus),
|
| 23 |
+
variant,
|
| 24 |
+
model_path,
|
| 25 |
+
't2v', # Task is always 't2v' since 'i2v' is removed
|
| 26 |
+
str(temp),
|
| 27 |
+
str(guidance_scale),
|
| 28 |
+
str(video_guidance_scale),
|
| 29 |
+
resolution,
|
| 30 |
+
output_video,
|
| 31 |
+
prompt # Pass the prompt directly as an argument
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
try:
|
| 35 |
+
# Run the external script
|
| 36 |
+
subprocess.run(cmd, check=True)
|
| 37 |
+
except subprocess.CalledProcessError as e:
|
| 38 |
+
raise RuntimeError(f"Error during video generation: {e}")
|
| 39 |
+
|
| 40 |
+
# After generation, move the video to a permanent location
|
| 41 |
+
final_output = os.path.join("generated_videos", f"{uuid.uuid4()}_output.mp4")
|
| 42 |
+
os.makedirs("generated_videos", exist_ok=True)
|
| 43 |
+
shutil.move(output_video, final_output)
|
| 44 |
+
|
| 45 |
+
return final_output
|
| 46 |
+
|
| 47 |
+
def generate_text_to_video(prompt, temp, guidance_scale, video_guidance_scale, resolution, gpus):
|
| 48 |
+
model_path = "./pyramid_flow_model" # Use the model path as specified
|
| 49 |
+
# Determine variant based on resolution
|
| 50 |
+
if resolution == "768p":
|
| 51 |
+
variant = "diffusion_transformer_768p"
|
| 52 |
+
else:
|
| 53 |
+
variant = "diffusion_transformer_384p"
|
| 54 |
+
return run_inference_multigpu(gpus, variant, model_path, temp, guidance_scale, video_guidance_scale, resolution, prompt)
|
| 55 |
+
|
| 56 |
+
# Gradio interface
|
| 57 |
+
with gr.Blocks() as demo:
|
| 58 |
+
gr.Markdown(
|
| 59 |
+
"""
|
| 60 |
+
# Pyramid Flow Video Generation Demo
|
| 61 |
+
|
| 62 |
+
Pyramid Flow is a training-efficient **Autoregressive Video Generation** model based on **Flow Matching**. It is trained only on open-source datasets within 20.7k A100 GPU hours.
|
| 63 |
+
|
| 64 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page]](https://pyramid-flow.github.io) [[Code]](https://github.com/jy0205/Pyramid-Flow) [[Model]](https://huggingface.co/rain1011/pyramid-flow-sd3)
|
| 65 |
+
"""
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
# Shared settings
|
| 69 |
+
with gr.Row():
|
| 70 |
+
gpus_dropdown = gr.Dropdown(
|
| 71 |
+
choices=[2, 4],
|
| 72 |
+
value=4,
|
| 73 |
+
label="Number of GPUs"
|
| 74 |
+
)
|
| 75 |
+
resolution_dropdown = gr.Dropdown(
|
| 76 |
+
choices=["768p", "384p"],
|
| 77 |
+
value="768p",
|
| 78 |
+
label="Model Resolution"
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
with gr.Tab("Text-to-Video"):
|
| 82 |
+
with gr.Row():
|
| 83 |
+
with gr.Column():
|
| 84 |
+
text_prompt = gr.Textbox(
|
| 85 |
+
label="Prompt (Less than 128 words)",
|
| 86 |
+
placeholder="Enter a text prompt for the video",
|
| 87 |
+
lines=2
|
| 88 |
+
)
|
| 89 |
+
temp_slider = gr.Slider(1, 31, value=16, step=1, label="Duration")
|
| 90 |
+
guidance_scale_slider = gr.Slider(1.0, 15.0, value=9.0, step=0.1, label="Guidance Scale")
|
| 91 |
+
video_guidance_scale_slider = gr.Slider(1.0, 10.0, value=5.0, step=0.1, label="Video Guidance Scale")
|
| 92 |
+
txt_generate = gr.Button("Generate Video")
|
| 93 |
+
with gr.Column():
|
| 94 |
+
txt_output = gr.Video(label="Generated Video")
|
| 95 |
+
gr.Examples(
|
| 96 |
+
examples=[
|
| 97 |
+
[
|
| 98 |
+
"A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors",
|
| 99 |
+
16,
|
| 100 |
+
9.0,
|
| 101 |
+
5.0,
|
| 102 |
+
"768p",
|
| 103 |
+
4
|
| 104 |
+
],
|
| 105 |
+
[
|
| 106 |
+
"Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes",
|
| 107 |
+
16,
|
| 108 |
+
9.0,
|
| 109 |
+
5.0,
|
| 110 |
+
"768p",
|
| 111 |
+
4
|
| 112 |
+
],
|
| 113 |
+
[
|
| 114 |
+
"Extreme close-up of chicken and green pepper kebabs grilling on a barbeque with flames. Shallow focus and light smoke. vivid colours",
|
| 115 |
+
31,
|
| 116 |
+
9.0,
|
| 117 |
+
5.0,
|
| 118 |
+
"768p",
|
| 119 |
+
4
|
| 120 |
+
],
|
| 121 |
+
],
|
| 122 |
+
inputs=[text_prompt, temp_slider, guidance_scale_slider, video_guidance_scale_slider, resolution_dropdown, gpus_dropdown],
|
| 123 |
+
outputs=[txt_output],
|
| 124 |
+
fn=generate_text_to_video,
|
| 125 |
+
cache_examples='lazy',
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
# Update generate function for Text-to-Video
|
| 129 |
+
txt_generate.click(
|
| 130 |
+
generate_text_to_video,
|
| 131 |
+
inputs=[
|
| 132 |
+
text_prompt,
|
| 133 |
+
temp_slider,
|
| 134 |
+
guidance_scale_slider,
|
| 135 |
+
video_guidance_scale_slider,
|
| 136 |
+
resolution_dropdown,
|
| 137 |
+
gpus_dropdown
|
| 138 |
+
],
|
| 139 |
+
outputs=txt_output
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
# Launch Gradio app
|
| 143 |
+
demo.launch(share=False)
|
assets/motivation.jpg
ADDED

|
assets/the_great_wall.jpg
ADDED

|
assets/user_study.jpg
ADDED
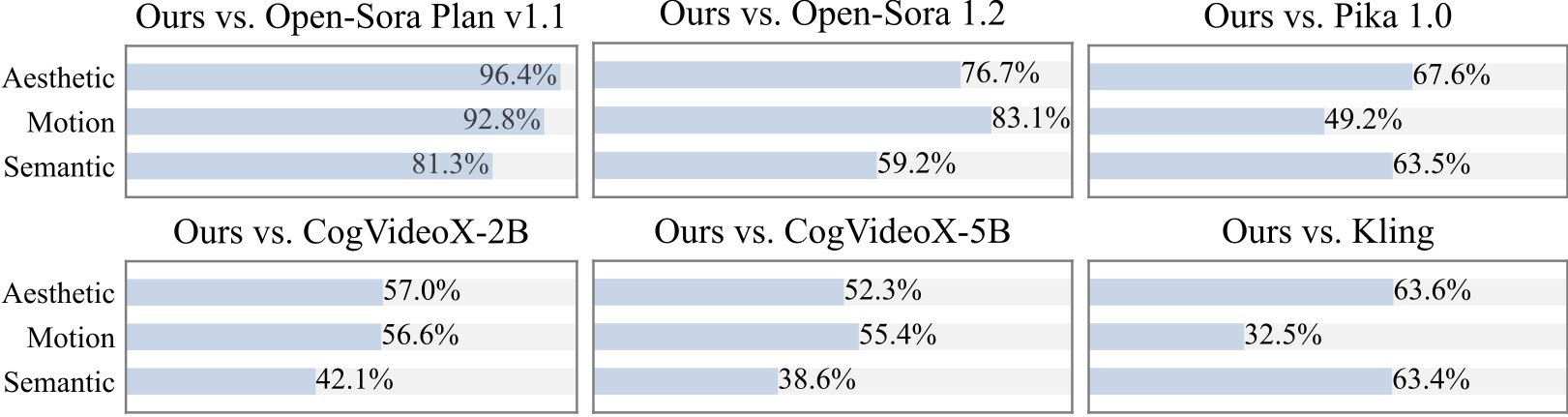
|
assets/vbench.jpg
ADDED

|
causal_video_vae_demo.ipynb
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import os\n",
|
| 10 |
+
"import json\n",
|
| 11 |
+
"import cv2\n",
|
| 12 |
+
"import torch\n",
|
| 13 |
+
"import numpy as np\n",
|
| 14 |
+
"import PIL\n",
|
| 15 |
+
"from PIL import Image\n",
|
| 16 |
+
"from einops import rearrange\n",
|
| 17 |
+
"from video_vae import CausalVideoVAELossWrapper\n",
|
| 18 |
+
"from torchvision import transforms as pth_transforms\n",
|
| 19 |
+
"from torchvision.transforms.functional import InterpolationMode\n",
|
| 20 |
+
"from IPython.display import Image as ipython_image\n",
|
| 21 |
+
"from diffusers.utils import load_image, export_to_video, export_to_gif\n",
|
| 22 |
+
"from IPython.display import HTML"
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"cell_type": "code",
|
| 27 |
+
"execution_count": null,
|
| 28 |
+
"metadata": {},
|
| 29 |
+
"outputs": [],
|
| 30 |
+
"source": [
|
| 31 |
+
"model_path = \"pyramid-flow-miniflux/causal_video_vae\" # The video-vae checkpoint dir\n",
|
| 32 |
+
"model_dtype = 'bf16'\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"device_id = 3\n",
|
| 35 |
+
"torch.cuda.set_device(device_id)\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"model = CausalVideoVAELossWrapper(\n",
|
| 38 |
+
" model_path,\n",
|
| 39 |
+
" model_dtype,\n",
|
| 40 |
+
" interpolate=False, \n",
|
| 41 |
+
" add_discriminator=False,\n",
|
| 42 |
+
")\n",
|
| 43 |
+
"model = model.to(\"cuda\")\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"if model_dtype == \"bf16\":\n",
|
| 46 |
+
" torch_dtype = torch.bfloat16 \n",
|
| 47 |
+
"elif model_dtype == \"fp16\":\n",
|
| 48 |
+
" torch_dtype = torch.float16\n",
|
| 49 |
+
"else:\n",
|
| 50 |
+
" torch_dtype = torch.float32\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"def image_transform(images, resize_width, resize_height):\n",
|
| 53 |
+
" transform_list = pth_transforms.Compose([\n",
|
| 54 |
+
" pth_transforms.Resize((resize_height, resize_width), InterpolationMode.BICUBIC, antialias=True),\n",
|
| 55 |
+
" pth_transforms.ToTensor(),\n",
|
| 56 |
+
" pth_transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n",
|
| 57 |
+
" ])\n",
|
| 58 |
+
" return torch.stack([transform_list(image) for image in images])\n",
|
| 59 |
+
"\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"def get_transform(width, height, new_width=None, new_height=None, resize=False,):\n",
|
| 62 |
+
" transform_list = []\n",
|
| 63 |
+
"\n",
|
| 64 |
+
" if resize:\n",
|
| 65 |
+
" if new_width is None:\n",
|
| 66 |
+
" new_width = width // 8 * 8\n",
|
| 67 |
+
" if new_height is None:\n",
|
| 68 |
+
" new_height = height // 8 * 8\n",
|
| 69 |
+
" transform_list.append(pth_transforms.Resize((new_height, new_width), InterpolationMode.BICUBIC, antialias=True))\n",
|
| 70 |
+
" \n",
|
| 71 |
+
" transform_list.extend([\n",
|
| 72 |
+
" pth_transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n",
|
| 73 |
+
" ])\n",
|
| 74 |
+
" transform_list = pth_transforms.Compose(transform_list)\n",
|
| 75 |
+
"\n",
|
| 76 |
+
" return transform_list\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"def load_video_and_transform(video_path, frame_number, new_width=None, new_height=None, max_frames=600, sample_fps=24, resize=False):\n",
|
| 80 |
+
" try:\n",
|
| 81 |
+
" video_capture = cv2.VideoCapture(video_path)\n",
|
| 82 |
+
" fps = video_capture.get(cv2.CAP_PROP_FPS)\n",
|
| 83 |
+
" frames = []\n",
|
| 84 |
+
" pil_frames = []\n",
|
| 85 |
+
" while True:\n",
|
| 86 |
+
" flag, frame = video_capture.read()\n",
|
| 87 |
+
" if not flag:\n",
|
| 88 |
+
" break\n",
|
| 89 |
+
" \n",
|
| 90 |
+
" pil_frames.append(np.ascontiguousarray(frame[:, :, ::-1]))\n",
|
| 91 |
+
" frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n",
|
| 92 |
+
" frame = torch.from_numpy(frame)\n",
|
| 93 |
+
" frame = frame.permute(2, 0, 1)\n",
|
| 94 |
+
" frames.append(frame)\n",
|
| 95 |
+
" if len(frames) >= max_frames:\n",
|
| 96 |
+
" break\n",
|
| 97 |
+
"\n",
|
| 98 |
+
" video_capture.release()\n",
|
| 99 |
+
" interval = max(int(fps / sample_fps), 1)\n",
|
| 100 |
+
" pil_frames = pil_frames[::interval][:frame_number]\n",
