---
base_model: facebook/m2m100_418M
datasets:
- HamzaNaser/Dialects-To-MSA-800K
language:
- ar
library_name: transformers
license: apache-2.0
metrics:
- bleu
pipeline_tag: text2text-generation
tags:
- Dialects Conversion
- Text Correction
- Punctiating
- Diacretization
- En-Ar Transtaltion
model-index:
- name: Dialects-to-MSA-Transformer
results: []
---
# Dialects-to-MSA-Transformer overview
This Model is optimized to convert written text in various non Standard Classical Arabic into Classic Arabic, the model was Fine-Tuned on 0.8M pairs of sentence generated by OpenAI API gpt-4o-mini Text Generation Model, beside being able to convert Dialects into Classical Arabic, the model can also be used in other NLP tasks such as Text Correction, Diacretization, Sentence Punctuation and Machine Translation.
# Model
Dialects-to-MSA-Transformer was Fine-Tuned on m2m100_418M, which consist of ~400M parameters, we could consider using larger Model to increase the performace of the resulting Model but more computations capability would be required.
# Dataset
The Model was trained on `Dialects-To-MSA-800K` Dataset, which consists of random crowled Arabic Tweets sentences with their corrosponding Classical conversion.
Arabic Tweets are selected randomly from the Arabic-Tweets Datasets https://huggingface.co./datasets/pain/Arabic-Tweets , and Classical Arabic sentences where generated using gpt-4o-mini model by prompting it to convert the given sentences into Corrected Classical Arabic text.
## Dataset Limitations
The Dataset used to train the Model consist of some random Arabic Tweets that was not checked as described by the Dataset Authers hence its possible to find gramatically incorrect or semantically incomplted sentences, also the text where normalized in the Arabic-Tweets Datasets which might make it harder for the model to know the meaning of some sentences for some cases, even though the original Tweets crowled from the internet qulity was not perfect for our use case, the resulting trained model is relativley good, achiving Bleu score of 46.9 on the testing data, 46.9 score might consider a very high score, but our Model case is differenct than normal MT and we believe is considered easier to translate between dialects in same language than translating between completely different languages.
- Below image shows one of the issues the input Dataset might have, some of the missing punctuations might flip the meaning of the sentenece completely, for example of we got the word "No" in the begining of a sentece in this case the "No" would negate the upcoming speach. However if the word "No" where to be followed by a comma, it then will negate the prevuous speach and prove the upcoming sentence instead, both cases are completly contradicted just by adding a single comma.
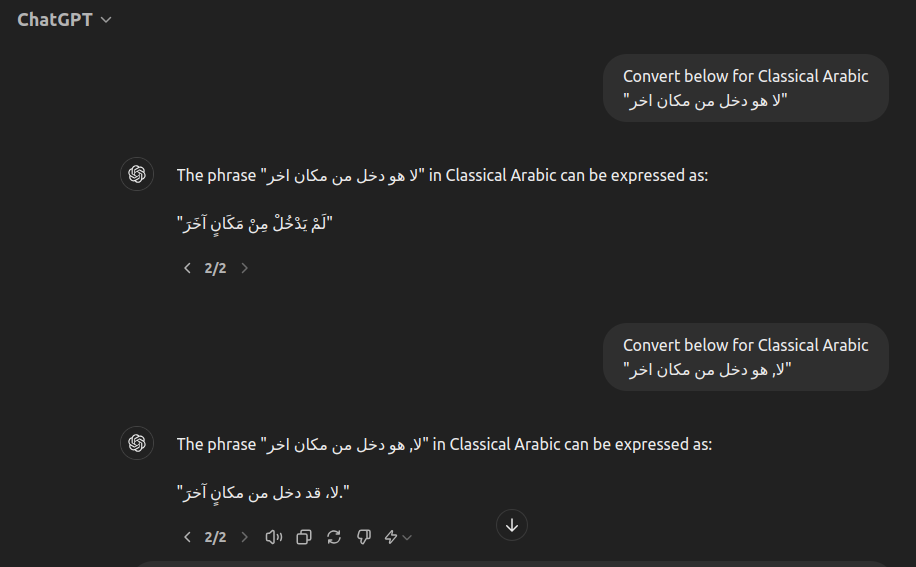 - Another example for Data limitation is the sentece might be inaccurate or incomplete, making it harder for the GPT model to convert it to MSA or Classical Arabic, many examples for inconsistent input text can be found in the Dataset the Model trained on.