|
| 101 |
+
" frames = frames[::interval][:frame_number]\n",
|
| 102 |
+
" frames = torch.stack(frames).float() / 255\n",
|
| 103 |
+
" width = frames.shape[-1]\n",
|
| 104 |
+
" height = frames.shape[-2]\n",
|
| 105 |
+
" video_transform = get_transform(width, height, new_width, new_height, resize=resize)\n",
|
| 106 |
+
" frames = video_transform(frames)\n",
|
| 107 |
+
" pil_frames = [Image.fromarray(frame).convert(\"RGB\") for frame in pil_frames]\n",
|
| 108 |
+
"\n",
|
| 109 |
+
" if resize:\n",
|
| 110 |
+
" if new_width is None:\n",
|
| 111 |
+
" new_width = width // 32 * 32\n",
|
| 112 |
+
" if new_height is None:\n",
|
| 113 |
+
" new_height = height // 32 * 32\n",
|
| 114 |
+
" pil_frames = [frame.resize((new_width or width, new_height or height), PIL.Image.BICUBIC) for frame in pil_frames]\n",
|
| 115 |
+
" return frames, pil_frames\n",
|
| 116 |
+
" except Exception:\n",
|
| 117 |
+
" return None\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"\n",
|
| 120 |
+
"def show_video(ori_path, rec_path, width=\"100%\"):\n",
|
| 121 |
+
" html = ''\n",
|
| 122 |
+
" if ori_path is not None:\n",
|
| 123 |
+
" html += f\"\"\"<video controls=\"\" name=\"media\" data-fullscreen-container=\"true\" width=\"{width}\">\n",
|
| 124 |
+
" <source src=\"{ori_path}\" type=\"video/mp4\">\n",
|
| 125 |
+
" </video>\n",
|
| 126 |
+
" \"\"\"\n",
|
| 127 |
+
" \n",
|
| 128 |
+
" html += f\"\"\"<video controls=\"\" name=\"media\" data-fullscreen-container=\"true\" width=\"{width}\">\n",
|
| 129 |
+
" <source src=\"{rec_path}\" type=\"video/mp4\">\n",
|
| 130 |
+
" </video>\n",
|
| 131 |
+
" \"\"\"\n",
|
| 132 |
+
" return HTML(html)"
|
| 133 |
+
]
|
| 134 |
+
},
|
| 135 |
+
{
|
| 136 |
+
"attachments": {},
|
| 137 |
+
"cell_type": "markdown",
|
| 138 |
+
"metadata": {},
|
| 139 |
+
"source": [
|
| 140 |
+
"### Image Reconstruction"
|
| 141 |
+
]
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"cell_type": "code",
|
| 145 |
+
"execution_count": null,
|
| 146 |
+
"metadata": {},
|
| 147 |
+
"outputs": [],
|
| 148 |
+
"source": [
|
| 149 |
+
"image_path = 'image_path'\n",
|
| 150 |
+
"\n",
|
| 151 |
+
"image = Image.open(image_path).convert(\"RGB\")\n",
|
| 152 |
+
"resize_width = image.width // 8 * 8\n",
|
| 153 |
+
"resize_height = image.height // 8 * 8\n",
|
| 154 |
+
"input_image_tensor = image_transform([image], resize_width, resize_height)\n",
|
| 155 |
+
"input_image_tensor = input_image_tensor.permute(1, 0, 2, 3).unsqueeze(0)\n",
|
| 156 |
+
"\n",
|
| 157 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):\n",
|
| 158 |
+
" latent = model.encode_latent(input_image_tensor.to(\"cuda\"), sample=True)\n",
|
| 159 |
+
" rec_images = model.decode_latent(latent)\n",
|
| 160 |
+
"\n",
|
| 161 |
+
"display(image)\n",
|
| 162 |
+
"display(rec_images[0])"
|
| 163 |
+
]
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"attachments": {},
|
| 167 |
+
"cell_type": "markdown",
|
| 168 |
+
"metadata": {},
|
| 169 |
+
"source": [
|
| 170 |
+
"### Video Reconstruction"
|
| 171 |
+
]
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"cell_type": "code",
|
| 175 |
+
"execution_count": null,
|
| 176 |
+
"metadata": {},
|
| 177 |
+
"outputs": [],
|
| 178 |
+
"source": [
|
| 179 |
+
"video_path = 'video_path'\n",
|
| 180 |
+
"\n",
|
| 181 |
+
"frame_number = 57 # x*8 + 1\n",
|
| 182 |
+
"width = 640\n",
|
| 183 |
+
"height = 384\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"video_frames_tensor, pil_video_frames = load_video_and_transform(video_path, frame_number, new_width=width, new_height=height, resize=True)\n",
|
| 186 |
+
"video_frames_tensor = video_frames_tensor.permute(1, 0, 2, 3).unsqueeze(0)\n",
|
| 187 |
+
"print(video_frames_tensor.shape)\n",
|
| 188 |
+
"\n",
|
| 189 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):\n",
|
| 190 |
+
" latent = model.encode_latent(video_frames_tensor.to(\"cuda\"), sample=False, window_size=8, temporal_chunk=True)\n",
|
| 191 |
+
" rec_frames = model.decode_latent(latent.float(), window_size=2, temporal_chunk=True)\n",
|
| 192 |
+
"\n",
|
| 193 |
+
"export_to_video(pil_video_frames, './ori_video.mp4', fps=24)\n",
|
| 194 |
+
"export_to_video(rec_frames, \"./rec_video.mp4\", fps=24)\n",
|
| 195 |
+
"show_video('./ori_video.mp4', \"./rec_video.mp4\", \"60%\")"
|
| 196 |
+
]
|
| 197 |
+
}
|
| 198 |
+
],
|
| 199 |
+
"metadata": {
|
| 200 |
+
"kernelspec": {
|
| 201 |
+
"display_name": "Python 3",
|
| 202 |
+
"language": "python",
|
| 203 |
+
"name": "python3"
|
| 204 |
+
},
|
| 205 |
+
"language_info": {
|
| 206 |
+
"codemirror_mode": {
|
| 207 |
+
"name": "ipython",
|
| 208 |
+
"version": 3
|
| 209 |
+
},
|
| 210 |
+
"file_extension": ".py",
|
| 211 |
+
"mimetype": "text/x-python",
|
| 212 |
+
"name": "python",
|
| 213 |
+
"nbconvert_exporter": "python",
|
| 214 |
+
"pygments_lexer": "ipython3",
|
| 215 |
+
"version": "3.8.10"
|
| 216 |
+
},
|
| 217 |
+
"orig_nbformat": 4
|
| 218 |
+
},
|
| 219 |
+
"nbformat": 4,
|
| 220 |
+
"nbformat_minor": 2
|
| 221 |
+
}
|
dataset/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .dataset_cls import (
|
| 2 |
+
ImageTextDataset,
|
| 3 |
+
LengthGroupedVideoTextDataset,
|
| 4 |
+
ImageDataset,
|
| 5 |
+
VideoDataset,
|
| 6 |
+
)
|
| 7 |
+
|
| 8 |
+
from .dataloaders import (
|
| 9 |
+
create_image_text_dataloaders,
|
| 10 |
+
create_length_grouped_video_text_dataloader,
|
| 11 |
+
create_mixed_dataloaders,
|
| 12 |
+
)
|
dataset/bucket_loader.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torchvision
|
| 3 |
+
import numpy as np
|
| 4 |
+
import math
|
| 5 |
+
import random
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Bucketeer:
|
| 10 |
+
def __init__(
|
| 11 |
+
self, dataloader,
|
| 12 |
+
sizes=[(256, 256), (192, 384), (192, 320), (384, 192), (320, 192)],
|
| 13 |
+
is_infinite=True, epoch=0,
|
| 14 |
+
):
|
| 15 |
+
# Ratios and Sizes : (w h)
|
| 16 |
+
self.sizes = sizes
|
| 17 |
+
self.batch_size = dataloader.batch_size
|
| 18 |
+
self._dataloader = dataloader
|
| 19 |
+
self.iterator = iter(dataloader)
|
| 20 |
+
self.sampler = dataloader.sampler
|
| 21 |
+
self.buckets = {s: [] for s in self.sizes}
|
| 22 |
+
self.is_infinite = is_infinite
|
| 23 |
+
self._epoch = epoch
|
| 24 |
+
|
| 25 |
+
def get_available_batch(self):
|
| 26 |
+
available_size = []
|
| 27 |
+
for b in self.buckets:
|
| 28 |
+
if len(self.buckets[b]) >= self.batch_size:
|
| 29 |
+
available_size.append(b)
|
| 30 |
+
|
| 31 |
+
if len(available_size) == 0:
|
| 32 |
+
return None
|
| 33 |
+
else:
|
| 34 |
+
b = random.choice(available_size)
|
| 35 |
+
batch = self.buckets[b][:self.batch_size]
|
| 36 |
+
self.buckets[b] = self.buckets[b][self.batch_size:]
|
| 37 |
+
return batch
|
| 38 |
+
|
| 39 |
+
def __next__(self):
|
| 40 |
+
batch = self.get_available_batch()
|
| 41 |
+
while batch is None:
|
| 42 |
+
try:
|
| 43 |
+
elements = next(self.iterator)
|
| 44 |
+
except StopIteration:
|
| 45 |
+
# To make it infinity
|
| 46 |
+
if self.is_infinite:
|
| 47 |
+
self._epoch += 1
|
| 48 |
+
if hasattr(self._dataloader.sampler, "set_epoch"):
|
| 49 |
+
self._dataloader.sampler.set_epoch(self._epoch)
|
| 50 |
+
time.sleep(2) # Prevent possible deadlock during epoch transition
|
| 51 |
+
self.iterator = iter(self._dataloader)
|
| 52 |
+
elements = next(self.iterator)
|
| 53 |
+
else:
|
| 54 |
+
raise StopIteration
|
| 55 |
+
|
| 56 |
+
for dct in elements:
|
| 57 |
+
try:
|
| 58 |
+
img = dct['video']
|
| 59 |
+
size = (img.shape[-1], img.shape[-2])
|
| 60 |
+
self.buckets[size].append({**{'video': img}, **{k:dct[k] for k in dct if k != 'video'}})
|
| 61 |
+
except Exception as e:
|
| 62 |
+
continue
|
| 63 |
+
|
| 64 |
+
batch = self.get_available_batch()
|
| 65 |
+
|
| 66 |
+
out = {k:[batch[i][k] for i in range(len(batch))] for k in batch[0]}
|
| 67 |
+
return {k: torch.stack(o, dim=0) if isinstance(o[0], torch.Tensor) else o for k, o in out.items()}
|
| 68 |
+
|
| 69 |
+
def __iter__(self):
|
| 70 |
+
return self
|
| 71 |
+
|
| 72 |
+
def __len__(self):
|
| 73 |
+
return len(self.iterator)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class TemporalLengthBucketeer:
|
| 77 |
+
def __init__(
|
| 78 |
+
self, dataloader, max_frames=16, epoch=0,
|
| 79 |
+
):
|
| 80 |
+
self.batch_size = dataloader.batch_size
|
| 81 |
+
self._dataloader = dataloader
|
| 82 |
+
self.iterator = iter(dataloader)
|
| 83 |
+
self.buckets = {temp: [] for temp in range(1, max_frames + 1)}
|
| 84 |
+
self._epoch = epoch
|
| 85 |
+
|
| 86 |
+
def get_available_batch(self):
|
| 87 |
+
available_size = []
|
| 88 |
+
for b in self.buckets:
|
| 89 |
+
if len(self.buckets[b]) >= self.batch_size:
|
| 90 |
+
available_size.append(b)
|
| 91 |
+
|
| 92 |
+
if len(available_size) == 0:
|
| 93 |
+
return None
|
| 94 |
+
else:
|
| 95 |
+
b = random.choice(available_size)
|
| 96 |
+
batch = self.buckets[b][:self.batch_size]
|
| 97 |
+
self.buckets[b] = self.buckets[b][self.batch_size:]
|
| 98 |
+
return batch
|
| 99 |
+
|
| 100 |
+
def __next__(self):
|
| 101 |
+
batch = self.get_available_batch()
|
| 102 |
+
while batch is None:
|
| 103 |
+
try:
|
| 104 |
+
elements = next(self.iterator)
|
| 105 |
+
except StopIteration:
|
| 106 |
+
# To make it infinity
|
| 107 |
+
self._epoch += 1
|
| 108 |
+
if hasattr(self._dataloader.sampler, "set_epoch"):
|
| 109 |
+
self._dataloader.sampler.set_epoch(self._epoch)
|
| 110 |
+
time.sleep(2) # Prevent possible deadlock during epoch transition
|
| 111 |
+
self.iterator = iter(self._dataloader)
|
| 112 |
+
elements = next(self.iterator)
|
| 113 |
+
|
| 114 |
+
for dct in elements:
|
| 115 |
+
try:
|
| 116 |
+
video_latent = dct['video']
|
| 117 |
+
temp = video_latent.shape[2]
|
| 118 |
+
self.buckets[temp].append({**{'video': video_latent}, **{k:dct[k] for k in dct if k != 'video'}})
|
| 119 |
+
except Exception as e:
|
| 120 |
+
continue
|
| 121 |
+
|
| 122 |
+
batch = self.get_available_batch()
|
| 123 |
+
|
| 124 |
+
out = {k:[batch[i][k] for i in range(len(batch))] for k in batch[0]}
|
| 125 |
+
out = {k: torch.cat(o, dim=0) if isinstance(o[0], torch.Tensor) else o for k, o in out.items()}
|
| 126 |
+
|
| 127 |
+
if 'prompt_embed' in out:
|
| 128 |
+
# Loading the pre-extrcted textual features
|
| 129 |
+
prompt_embeds = out['prompt_embed'].clone()
|
| 130 |
+
del out['prompt_embed']
|
| 131 |
+
prompt_attention_mask = out['prompt_attention_mask'].clone()
|
| 132 |
+
del out['prompt_attention_mask']
|
| 133 |
+
pooled_prompt_embeds = out['pooled_prompt_embed'].clone()
|
| 134 |
+
del out['pooled_prompt_embed']
|
| 135 |
+
|
| 136 |
+
out['text'] = {
|
| 137 |
+
'prompt_embeds' : prompt_embeds,
|
| 138 |
+
'prompt_attention_mask': prompt_attention_mask,
|
| 139 |
+
'pooled_prompt_embeds': pooled_prompt_embeds,
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
return out
|
| 143 |
+
|
| 144 |
+
def __iter__(self):
|
| 145 |
+
return self
|
| 146 |
+
|
| 147 |
+
def __len__(self):
|
| 148 |
+
return len(self.iterator)
|
dataset/dataloaders.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import torch
|
| 4 |
+
import time
|
| 5 |
+
import random
|
| 6 |
+
from typing import Iterable
|
| 7 |
+
|
| 8 |
+
from collections import OrderedDict
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from torch.utils.data import Dataset, DataLoader, ConcatDataset, IterableDataset, DistributedSampler, RandomSampler
|
| 11 |
+
from torch.utils.data.dataloader import default_collate
|
| 12 |
+
from torchvision import transforms
|
| 13 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 14 |
+
from torchvision.transforms import functional as F
|
| 15 |
+
from .bucket_loader import Bucketeer, TemporalLengthBucketeer
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class IterLoader:
|
| 19 |
+
"""
|
| 20 |
+
A wrapper to convert DataLoader as an infinite iterator.
|
| 21 |
+
|
| 22 |
+
Modified from:
|
| 23 |
+
https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/iter_based_runner.py
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
def __init__(self, dataloader: DataLoader, use_distributed: bool = False, epoch: int = 0):
|
| 27 |
+
self._dataloader = dataloader
|
| 28 |
+
self.iter_loader = iter(self._dataloader)
|
| 29 |
+
self._use_distributed = use_distributed
|
| 30 |
+
self._epoch = epoch
|
| 31 |
+
|
| 32 |
+
@property
|
| 33 |
+
def epoch(self) -> int:
|
| 34 |
+
return self._epoch
|
| 35 |
+
|
| 36 |
+
def __next__(self):
|
| 37 |
+
try:
|
| 38 |
+
data = next(self.iter_loader)
|
| 39 |
+
except StopIteration:
|
| 40 |
+
self._epoch += 1
|
| 41 |
+
if hasattr(self._dataloader.sampler, "set_epoch") and self._use_distributed:
|
| 42 |
+
self._dataloader.sampler.set_epoch(self._epoch)
|
| 43 |
+
time.sleep(2) # Prevent possible deadlock during epoch transition
|
| 44 |
+
self.iter_loader = iter(self._dataloader)
|
| 45 |
+
data = next(self.iter_loader)
|
| 46 |
+
|
| 47 |
+
return data
|
| 48 |
+
|
| 49 |
+
def __iter__(self):
|
| 50 |
+
return self
|
| 51 |
+
|
| 52 |
+
def __len__(self):
|
| 53 |
+
return len(self._dataloader)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def identity(x):
|
| 57 |
+
return x
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def create_image_text_dataloaders(dataset, batch_size, num_workers,
|
| 61 |
+
multi_aspect_ratio=True, epoch=0, sizes=[(512, 512), (384, 640), (640, 384)],
|
| 62 |
+
use_distributed=True, world_size=None, rank=None,
|
| 63 |
+
):
|
| 64 |
+
"""
|
| 65 |
+
The dataset has already been splited by different rank
|
| 66 |
+
"""
|
| 67 |
+
if use_distributed:
|
| 68 |
+
assert world_size is not None
|
| 69 |
+
assert rank is not None
|
| 70 |
+
sampler = DistributedSampler(
|
| 71 |
+
dataset,
|
| 72 |
+
shuffle=True,
|
| 73 |
+
num_replicas=world_size,
|
| 74 |
+
rank=rank,
|
| 75 |
+
seed=epoch,
|
| 76 |
+
)
|
| 77 |
+
else:
|
| 78 |
+
sampler = RandomSampler(dataset)
|
| 79 |
+
|
| 80 |
+
dataloader = DataLoader(
|
| 81 |
+
dataset,
|
| 82 |
+
batch_size=batch_size,
|
| 83 |
+
num_workers=num_workers,
|
| 84 |
+
pin_memory=True,
|
| 85 |
+
sampler=sampler,
|
| 86 |
+
collate_fn=identity if multi_aspect_ratio else default_collate,
|
| 87 |
+
drop_last=True,
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
if multi_aspect_ratio:
|
| 91 |
+
dataloader_iterator = Bucketeer(
|
| 92 |
+
dataloader,
|
| 93 |
+
sizes=sizes,
|
| 94 |
+
is_infinite=True, epoch=epoch,
|
| 95 |
+
)
|
| 96 |
+
else:
|
| 97 |
+
dataloader_iterator = iter(dataloader)
|
| 98 |
+
|
| 99 |
+
# To make it infinite
|
| 100 |
+
loader = IterLoader(dataloader_iterator, use_distributed=False, epoch=epoch)
|
| 101 |
+
|
| 102 |
+
return loader
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def create_length_grouped_video_text_dataloader(dataset, batch_size, num_workers, max_frames,
|
| 106 |
+
world_size=None, rank=None, epoch=0, use_distributed=False):
|
| 107 |
+
if use_distributed:
|
| 108 |
+
assert world_size is not None
|
| 109 |
+
assert rank is not None
|
| 110 |
+
sampler = DistributedSampler(
|
| 111 |
+
dataset,
|
| 112 |
+
shuffle=True,
|
| 113 |
+
num_replicas=world_size,
|
| 114 |
+
rank=rank,
|
| 115 |
+
seed=epoch,
|
| 116 |
+
)
|
| 117 |
+
else:
|
| 118 |
+
sampler = RandomSampler(dataset)
|
| 119 |
+
|
| 120 |
+
dataloader = DataLoader(
|
| 121 |
+
dataset,
|
| 122 |
+
batch_size=batch_size,
|
| 123 |
+
num_workers=num_workers,
|
| 124 |
+
pin_memory=True,
|
| 125 |
+
sampler=sampler,
|
| 126 |
+
collate_fn=identity,
|
| 127 |
+
drop_last=True,
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
# make it infinite
|
| 131 |
+
dataloader_iterator = TemporalLengthBucketeer(
|
| 132 |
+
dataloader,
|
| 133 |
+
max_frames=max_frames,
|
| 134 |
+
epoch=epoch,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
return dataloader_iterator
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def create_mixed_dataloaders(
|
| 141 |
+
dataset, batch_size, num_workers, world_size=None, rank=None, epoch=0,
|
| 142 |
+
image_mix_ratio=0.1, use_image_video_mixed_training=True,
|
| 143 |
+
):
|
| 144 |
+
"""
|
| 145 |
+
The video & image mixed training dataloader builder
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
assert world_size is not None
|
| 149 |
+
assert rank is not None
|
| 150 |
+
|
| 151 |
+
image_gpus = max(1, int(world_size * image_mix_ratio))
|
| 152 |
+
if use_image_video_mixed_training:
|
| 153 |
+
video_gpus = world_size - image_gpus
|
| 154 |
+
else:
|
| 155 |
+
# only use video data
|
| 156 |
+
video_gpus = world_size
|
| 157 |
+
image_gpus = 0
|
| 158 |
+
|
| 159 |
+
print(f"{image_gpus} gpus for image, {video_gpus} gpus for video")
|
| 160 |
+
|
| 161 |
+
if rank < video_gpus:
|
| 162 |
+
sampler = DistributedSampler(
|
| 163 |
+
dataset,
|
| 164 |
+
shuffle=True,
|
| 165 |
+
num_replicas=video_gpus,
|
| 166 |
+
rank=rank,
|
| 167 |
+
seed=epoch,
|
| 168 |
+
)
|
| 169 |
+
else:
|
| 170 |
+
sampler = DistributedSampler(
|
| 171 |
+
dataset,
|
| 172 |
+
shuffle=True,
|
| 173 |
+
num_replicas=image_gpus,
|
| 174 |
+
rank=rank - video_gpus,
|
| 175 |
+
seed=epoch,
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
loader = DataLoader(
|
| 179 |
+
dataset,
|
| 180 |
+
batch_size=batch_size,
|
| 181 |
+
num_workers=num_workers,
|
| 182 |
+
pin_memory=True,
|
| 183 |
+
sampler=sampler,
|
| 184 |
+
collate_fn=default_collate,
|
| 185 |
+
drop_last=True,
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
# To make it infinite
|
| 189 |
+
loader = IterLoader(loader, use_distributed=True, epoch=epoch)
|
| 190 |
+
return loader
|
dataset/dataset_cls.py
ADDED
|
@@ -0,0 +1,377 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import jsonlines
|
| 4 |
+
import torch
|
| 5 |
+
import math
|
| 6 |
+
import random
|
| 7 |
+
import cv2
|
| 8 |
+
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
from collections import OrderedDict
|
| 11 |
+
|
| 12 |
+
from PIL import Image
|
| 13 |
+
from PIL import ImageFile
|
| 14 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 15 |
+
|
| 16 |
+
import numpy as np
|
| 17 |
+
import subprocess
|
| 18 |
+
from torch.utils.data import Dataset, DataLoader
|
| 19 |
+
from torchvision import transforms
|
| 20 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 21 |
+
from torchvision.transforms import functional as F
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class ImageTextDataset(Dataset):
|
| 25 |
+
"""
|
| 26 |
+
Usage:
|
| 27 |
+
The dataset class for image-text pairs, used for image generation training
|
| 28 |
+
It supports multi-aspect ratio training
|
| 29 |
+
params:
|
| 30 |
+
anno_file: The annotation file list
|
| 31 |
+
add_normalize: whether to normalize the input image pixel to [-1, 1], default: True
|
| 32 |
+
ratios: The aspect ratios during training, format: width / height
|
| 33 |
+
sizes: The resoultion of training images, format: (width, height)
|
| 34 |
+
"""
|
| 35 |
+
def __init__(
|
| 36 |
+
self, anno_file, add_normalize=True,
|
| 37 |
+
ratios=[1/1, 3/5, 5/3],
|
| 38 |
+
sizes=[(1024, 1024), (768, 1280), (1280, 768)],
|
| 39 |
+
crop_mode='random', p_random_ratio=0.0,
|
| 40 |
+
):
|
| 41 |
+
# Ratios and Sizes : (w h)
|
| 42 |
+
super().__init__()
|
| 43 |
+
|
| 44 |
+
self.image_annos = []
|
| 45 |
+
if not isinstance(anno_file, list):
|
| 46 |
+
anno_file = [anno_file]
|
| 47 |
+
|
| 48 |
+
for anno_file_ in anno_file:
|
| 49 |
+
print(f"Load image annotation files from {anno_file_}")
|
| 50 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 51 |
+
for item in reader:
|
| 52 |
+
self.image_annos.append(item)
|
| 53 |
+
|
| 54 |
+
print(f"Totally Remained {len(self.image_annos)} images")
|
| 55 |
+
|
| 56 |
+
transform_list = [
|
| 57 |
+
transforms.ToTensor(),
|
| 58 |
+
]
|
| 59 |
+
|
| 60 |
+
if add_normalize:
|
| 61 |
+
transform_list.append(transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
|
| 62 |
+
|
| 63 |
+
self.transform = transforms.Compose(transform_list)
|
| 64 |
+
|
| 65 |
+
print(f"Transform List is {transform_list}")
|
| 66 |
+
|
| 67 |
+
assert crop_mode in ['center', 'random']
|
| 68 |
+
self.crop_mode = crop_mode
|
| 69 |
+
self.ratios = ratios
|
| 70 |
+
self.sizes = sizes
|
| 71 |
+
self.p_random_ratio = p_random_ratio
|
| 72 |
+
|
| 73 |
+
def get_closest_size(self, x):
|
| 74 |
+
if self.p_random_ratio > 0 and np.random.rand() < self.p_random_ratio:
|
| 75 |
+
best_size_idx = np.random.randint(len(self.ratios))
|
| 76 |
+
else:
|
| 77 |
+
w, h = x.width, x.height
|
| 78 |
+
best_size_idx = np.argmin([abs(w/h-r) for r in self.ratios])
|
| 79 |
+
return self.sizes[best_size_idx]
|
| 80 |
+
|
| 81 |
+
def get_resize_size(self, orig_size, tgt_size):
|
| 82 |
+
if (tgt_size[1]/tgt_size[0] - 1) * (orig_size[1]/orig_size[0] - 1) >= 0:
|
| 83 |
+
alt_min = int(math.ceil(max(tgt_size)*min(orig_size)/max(orig_size)))
|
| 84 |
+
resize_size = max(alt_min, min(tgt_size))
|
| 85 |
+
else:
|
| 86 |
+
alt_max = int(math.ceil(min(tgt_size)*max(orig_size)/min(orig_size)))
|
| 87 |
+
resize_size = max(alt_max, max(tgt_size))
|
| 88 |
+
return resize_size
|
| 89 |
+
|
| 90 |
+
def __len__(self):
|
| 91 |
+
return len(self.image_annos)
|
| 92 |
+
|
| 93 |
+
def __getitem__(self, index):
|
| 94 |
+
image_anno = self.image_annos[index]
|
| 95 |
+
|
| 96 |
+
try:
|
| 97 |
+
img = Image.open(image_anno['image']).convert("RGB")
|
| 98 |
+
text = image_anno['text']
|
| 99 |
+
|
| 100 |
+
assert isinstance(text, str), "Text should be str"
|
| 101 |
+
|
| 102 |
+
size = self.get_closest_size(img)
|
| 103 |
+
resize_size = self.get_resize_size((img.width, img.height), size)
|
| 104 |
+
|
| 105 |
+
img = transforms.functional.resize(img, resize_size, interpolation=transforms.InterpolationMode.BICUBIC, antialias=True)
|
| 106 |
+
|
| 107 |
+
if self.crop_mode == 'center':
|
| 108 |
+
img = transforms.functional.center_crop(img, (size[1], size[0]))
|
| 109 |
+
elif self.crop_mode == 'random':
|
| 110 |
+
img = transforms.RandomCrop((size[1], size[0]))(img)
|
| 111 |
+
else:
|
| 112 |
+
img = transforms.functional.center_crop(img, (size[1], size[0]))
|
| 113 |
+
|
| 114 |
+
image_tensor = self.transform(img)
|
| 115 |
+
|
| 116 |
+
return {
|
| 117 |
+
"video": image_tensor, # using keyname `video`, to be compatible with video
|
| 118 |
+
"text" : text,
|
| 119 |
+
"identifier": 'image',
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
except Exception as e:
|
| 123 |
+
print(f'Load Image Error with {e}')
|
| 124 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class LengthGroupedVideoTextDataset(Dataset):
|
| 128 |
+
"""
|
| 129 |
+
Usage:
|
| 130 |
+
The dataset class for video-text pairs, used for video generation training
|
| 131 |
+
It groups the video with the same frames together
|
| 132 |
+
Now only supporting fixed resolution during training
|
| 133 |
+
params:
|
| 134 |
+
anno_file: The annotation file list
|
| 135 |
+
max_frames: The maximum temporal lengths (This is the vae latent temporal length) 16 => (16 - 1) * 8 + 1 = 121 frames
|
| 136 |
+
load_vae_latent: Loading the pre-extracted vae latents during training, we recommend to extract the latents in advance
|
| 137 |
+
to reduce the time cost per batch
|
| 138 |
+
load_text_fea: Loading the pre-extracted text features during training, we recommend to extract the prompt textual features
|
| 139 |
+
in advance, since the T5 encoder will cost many GPU memories
|
| 140 |
+
"""
|
| 141 |
+
|
| 142 |
+
def __init__(self, anno_file, max_frames=16, resolution='384p', load_vae_latent=True, load_text_fea=True):
|
| 143 |
+
super().__init__()
|
| 144 |
+
|
| 145 |
+
self.video_annos = []
|
| 146 |
+
self.max_frames = max_frames
|
| 147 |
+
self.load_vae_latent = load_vae_latent
|
| 148 |
+
self.load_text_fea = load_text_fea
|
| 149 |
+
self.resolution = resolution
|
| 150 |
+
|
| 151 |
+
assert load_vae_latent, "Now only support loading vae latents, we will support to directly load video frames in the future"
|
| 152 |
+
|
| 153 |
+
if not isinstance(anno_file, list):
|
| 154 |
+
anno_file = [anno_file]
|
| 155 |
+
|
| 156 |
+
for anno_file_ in anno_file:
|
| 157 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 158 |
+
for item in tqdm(reader):
|
| 159 |
+
self.video_annos.append(item)
|
| 160 |
+
|
| 161 |
+
print(f"Totally Remained {len(self.video_annos)} videos")
|
| 162 |
+
|
| 163 |
+
def __len__(self):
|
| 164 |
+
return len(self.video_annos)
|
| 165 |
+
|
| 166 |
+
def __getitem__(self, index):
|
| 167 |
+
try:
|
| 168 |
+
video_anno = self.video_annos[index]
|
| 169 |
+
text = video_anno['text']
|
| 170 |
+
latent_path = video_anno['latent']
|
| 171 |
+
latent = torch.load(latent_path, map_location='cpu') # loading the pre-extracted video latents
|
| 172 |
+
|
| 173 |
+
# TODO: remove the hard code latent shape checking
|
| 174 |
+
if self.resolution == '384p':
|
| 175 |
+
assert latent.shape[-1] == 640 // 8
|
| 176 |
+
assert latent.shape[-2] == 384 // 8
|
| 177 |
+
else:
|
| 178 |
+
assert self.resolution == '768p'
|
| 179 |
+
assert latent.shape[-1] == 1280 // 8
|
| 180 |
+
assert latent.shape[-2] == 768 // 8
|
| 181 |
+
|
| 182 |
+
cur_temp = latent.shape[2]
|
| 183 |
+
cur_temp = min(cur_temp, self.max_frames)
|
| 184 |
+
|
| 185 |
+
video_latent = latent[:,:,:cur_temp].float()
|
| 186 |
+
assert video_latent.shape[1] == 16
|
| 187 |
+
|
| 188 |
+
if self.load_text_fea:
|
| 189 |
+
text_fea_path = video_anno['text_fea']
|
| 190 |
+
text_fea = torch.load(text_fea_path, map_location='cpu')
|
| 191 |
+
return {
|
| 192 |
+
'video': video_latent,
|
| 193 |
+
'prompt_embed': text_fea['prompt_embed'],
|
| 194 |
+
'prompt_attention_mask': text_fea['prompt_attention_mask'],
|
| 195 |
+
'pooled_prompt_embed': text_fea['pooled_prompt_embed'],
|
| 196 |
+
"identifier": 'video',
|
| 197 |
+
}
|
| 198 |
+
|
| 199 |
+
else:
|
| 200 |
+
return {
|
| 201 |
+
'video': video_latent,
|
| 202 |
+
'text': text,
|
| 203 |
+
"identifier": 'video',
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
except Exception as e:
|
| 207 |
+
print(f'Load Video Error with {e}')
|
| 208 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class VideoFrameProcessor:
|
| 212 |
+
# load a video and transform
|
| 213 |
+
def __init__(self, resolution=256, num_frames=24, add_normalize=True, sample_fps=24):
|
| 214 |
+
|
| 215 |
+
image_size = resolution
|
| 216 |
+
|
| 217 |
+
transform_list = [
|
| 218 |
+
transforms.Resize(image_size, interpolation=InterpolationMode.BICUBIC, antialias=True),
|
| 219 |
+
transforms.CenterCrop(image_size),
|
| 220 |
+
]
|
| 221 |
+
|
| 222 |
+
if add_normalize:
|
| 223 |
+
transform_list.append(transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
|
| 224 |
+
|
| 225 |
+
print(f"Transform List is {transform_list}")
|
| 226 |
+
self.num_frames = num_frames
|
| 227 |
+
self.transform = transforms.Compose(transform_list)
|
| 228 |
+
self.sample_fps = sample_fps
|
| 229 |
+
|
| 230 |
+
def __call__(self, video_path):
|
| 231 |
+
try:
|
| 232 |
+
video_capture = cv2.VideoCapture(video_path)
|
| 233 |
+
fps = video_capture.get(cv2.CAP_PROP_FPS)
|
| 234 |
+
frames = []
|
| 235 |
+
|
| 236 |
+
while True:
|
| 237 |
+
flag, frame = video_capture.read()
|
| 238 |
+
if not flag:
|
| 239 |
+
break
|
| 240 |
+
|
| 241 |
+
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
|
| 242 |
+
frame = torch.from_numpy(frame)
|
| 243 |
+
frame = frame.permute(2, 0, 1)
|
| 244 |
+
frames.append(frame)
|
| 245 |
+
|
| 246 |
+
video_capture.release()
|
| 247 |
+
sample_fps = self.sample_fps
|
| 248 |
+
interval = max(int(fps / sample_fps), 1)
|
| 249 |
+
frames = frames[::interval]
|
| 250 |
+
|
| 251 |
+
if len(frames) < self.num_frames:
|
| 252 |
+
num_frame_to_pack = self.num_frames - len(frames)
|
| 253 |
+
recurrent_num = num_frame_to_pack // len(frames)
|
| 254 |
+
frames = frames + recurrent_num * frames + frames[:(num_frame_to_pack % len(frames))]
|
| 255 |
+
assert len(frames) >= self.num_frames, f'{len(frames)}'
|
| 256 |
+
|
| 257 |
+
start_indexs = list(range(0, max(0, len(frames) - self.num_frames + 1)))
|
| 258 |
+
start_index = random.choice(start_indexs)
|
| 259 |
+
|
| 260 |
+
filtered_frames = frames[start_index : start_index+self.num_frames]
|
| 261 |
+
assert len(filtered_frames) == self.num_frames, f"The sampled frames should equals to {self.num_frames}"
|
| 262 |
+
|
| 263 |
+
filtered_frames = torch.stack(filtered_frames).float() / 255
|
| 264 |
+
filtered_frames = self.transform(filtered_frames)
|
| 265 |
+
filtered_frames = filtered_frames.permute(1, 0, 2, 3)
|
| 266 |
+
|
| 267 |
+
return filtered_frames, None
|
| 268 |
+
|
| 269 |
+
except Exception as e:
|
| 270 |
+
print(f"Load video: {video_path} Error, Exception {e}")
|
| 271 |
+
return None, None
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
class VideoDataset(Dataset):
|
| 275 |
+
def __init__(self, anno_file, resolution=256, max_frames=6, add_normalize=True):
|
| 276 |
+
super().__init__()
|
| 277 |
+
|
| 278 |
+
self.video_annos = []
|
| 279 |
+
self.max_frames = max_frames
|
| 280 |
+
|
| 281 |
+
if not isinstance(anno_file, list):
|
| 282 |
+
anno_file = [anno_file]
|
| 283 |
+
|
| 284 |
+
print(f"The training video clip frame number is {max_frames} ")
|
| 285 |
+
|
| 286 |
+
for anno_file_ in anno_file:
|
| 287 |
+
print(f"Load annotation file from {anno_file_}")
|
| 288 |
+
|
| 289 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 290 |
+
for item in tqdm(reader):
|
| 291 |
+
self.video_annos.append(item)
|
| 292 |
+
|
| 293 |
+
print(f"Totally Remained {len(self.video_annos)} videos")
|
| 294 |
+
|
| 295 |
+
self.video_processor = VideoFrameProcessor(resolution, max_frames, add_normalize)
|
| 296 |
+
|
| 297 |
+
def __len__(self):
|
| 298 |
+
return len(self.video_annos)
|
| 299 |
+
|
| 300 |
+
def __getitem__(self, index):
|
| 301 |
+
video_anno = self.video_annos[index]
|
| 302 |
+
video_path = video_anno['video']
|
| 303 |
+
|
| 304 |
+
try:
|
| 305 |
+
video_tensors, video_frames = self.video_processor(video_path)
|
| 306 |
+
|
| 307 |
+
assert video_tensors.shape[1] == self.max_frames
|
| 308 |
+
|
| 309 |
+
return {
|
| 310 |
+
"video": video_tensors,
|
| 311 |
+
"identifier": 'video',
|
| 312 |
+
}
|
| 313 |
+
|
| 314 |
+
except Exception as e:
|
| 315 |
+
print('Loading Video Error with {e}')
|
| 316 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class ImageDataset(Dataset):
|
| 320 |
+
def __init__(self, anno_file, resolution=256, max_frames=8, add_normalize=True):
|
| 321 |
+
super().__init__()
|
| 322 |
+
|
| 323 |
+
self.image_annos = []
|
| 324 |
+
self.max_frames = max_frames
|
| 325 |
+
image_paths = []
|
| 326 |
+
|
| 327 |
+
if not isinstance(anno_file, list):
|
| 328 |
+
anno_file = [anno_file]
|
| 329 |
+
|
| 330 |
+
for anno_file_ in anno_file:
|
| 331 |
+
print(f"Load annotation file from {anno_file_}")
|
| 332 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 333 |
+
for item in tqdm(reader):
|
| 334 |
+
image_paths.append(item['image'])
|
| 335 |
+
|
| 336 |
+
print(f"Totally Remained {len(image_paths)} images")
|
| 337 |
+
|
| 338 |
+
# pack multiple frames
|
| 339 |
+
for idx in range(0, len(image_paths), self.max_frames):
|
| 340 |
+
image_path_shard = image_paths[idx : idx + self.max_frames]
|
| 341 |
+
if len(image_path_shard) < self.max_frames:
|
| 342 |
+
image_path_shard = image_path_shard + image_paths[:self.max_frames - len(image_path_shard)]
|
| 343 |
+
assert len(image_path_shard) == self.max_frames
|
| 344 |
+
self.image_annos.append(image_path_shard)
|
| 345 |
+
|
| 346 |
+
image_size = resolution
|
| 347 |
+
transform_list = [
|
| 348 |
+
transforms.Resize(image_size, interpolation=InterpolationMode.BICUBIC, antialias=True),
|
| 349 |
+
transforms.CenterCrop(image_size),
|
| 350 |
+
transforms.ToTensor(),
|
| 351 |
+
]
|
| 352 |
+
if add_normalize:
|
| 353 |
+
transform_list.append(transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
|
| 354 |
+
|
| 355 |
+
print(f"Transform List is {transform_list}")
|
| 356 |
+
self.transform = transforms.Compose(transform_list)
|
| 357 |
+
|
| 358 |
+
def __len__(self):
|
| 359 |
+
return len(self.image_annos)
|
| 360 |
+
|
| 361 |
+
def __getitem__(self, index):
|
| 362 |
+
image_paths = self.image_annos[index]
|
| 363 |
+
|
| 364 |
+
try:
|
| 365 |
+
packed_pil_frames = [Image.open(image_path).convert("RGB") for image_path in image_paths]
|
| 366 |
+
filtered_frames = [self.transform(frame) for frame in packed_pil_frames]
|
| 367 |
+
filtered_frames = torch.stack(filtered_frames) # [t, c, h, w]
|
| 368 |
+
filtered_frames = filtered_frames.permute(1, 0, 2, 3) # [c, t, h, w]
|
| 369 |
+
|
| 370 |
+
return {
|
| 371 |
+
"video": filtered_frames,
|
| 372 |
+
"identifier": 'image',
|
| 373 |
+
}
|
| 374 |
+
|
| 375 |
+
except Exception as e:
|
| 376 |
+
print(f'Load Images Error with {e}')
|
| 377 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
diffusion_schedulers/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .scheduling_cosine_ddpm import DDPMCosineScheduler
|
| 2 |
+
from .scheduling_flow_matching import PyramidFlowMatchEulerDiscreteScheduler
|
diffusion_schedulers/scheduling_cosine_ddpm.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import List, Optional, Tuple, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.utils import BaseOutput
|
| 9 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 10 |
+
from diffusers.schedulers.scheduling_utils import SchedulerMixin
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass
|
| 14 |
+
class DDPMSchedulerOutput(BaseOutput):
|
| 15 |
+
"""
|
| 16 |
+
Output class for the scheduler's step function output.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
prev_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 20 |
+
Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
|
| 21 |
+
denoising loop.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
prev_sample: torch.Tensor
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class DDPMCosineScheduler(SchedulerMixin, ConfigMixin):
|
| 28 |
+
|
| 29 |
+
@register_to_config
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
scaler: float = 1.0,
|
| 33 |
+
s: float = 0.008,
|
| 34 |
+
):
|
| 35 |
+
self.scaler = scaler
|
| 36 |
+
self.s = torch.tensor([s])
|
| 37 |
+
self._init_alpha_cumprod = torch.cos(self.s / (1 + self.s) * torch.pi * 0.5) ** 2
|
| 38 |
+
|
| 39 |
+
# standard deviation of the initial noise distribution
|
| 40 |
+
self.init_noise_sigma = 1.0
|
| 41 |
+
|
| 42 |
+
def _alpha_cumprod(self, t, device):
|
| 43 |
+
if self.scaler > 1:
|
| 44 |
+
t = 1 - (1 - t) ** self.scaler
|
| 45 |
+
elif self.scaler < 1:
|
| 46 |
+
t = t**self.scaler
|
| 47 |
+
alpha_cumprod = torch.cos(
|
| 48 |
+
(t + self.s.to(device)) / (1 + self.s.to(device)) * torch.pi * 0.5
|
| 49 |
+
) ** 2 / self._init_alpha_cumprod.to(device)
|
| 50 |
+
return alpha_cumprod.clamp(0.0001, 0.9999)
|
| 51 |
+
|
| 52 |
+
def scale_model_input(self, sample: torch.Tensor, timestep: Optional[int] = None) -> torch.Tensor:
|
| 53 |
+
"""
|
| 54 |
+
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
|
| 55 |
+
current timestep.
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
sample (`torch.Tensor`): input sample
|
| 59 |
+
timestep (`int`, optional): current timestep
|
| 60 |
+
|
| 61 |
+
Returns:
|
| 62 |
+
`torch.Tensor`: scaled input sample
|
| 63 |
+
"""
|
| 64 |
+
return sample
|
| 65 |
+
|
| 66 |
+
def set_timesteps(
|
| 67 |
+
self,
|
| 68 |
+
num_inference_steps: int = None,
|
| 69 |
+
timesteps: Optional[List[int]] = None,
|
| 70 |
+
device: Union[str, torch.device] = None,
|
| 71 |
+
):
|
| 72 |
+
"""
|
| 73 |
+
Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
|
| 74 |
+
|
| 75 |
+
Args:
|
| 76 |
+
num_inference_steps (`Dict[float, int]`):
|
| 77 |
+
the number of diffusion steps used when generating samples with a pre-trained model. If passed, then
|
| 78 |
+
`timesteps` must be `None`.
|
| 79 |
+
device (`str` or `torch.device`, optional):
|
| 80 |
+
the device to which the timesteps are moved to. {2 / 3: 20, 0.0: 10}
|
| 81 |
+
"""
|
| 82 |
+
if timesteps is None:
|
| 83 |
+
timesteps = torch.linspace(1.0, 0.0, num_inference_steps + 1, device=device)
|
| 84 |
+
if not isinstance(timesteps, torch.Tensor):
|
| 85 |
+
timesteps = torch.Tensor(timesteps).to(device)
|
| 86 |
+
self.timesteps = timesteps
|
| 87 |
+
|
| 88 |
+
def step(
|
| 89 |
+
self,
|
| 90 |
+
model_output: torch.Tensor,
|
| 91 |
+
timestep: int,
|
| 92 |
+
sample: torch.Tensor,
|
| 93 |
+
generator=None,
|
| 94 |
+
return_dict: bool = True,
|
| 95 |
+
) -> Union[DDPMSchedulerOutput, Tuple]:
|
| 96 |
+
dtype = model_output.dtype
|
| 97 |
+
device = model_output.device
|
| 98 |
+
t = timestep
|
| 99 |
+
|
| 100 |
+
prev_t = self.previous_timestep(t)
|
| 101 |
+
|
| 102 |
+
alpha_cumprod = self._alpha_cumprod(t, device).view(t.size(0), *[1 for _ in sample.shape[1:]])
|
| 103 |
+
alpha_cumprod_prev = self._alpha_cumprod(prev_t, device).view(prev_t.size(0), *[1 for _ in sample.shape[1:]])
|
| 104 |
+
alpha = alpha_cumprod / alpha_cumprod_prev
|
| 105 |
+
|
| 106 |
+
mu = (1.0 / alpha).sqrt() * (sample - (1 - alpha) * model_output / (1 - alpha_cumprod).sqrt())
|
| 107 |
+
|
| 108 |
+
std_noise = randn_tensor(mu.shape, generator=generator, device=model_output.device, dtype=model_output.dtype)
|
| 109 |
+
std = ((1 - alpha) * (1.0 - alpha_cumprod_prev) / (1.0 - alpha_cumprod)).sqrt() * std_noise
|
| 110 |
+
pred = mu + std * (prev_t != 0).float().view(prev_t.size(0), *[1 for _ in sample.shape[1:]])
|
| 111 |
+
|
| 112 |
+
if not return_dict:
|
| 113 |
+
return (pred.to(dtype),)
|
| 114 |
+
|
| 115 |
+
return DDPMSchedulerOutput(prev_sample=pred.to(dtype))
|
| 116 |
+
|
| 117 |
+
def add_noise(
|
| 118 |
+
self,
|
| 119 |
+
original_samples: torch.Tensor,
|
| 120 |
+
noise: torch.Tensor,
|
| 121 |
+
timesteps: torch.Tensor,
|
| 122 |
+
) -> torch.Tensor:
|
| 123 |
+
device = original_samples.device
|
| 124 |
+
dtype = original_samples.dtype
|
| 125 |
+
alpha_cumprod = self._alpha_cumprod(timesteps, device=device).view(
|
| 126 |
+
timesteps.size(0), *[1 for _ in original_samples.shape[1:]]
|
| 127 |
+
)
|
| 128 |
+
noisy_samples = alpha_cumprod.sqrt() * original_samples + (1 - alpha_cumprod).sqrt() * noise
|
| 129 |
+
return noisy_samples.to(dtype=dtype)
|
| 130 |
+
|
| 131 |
+
def __len__(self):
|
| 132 |
+
return self.config.num_train_timesteps
|
| 133 |
+
|
| 134 |
+
def previous_timestep(self, timestep):
|
| 135 |
+
index = (self.timesteps - timestep[0]).abs().argmin().item()
|
| 136 |
+
prev_t = self.timesteps[index + 1][None].expand(timestep.shape[0])
|
| 137 |
+
return prev_t
|
diffusion_schedulers/scheduling_flow_matching.py
ADDED
|
@@ -0,0 +1,297 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Optional, Tuple, Union, List
|
| 3 |
+
import math
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.utils import BaseOutput, logging
|
| 9 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 10 |
+
from diffusers.schedulers.scheduling_utils import SchedulerMixin
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass
|
| 14 |
+
class FlowMatchEulerDiscreteSchedulerOutput(BaseOutput):
|
| 15 |
+
"""
|
| 16 |
+
Output class for the scheduler's `step` function output.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 20 |
+
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
|
| 21 |
+
denoising loop.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
prev_sample: torch.FloatTensor
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class PyramidFlowMatchEulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
|
| 28 |
+
"""
|
| 29 |
+
Euler scheduler.
|
| 30 |
+
|
| 31 |
+
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
|
| 32 |
+
methods the library implements for all schedulers such as loading and saving.
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
num_train_timesteps (`int`, defaults to 1000):
|
| 36 |
+
The number of diffusion steps to train the model.
|
| 37 |
+
timestep_spacing (`str`, defaults to `"linspace"`):
|
| 38 |
+
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
|
| 39 |
+
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
|
| 40 |
+
shift (`float`, defaults to 1.0):
|
| 41 |
+
The shift value for the timestep schedule.
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
_compatibles = []
|
| 45 |
+
order = 1
|
| 46 |
+
|
| 47 |
+
@register_to_config
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
num_train_timesteps: int = 1000,
|
| 51 |
+
shift: float = 1.0, # Following Stable diffusion 3,
|
| 52 |
+
stages: int = 3,
|
| 53 |
+
stage_range: List = [0, 1/3, 2/3, 1],
|
| 54 |
+
gamma: float = 1/3,
|
| 55 |
+
):
|
| 56 |
+
|
| 57 |
+
self.timestep_ratios = {} # The timestep ratio for each stage
|
| 58 |
+
self.timesteps_per_stage = {} # The detailed timesteps per stage
|
| 59 |
+
self.sigmas_per_stage = {}
|
| 60 |
+
self.start_sigmas = {}
|
| 61 |
+
self.end_sigmas = {}
|
| 62 |
+
self.ori_start_sigmas = {}
|
| 63 |
+
|
| 64 |
+
# self.init_sigmas()
|
| 65 |
+
self.init_sigmas_for_each_stage()
|
| 66 |
+
self.sigma_min = self.sigmas[-1].item()
|
| 67 |
+
self.sigma_max = self.sigmas[0].item()
|
| 68 |
+
self.gamma = gamma
|
| 69 |
+
|
| 70 |
+
def init_sigmas(self):
|
| 71 |
+
"""
|
| 72 |
+
initialize the global timesteps and sigmas
|
| 73 |
+
"""
|
| 74 |
+
num_train_timesteps = self.config.num_train_timesteps
|
| 75 |
+
shift = self.config.shift
|
| 76 |
+
|
| 77 |
+
timesteps = np.linspace(1, num_train_timesteps, num_train_timesteps, dtype=np.float32)[::-1].copy()
|
| 78 |
+
timesteps = torch.from_numpy(timesteps).to(dtype=torch.float32)
|
| 79 |
+
|
| 80 |
+
sigmas = timesteps / num_train_timesteps
|
| 81 |
+
sigmas = shift * sigmas / (1 + (shift - 1) * sigmas)
|
| 82 |
+
|
| 83 |
+
self.timesteps = sigmas * num_train_timesteps
|
| 84 |
+
|
| 85 |
+
self._step_index = None
|
| 86 |
+
self._begin_index = None
|
| 87 |
+
|
| 88 |
+
self.sigmas = sigmas.to("cpu") # to avoid too much CPU/GPU communication
|
| 89 |
+
|
| 90 |
+
def init_sigmas_for_each_stage(self):
|
| 91 |
+
"""
|
| 92 |
+
Init the timesteps for each stage
|
| 93 |
+
"""
|
| 94 |
+
self.init_sigmas()
|
| 95 |
+
|
| 96 |
+
stage_distance = []
|
| 97 |
+
stages = self.config.stages
|
| 98 |
+
training_steps = self.config.num_train_timesteps
|
| 99 |
+
stage_range = self.config.stage_range
|
| 100 |
+
|
| 101 |
+
# Init the start and end point of each stage
|
| 102 |
+
for i_s in range(stages):
|
| 103 |
+
# To decide the start and ends point
|
| 104 |
+
start_indice = int(stage_range[i_s] * training_steps)
|
| 105 |
+
start_indice = max(start_indice, 0)
|
| 106 |
+
end_indice = int(stage_range[i_s+1] * training_steps)
|
| 107 |
+
end_indice = min(end_indice, training_steps)
|
| 108 |
+
start_sigma = self.sigmas[start_indice].item()
|
| 109 |
+
end_sigma = self.sigmas[end_indice].item() if end_indice < training_steps else 0.0
|
| 110 |
+
self.ori_start_sigmas[i_s] = start_sigma
|
| 111 |
+
|
| 112 |
+
if i_s != 0:
|
| 113 |
+
ori_sigma = 1 - start_sigma
|
| 114 |
+
gamma = self.config.gamma
|
| 115 |
+
corrected_sigma = (1 / (math.sqrt(1 + (1 / gamma)) * (1 - ori_sigma) + ori_sigma)) * ori_sigma
|
| 116 |
+
# corrected_sigma = 1 / (2 - ori_sigma) * ori_sigma
|
| 117 |
+
start_sigma = 1 - corrected_sigma
|
| 118 |
+
|
| 119 |
+
stage_distance.append(start_sigma - end_sigma)
|
| 120 |
+
self.start_sigmas[i_s] = start_sigma
|
| 121 |
+
self.end_sigmas[i_s] = end_sigma
|
| 122 |
+
|
| 123 |
+
# Determine the ratio of each stage according to flow length
|
| 124 |
+
tot_distance = sum(stage_distance)
|
| 125 |
+
for i_s in range(stages):
|
| 126 |
+
if i_s == 0:
|
| 127 |
+
start_ratio = 0.0
|
| 128 |
+
else:
|
| 129 |
+
start_ratio = sum(stage_distance[:i_s]) / tot_distance
|
| 130 |
+
if i_s == stages - 1:
|
| 131 |
+
end_ratio = 1.0
|
| 132 |
+
else:
|
| 133 |
+
end_ratio = sum(stage_distance[:i_s+1]) / tot_distance
|
| 134 |
+
|
| 135 |
+
self.timestep_ratios[i_s] = (start_ratio, end_ratio)
|
| 136 |
+
|
| 137 |
+
# Determine the timesteps and sigmas for each stage
|
| 138 |
+
for i_s in range(stages):
|
| 139 |
+
timestep_ratio = self.timestep_ratios[i_s]
|
| 140 |
+
timestep_max = self.timesteps[int(timestep_ratio[0] * training_steps)]
|
| 141 |
+
timestep_min = self.timesteps[min(int(timestep_ratio[1] * training_steps), training_steps - 1)]
|
| 142 |
+
timesteps = np.linspace(
|
| 143 |
+
timestep_max, timestep_min, training_steps + 1,
|
| 144 |
+
)
|
| 145 |
+
self.timesteps_per_stage[i_s] = timesteps[:-1] if isinstance(timesteps, torch.Tensor) else torch.from_numpy(timesteps[:-1])
|
| 146 |
+
stage_sigmas = np.linspace(
|
| 147 |
+
1, 0, training_steps + 1,
|
| 148 |
+
)
|
| 149 |
+
self.sigmas_per_stage[i_s] = torch.from_numpy(stage_sigmas[:-1])
|
| 150 |
+
|
| 151 |
+
@property
|
| 152 |
+
def step_index(self):
|
| 153 |
+
"""
|
| 154 |
+
The index counter for current timestep. It will increase 1 after each scheduler step.
|
| 155 |
+
"""
|
| 156 |
+
return self._step_index
|
| 157 |
+
|
| 158 |
+
@property
|
| 159 |
+
def begin_index(self):
|
| 160 |
+
"""
|
| 161 |
+
The index for the first timestep. It should be set from pipeline with `set_begin_index` method.
|
| 162 |
+
"""
|
| 163 |
+
return self._begin_index
|
| 164 |
+
|
| 165 |
+
# Copied from diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler.set_begin_index
|
| 166 |
+
def set_begin_index(self, begin_index: int = 0):
|
| 167 |
+
"""
|
| 168 |
+
Sets the begin index for the scheduler. This function should be run from pipeline before the inference.
|
| 169 |
+
|
| 170 |
+
Args:
|
| 171 |
+
begin_index (`int`):
|
| 172 |
+
The begin index for the scheduler.
|
| 173 |
+
"""
|
| 174 |
+
self._begin_index = begin_index
|
| 175 |
+
|
| 176 |
+
def _sigma_to_t(self, sigma):
|
| 177 |
+
return sigma * self.config.num_train_timesteps
|
| 178 |
+
|
| 179 |
+
def set_timesteps(self, num_inference_steps: int, stage_index: int, device: Union[str, torch.device] = None):
|
| 180 |
+
"""
|
| 181 |
+
Setting the timesteps and sigmas for each stage
|
| 182 |
+
"""
|
| 183 |
+
self.num_inference_steps = num_inference_steps
|
| 184 |
+
training_steps = self.config.num_train_timesteps
|
| 185 |
+
self.init_sigmas()
|
| 186 |
+
|
| 187 |
+
stage_timesteps = self.timesteps_per_stage[stage_index]
|
| 188 |
+
timestep_max = stage_timesteps[0].item()
|
| 189 |
+
timestep_min = stage_timesteps[-1].item()
|
| 190 |
+
|
| 191 |
+
timesteps = np.linspace(
|
| 192 |
+
timestep_max, timestep_min, num_inference_steps,
|
| 193 |
+
)
|
| 194 |
+
self.timesteps = torch.from_numpy(timesteps).to(device=device)
|
| 195 |
+
|
| 196 |
+
stage_sigmas = self.sigmas_per_stage[stage_index]
|
| 197 |
+
sigma_max = stage_sigmas[0].item()
|
| 198 |
+
sigma_min = stage_sigmas[-1].item()
|
| 199 |
+
|
| 200 |
+
ratios = np.linspace(
|
| 201 |
+
sigma_max, sigma_min, num_inference_steps
|
| 202 |
+
)
|
| 203 |
+
sigmas = torch.from_numpy(ratios).to(device=device)
|
| 204 |
+
self.sigmas = torch.cat([sigmas, torch.zeros(1, device=sigmas.device)])
|
| 205 |
+
|
| 206 |
+
self._step_index = None
|
| 207 |
+
|
| 208 |
+
def index_for_timestep(self, timestep, schedule_timesteps=None):
|
| 209 |
+
if schedule_timesteps is None:
|
| 210 |
+
schedule_timesteps = self.timesteps
|
| 211 |
+
|
| 212 |
+
indices = (schedule_timesteps == timestep).nonzero()
|
| 213 |
+
|
| 214 |
+
# The sigma index that is taken for the **very** first `step`
|
| 215 |
+
# is always the second index (or the last index if there is only 1)
|
| 216 |
+
# This way we can ensure we don't accidentally skip a sigma in
|
| 217 |
+
# case we start in the middle of the denoising schedule (e.g. for image-to-image)
|
| 218 |
+
pos = 1 if len(indices) > 1 else 0
|
| 219 |
+
|
| 220 |
+
return indices[pos].item()
|
| 221 |
+
|
| 222 |
+
def _init_step_index(self, timestep):
|
| 223 |
+
if self.begin_index is None:
|
| 224 |
+
if isinstance(timestep, torch.Tensor):
|
| 225 |
+
timestep = timestep.to(self.timesteps.device)
|
| 226 |
+
self._step_index = self.index_for_timestep(timestep)
|
| 227 |
+
else:
|
| 228 |
+
self._step_index = self._begin_index
|
| 229 |
+
|
| 230 |
+
def step(
|
| 231 |
+
self,
|
| 232 |
+
model_output: torch.FloatTensor,
|
| 233 |
+
timestep: Union[float, torch.FloatTensor],
|
| 234 |
+
sample: torch.FloatTensor,
|
| 235 |
+
generator: Optional[torch.Generator] = None,
|
| 236 |
+
return_dict: bool = True,
|
| 237 |
+
) -> Union[FlowMatchEulerDiscreteSchedulerOutput, Tuple]:
|
| 238 |
+
"""
|
| 239 |
+
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
|
| 240 |
+
process from the learned model outputs (most often the predicted noise).
|
| 241 |
+
|
| 242 |
+
Args:
|
| 243 |
+
model_output (`torch.FloatTensor`):
|
| 244 |
+
The direct output from learned diffusion model.
|
| 245 |
+
timestep (`float`):
|
| 246 |
+
The current discrete timestep in the diffusion chain.
|
| 247 |
+
sample (`torch.FloatTensor`):
|
| 248 |
+
A current instance of a sample created by the diffusion process.
|
| 249 |
+
generator (`torch.Generator`, *optional*):
|
| 250 |
+
A random number generator.
|
| 251 |
+
return_dict (`bool`):
|
| 252 |
+
Whether or not to return a [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or
|
| 253 |
+
tuple.
|
| 254 |
+
|
| 255 |
+
Returns:
|
| 256 |
+
[`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or `tuple`:
|
| 257 |
+
If return_dict is `True`, [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] is
|
| 258 |
+
returned, otherwise a tuple is returned where the first element is the sample tensor.
|
| 259 |
+
"""
|
| 260 |
+
|
| 261 |
+
if (
|
| 262 |
+
isinstance(timestep, int)
|
| 263 |
+
or isinstance(timestep, torch.IntTensor)
|
| 264 |
+
or isinstance(timestep, torch.LongTensor)
|
| 265 |
+
):
|
| 266 |
+
raise ValueError(
|
| 267 |
+
(
|
| 268 |
+
"Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
|
| 269 |
+
" `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
|
| 270 |
+
" one of the `scheduler.timesteps` as a timestep."
|
| 271 |
+
),
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
if self.step_index is None:
|
| 275 |
+
self._step_index = 0
|
| 276 |
+
|
| 277 |
+
# Upcast to avoid precision issues when computing prev_sample
|
| 278 |
+
sample = sample.to(torch.float32)
|
| 279 |
+
|
| 280 |
+
sigma = self.sigmas[self.step_index]
|
| 281 |
+
sigma_next = self.sigmas[self.step_index + 1]
|
| 282 |
+
|
| 283 |
+
prev_sample = sample + (sigma_next - sigma) * model_output
|
| 284 |
+
|
| 285 |
+
# Cast sample back to model compatible dtype
|
| 286 |
+
prev_sample = prev_sample.to(model_output.dtype)
|
| 287 |
+
|
| 288 |
+
# upon completion increase step index by one
|
| 289 |
+
self._step_index += 1
|
| 290 |
+
|
| 291 |
+
if not return_dict:
|
| 292 |
+
return (prev_sample,)
|
| 293 |
+
|
| 294 |
+
return FlowMatchEulerDiscreteSchedulerOutput(prev_sample=prev_sample)
|
| 295 |
+
|
| 296 |
+
def __len__(self):
|
| 297 |
+
return self.config.num_train_timesteps
|
docs/DiT.md
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pyramid Flow's DiT Finetuning Guide
|
| 2 |
+
|
| 3 |
+
This is the finetuning guide for the DiT in Pyramid Flow. We provide instructions for both autoregressive and non-autoregressive versions. The former is more research oriented and the latter is more stable (but less efficient without temporal pyramid). Please refer to [another document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/VAE) for VAE finetuning.
|
| 4 |
+
|
| 5 |
+
## Hardware Requirements
|
| 6 |
+
|
| 7 |
+
+ DiT finetuning: At least 8 A100 GPUs.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Prepare the Dataset
|
| 11 |
+
|
| 12 |
+
The training dataset should be arranged into a json file, with `video`, `text` fields. Since the video vae latent extraction is very slow, we strongly recommend you to pre-extract the video vae latents to save the training time. We provide a video vae latent extraction script in folder `tools`. You can run it with the following command:
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
sh scripts/extract_vae_latent.sh
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
(optional) Since the T5 text encoder will cost a lot of GPU memory, pre-extract the text features will save the training memory. We also provide a text feature extraction script in folder `tools`. You can run it with the following command:
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
sh scripts/extract_text_feature.sh
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
The final training annotation json file should look like the following format:
|
| 25 |
+
|
| 26 |
+
```
|
| 27 |
+
{"video": video_path, "text": text prompt, "latent": extracted video vae latent, "text_fea": extracted text feature}
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
We provide the example json annotation files for [video](https://github.com/jy0205/Pyramid-Flow/blob/main/annotation/video_text.jsonl) and [image](https://github.com/jy0205/Pyramid-Flow/blob/main/annotation/image_text.jsonl)) training in the `annotation` folder. You can refer them to prepare your training dataset.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Run Training
|
| 34 |
+
We provide two types of training scripts: (1) autoregressive video generation training with temporal pyramid. (2) Full-sequence diffusion training with pyramid-flow for both text-to-image and text-to-video training. This corresponds to the following two script files. Running these training scripts using at least 8 GPUs:
|
| 35 |
+
|
| 36 |
+
+ `scripts/train_pyramid_flow.sh`: The autoregressive video generation training with temporal pyramid.
|
| 37 |
+
|
| 38 |
+
```bash
|
| 39 |
+
sh scripts/train_pyramid_flow.sh
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
+ `scripts/train_pyramid_flow_without_ar.sh`: Using pyramid-flow for full-sequence diffusion training.
|
| 43 |
+
|
| 44 |
+
```bash
|
| 45 |
+
sh scripts/train_pyramid_flow_without_ar.sh
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## Tips
|
| 50 |
+
|
| 51 |
+
+ For the 768p version, make sure to add the args: `--gradient_checkpointing`
|
| 52 |
+
+ Param `NUM_FRAMES` should be set to a multiple of 8
|
| 53 |
+
+ For the param `video_sync_group`, it indicates the number of process that accepts the same input video, used for temporal pyramid AR training. We recommend to set this value to 4, 8 or 16. (16 is better if you have more GPUs)
|
| 54 |
+
+ Make sure to set `NUM_FRAMES % VIDEO_SYNC_GROUP == 0`, `GPUS % VIDEO_SYNC_GROUP == 0`, and `BATCH_SIZE % 4 == 0`
|
docs/VAE.md
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pyramid Flow's VAE Training Guide
|
| 2 |
+
|
| 3 |
+
This is the training guide for a [MAGVIT-v2](https://arxiv.org/abs/2310.05737) like continuous 3D VAE, which should be quite flexible. Feel free to build your own video generative model on this part of VAE training code. Please refer to [another document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/DiT) for DiT finetuning.
|
| 4 |
+
|
| 5 |
+
## Hardware Requirements
|
| 6 |
+
|
| 7 |
+
+ VAE training: At least 8 A100 GPUs.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Prepare the Dataset
|
| 11 |
+
|
| 12 |
+
The training of our causal video vae uses both image and video data. Both of them should be arranged into a json file, with `video` or `image` field. The final training annotation json file should look like the following format:
|
| 13 |
+
|
| 14 |
+
```
|
| 15 |
+
# For Video
|
| 16 |
+
{"video": video_path}
|
| 17 |
+
|
| 18 |
+
# For Image
|
| 19 |
+
{"image": image_path}
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
## Run Training
|
| 23 |
+
|
| 24 |
+
The causal video vae undergoes a two-stage training.
|
| 25 |
+
+ Stage-1: image and video mixed training
|
| 26 |
+
+ Stage-2: pure video training, using context parallel to load video with more video frames
|
| 27 |
+
|
| 28 |
+
The VAE training script is `scripts/train_causal_video_vae.sh`, run it as follows:
|
| 29 |
+
|
| 30 |
+
```bash
|
| 31 |
+
sh scripts/train_causal_video_vae.sh
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
We also provide a VAE demo `causal_video_vae_demo.ipynb` for image and video reconstruction.
|
| 35 |
+
> The original vgg lpips download URL is not available, I have shared the one we used in this [URL](https://drive.google.com/file/d/1YeFlX5BKKw-HGkjNd1r7DSwas1iJJwqC/view). You can download it and replace the LPIPS_CKPT with the correct path.
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## Tips
|
| 39 |
+
|
| 40 |
+
+ For stage-1, we use a mixed image and video training. Add the param `--use_image_video_mixed_training` to support the mixed training. We set the image ratio to 0.1 by default.
|
| 41 |
+
+ Set the `resolution` to 256 is enough for VAE training.
|
| 42 |
+
+ For stage-1, the `max_frames` is set to 17. It means we use 17 sampled video frames for training.
|
| 43 |
+
+ For stage-2, we open the param `use_context_parallel` to distribute long video frames to multiple GPUs. Make sure to set `GPUS % CONTEXT_SIZE == 0` and `NUM_FRAMES=17 * CONTEXT_SIZE + 1`
|
image_generation_demo.ipynb
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import os\n",
|
| 10 |
+
"import json\n",
|
| 11 |
+
"import torch\n",
|
| 12 |
+
"import numpy as np\n",
|
| 13 |
+
"import PIL\n",
|
| 14 |
+
"from PIL import Image\n",
|
| 15 |
+
"from IPython.display import HTML\n",
|
| 16 |
+
"from pyramid_dit import PyramidDiTForVideoGeneration\n",
|
| 17 |
+
"from IPython.display import Image as ipython_image\n",
|
| 18 |
+
"from diffusers.utils import load_image, export_to_video, export_to_gif"
|
| 19 |
+
]
|
| 20 |
+
},
|
| 21 |
+
{
|
| 22 |
+
"cell_type": "code",
|
| 23 |
+
"execution_count": null,
|
| 24 |
+
"metadata": {},
|
| 25 |
+
"outputs": [],
|
| 26 |
+
"source": [
|
| 27 |
+
"variant='diffusion_transformer_image' # For low resolution\n",
|
| 28 |
+
"model_name = \"pyramid_flux\"\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"model_path = \"/home/jinyang06/models/pyramid-flow-miniflux\" # The downloaded checkpoint dir\n",
|
| 31 |
+
"model_dtype = 'bf16'\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"device_id = 0\n",
|
| 34 |
+
"torch.cuda.set_device(device_id)\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"model = PyramidDiTForVideoGeneration(\n",
|
| 37 |
+
" model_path,\n",
|
| 38 |
+
" model_dtype,\n",
|
| 39 |
+
" model_name=model_name,\n",
|
| 40 |
+
" model_variant=variant,\n",
|
| 41 |
+
")\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"model.vae.to(\"cuda\")\n",
|
| 44 |
+
"model.dit.to(\"cuda\")\n",
|
| 45 |
+
"model.text_encoder.to(\"cuda\")\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"model.vae.enable_tiling()\n",
|
| 48 |
+
"\n",
|
| 49 |
+
"if model_dtype == \"bf16\":\n",
|
| 50 |
+
" torch_dtype = torch.bfloat16 \n",
|
| 51 |
+
"elif model_dtype == \"fp16\":\n",
|
| 52 |
+
" torch_dtype = torch.float16\n",
|
| 53 |
+
"else:\n",
|
| 54 |
+
" torch_dtype = torch.float32"
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"attachments": {},
|
| 59 |
+
"cell_type": "markdown",
|
| 60 |
+
"metadata": {},
|
| 61 |
+
"source": [
|
| 62 |
+
"### Text-to-Image"
|
| 63 |
+
]
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"cell_type": "code",
|
| 67 |
+
"execution_count": null,
|
| 68 |
+
"metadata": {},
|
| 69 |
+
"outputs": [],
|
| 70 |
+
"source": [
|
| 71 |
+
"prompt = \"shoulder and full head portrait of a beautiful 19 year old girl, brunette, smiling, stunning, highly detailed, glamour lighting, HDR, photorealistic, hyperrealism, octane render, unreal engine\"\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"# now support 3 aspect ratios\n",
|
| 74 |
+
"resolution_dict = {\n",
|
| 75 |
+
" '1:1' : (1024, 1024),\n",
|
| 76 |
+
" '5:3' : (1280, 768),\n",
|
| 77 |
+
" '3:5' : (768, 1280),\n",
|
| 78 |
+
"}\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"ratio = '1:1' # 1:1, 5:3, 3:5\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"width, height = resolution_dict[ratio]\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"\n",
|
| 85 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):\n",
|
| 86 |
+
" images = model.generate(\n",
|
| 87 |
+
" prompt=prompt,\n",
|
| 88 |
+
" num_inference_steps=[20, 20, 20],\n",
|
| 89 |
+
" height=height,\n",
|
| 90 |
+
" width=width,\n",
|
| 91 |
+
" temp=1,\n",
|
| 92 |
+
" guidance_scale=9.0, \n",
|
| 93 |
+
" output_type=\"pil\",\n",
|
| 94 |
+
" save_memory=False, \n",
|
| 95 |
+
" )\n",
|
| 96 |
+
"\n",
|
| 97 |
+
"display(images[0])"
|
| 98 |
+
]
|
| 99 |
+
}
|
| 100 |
+
],
|
| 101 |
+
"metadata": {
|
| 102 |
+
"kernelspec": {
|
| 103 |
+
"display_name": "Python 3",
|
| 104 |
+
"language": "python",
|
| 105 |
+
"name": "python3"
|
| 106 |
+
},
|
| 107 |
+
"language_info": {
|
| 108 |
+
"codemirror_mode": {
|
| 109 |
+
"name": "ipython",
|
| 110 |
+
"version": 3
|
| 111 |
+
},
|
| 112 |
+
"file_extension": ".py",
|
| 113 |
+
"mimetype": "text/x-python",
|
| 114 |
+
"name": "python",
|
| 115 |
+
"nbconvert_exporter": "python",
|
| 116 |
+
"pygments_lexer": "ipython3",
|
| 117 |
+
"version": "3.8.10"
|
| 118 |
+
},
|
| 119 |
+
"orig_nbformat": 4
|
| 120 |
+
},
|
| 121 |
+
"nbformat": 4,
|
| 122 |
+
"nbformat_minor": 2
|
| 123 |
+
}
|
inference_multigpu.py
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import sys
|
| 4 |
+
import argparse
|
| 5 |
+
import random
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import numpy as np
|
| 9 |
+
from diffusers.utils import export_to_video
|
| 10 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 11 |
+
from trainer_misc import init_distributed_mode, init_sequence_parallel_group
|
| 12 |
+
import PIL
|
| 13 |
+
from PIL import Image
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_args():
|
| 17 |
+
parser = argparse.ArgumentParser('Pytorch Multi-process Script', add_help=False)
|
| 18 |
+
parser.add_argument('--model_name', default='pyramid_flux', type=str, help="The model name", choices=["pyramid_flux", "pyramid_mmdit"])
|
| 19 |
+
parser.add_argument('--model_dtype', default='bf16', type=str, help="The Model Dtype: bf16")
|
| 20 |
+
parser.add_argument('--model_path', default='/home/jinyang06/models/pyramid-flow', type=str, help='Set it to the downloaded checkpoint dir')
|
| 21 |
+
parser.add_argument('--variant', default='diffusion_transformer_768p', type=str,)
|
| 22 |
+
parser.add_argument('--task', default='t2v', type=str, choices=['i2v', 't2v'])
|
| 23 |
+
parser.add_argument('--temp', default=16, type=int, help='The generated latent num, num_frames = temp * 8 + 1')
|
| 24 |
+
parser.add_argument('--sp_group_size', default=2, type=int, help="The number of gpus used for inference, should be 2 or 4")
|
| 25 |
+
parser.add_argument('--sp_proc_num', default=-1, type=int, help="The number of process used for video training, default=-1 means using all process.")
|
| 26 |
+
|
| 27 |
+
return parser.parse_args()
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def main():
|
| 31 |
+
args = get_args()
|
| 32 |
+
|
| 33 |
+
# setup DDP
|
| 34 |
+
init_distributed_mode(args)
|
| 35 |
+
|
| 36 |
+
assert args.world_size == args.sp_group_size, "The sequence parallel size should be DDP world size"
|
| 37 |
+
|
| 38 |
+
# Enable sequence parallel
|
| 39 |
+
init_sequence_parallel_group(args)
|
| 40 |
+
|
| 41 |
+
device = torch.device('cuda')
|
| 42 |
+
rank = args.rank
|
| 43 |
+
model_dtype = args.model_dtype
|
| 44 |
+
|
| 45 |
+
model = PyramidDiTForVideoGeneration(
|
| 46 |
+
args.model_path,
|
| 47 |
+
model_dtype,
|
| 48 |
+
model_name=args.model_name,
|
| 49 |
+
model_variant=args.variant,
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
model.vae.to(device)
|
| 53 |
+
model.dit.to(device)
|
| 54 |
+
model.text_encoder.to(device)
|
| 55 |
+
model.vae.enable_tiling()
|
| 56 |
+
|
| 57 |
+
if model_dtype == "bf16":
|
| 58 |
+
torch_dtype = torch.bfloat16
|
| 59 |
+
elif model_dtype == "fp16":
|
| 60 |
+
torch_dtype = torch.float16
|
| 61 |
+
else:
|
| 62 |
+
torch_dtype = torch.float32
|
| 63 |
+
|
| 64 |
+
# The video generation config
|
| 65 |
+
if args.variant == 'diffusion_transformer_768p':
|
| 66 |
+
width = 1280
|
| 67 |
+
height = 768
|
| 68 |
+
else:
|
| 69 |
+
assert args.variant == 'diffusion_transformer_384p'
|
| 70 |
+
width = 640
|
| 71 |
+
height = 384
|
| 72 |
+
|
| 73 |
+
if args.task == 't2v':
|
| 74 |
+
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
|
| 75 |
+
|
| 76 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):
|
| 77 |
+
frames = model.generate(
|
| 78 |
+
prompt=prompt,
|
| 79 |
+
num_inference_steps=[20, 20, 20],
|
| 80 |
+
video_num_inference_steps=[10, 10, 10],
|
| 81 |
+
height=height,
|
| 82 |
+
width=width,
|
| 83 |
+
temp=args.temp,
|
| 84 |
+
guidance_scale=7.0, # The guidance for the first frame, set it to 7 for 384p variant
|
| 85 |
+
video_guidance_scale=5.0, # The guidance for the other video latent
|
| 86 |
+
output_type="pil",
|
| 87 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 88 |
+
cpu_offloading=False, # If OOM, set it to True to reduce memory usage
|
| 89 |
+
inference_multigpu=True,
|
| 90 |
+
)
|
| 91 |
+
if rank == 0:
|
| 92 |
+
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)
|
| 93 |
+
|
| 94 |
+
else:
|
| 95 |
+
assert args.task == 'i2v'
|
| 96 |
+
|
| 97 |
+
image_path = 'assets/the_great_wall.jpg'
|
| 98 |
+
image = Image.open(image_path).convert("RGB")
|
| 99 |
+
image = image.resize((width, height))
|
| 100 |
+
|
| 101 |
+
prompt = "FPV flying over the Great Wall"
|
| 102 |
+
|
| 103 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):
|
| 104 |
+
frames = model.generate_i2v(
|
| 105 |
+
prompt=prompt,
|
| 106 |
+
input_image=image,
|
| 107 |
+
num_inference_steps=[10, 10, 10],
|
| 108 |
+
temp=args.temp,
|
| 109 |
+
video_guidance_scale=4.0,
|
| 110 |
+
output_type="pil",
|
| 111 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 112 |
+
cpu_offloading=False, # If OOM, set it to True to reduce memory usage
|
| 113 |
+
inference_multigpu=True,
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
if rank == 0:
|
| 117 |
+
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)
|
| 118 |
+
|
| 119 |
+
torch.distributed.barrier()
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
if __name__ == "__main__":
|
| 123 |
+
main()
|
pyramid_dit/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .pyramid_dit_for_video_gen_pipeline import PyramidDiTForVideoGeneration
|
| 2 |
+
from .flux_modules import FluxSingleTransformerBlock, FluxTransformerBlock, FluxTextEncoderWithMask
|
| 3 |
+
from .mmdit_modules import JointTransformerBlock, SD3TextEncoderWithMask
|
pyramid_dit/flux_modules/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .modeling_pyramid_flux import PyramidFluxTransformer
|
| 2 |
+
from .modeling_text_encoder import FluxTextEncoderWithMask
|
| 3 |
+
from .modeling_flux_block import FluxSingleTransformerBlock, FluxTransformerBlock
|