## GPT Generated Data
Classical Arabic sentences used to train the model where generated using GPT Model, we used gpt-4o-mini as its cheaper and faster and produces a fine quality results, target text might not be 100% accurate as the quality of the dataset is not perfect, and mini vesion of GPT where used to reduce cost and time, expected model perfomance improvement if we would use the bigger GPT-4 version or even use GPT-5 or later versions when they released in the future.
## Dialects Used to Trained the model
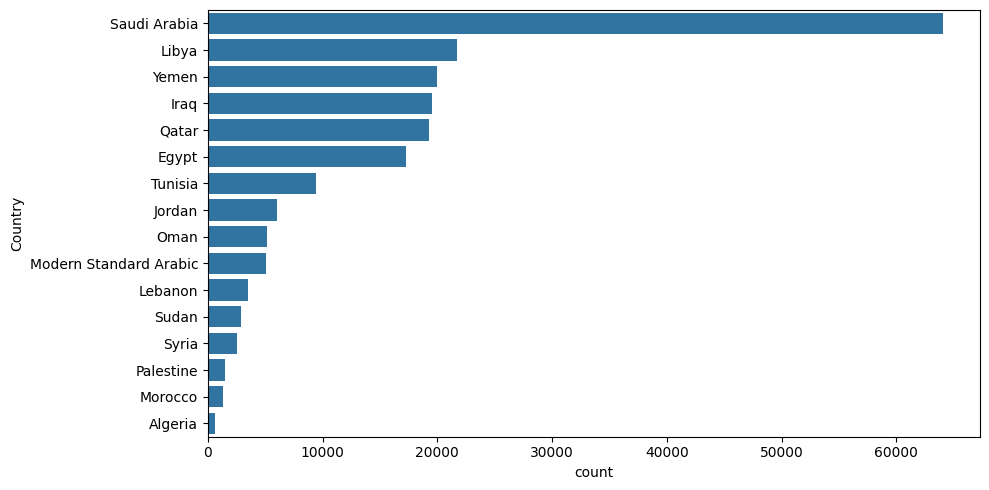
As an estimate on 200K random samples, most training samples are from Gulf region, the dialects regions is an estimate of the input Arabic-Tweets Dataset classified by DialectIdentifyer provided by camel tools https://camel-tools.readthedocs.io/en/latest/api/dialectid.html, we also can say that the Model can work better to convert below Regions' Dialects into MSA, below figure shows the approximate dilects by regions the Model were trained on.
- Another example for Data limitation is the sentece might be inaccurate or incomplete, making it harder for the GPT model to convert it to MSA or Classical Arabic, many examples for inconsistent input text can be found in the Dataset the Model trained on.
## GPT Generated Data
Classical Arabic sentences used to train the model where generated using GPT Model, we used gpt-4o-mini as its cheaper and faster and produces a fine quality results, target text might not be 100% accurate as the quality of the dataset is not perfect, and mini vesion of GPT where used to reduce cost and time, expected model perfomance improvement if we would use the bigger GPT-4 version or even use GPT-5 or later versions when they released in the future.
## Dialects Used to Trained the model
As an estimate on 200K random samples, most training samples are from Gulf region, the dialects regions is an estimate of the input Arabic-Tweets Dataset classified by DialectIdentifyer provided by camel tools https://camel-tools.readthedocs.io/en/latest/api/dialectid.html, we also can say that the Model can work better to convert below Regions' Dialects into MSA, below figure shows the approximate dilects by regions the Model were trained on.
 # Other use cases for the model
- Text Correction: Some of the input text might have typos, GPT model beside converting the Dialects text into MSA, it also fixed these typos, making it possible to use the Model as Text Correction.
- Punctiating: Input text in normalized with no punctuations, also GPT model were to add needed puctuactions while conversions, making the Model capable of adding missing or incorrect punctiations.
- Diacretization: Similar for Punctuating, input text has no diacretizations, we noticed that GPT output text include some of the mostly required diacretization that might affect the meaning of the sentence, this Model behavior can be adjusted through Prompt Engineering, also half way through generating the data the GPT model was prompted to include diacretizations while converting the text into MSA, although not all of the produce texts even after adjusting the prompt contains these diacs, it might be possible to use the Model to add some of the most important diacretization to the input sentence.
- En-Ar Machine Translation: even the Model was not Fine-Tuned on any English text, the Model still able to perform good English to Arabic translation due to its Pretraining on English texts.
# Training
In this section will discuss trainig procedure we followed as well metrics used and final results.
## Steps
Developing the Model ran into several steps, first step is by training the Model on 800K portion of the data twice using LoRA and traditional Full Parameters training, to see how much the performace would be affected if we used any of the PEFT techniques when training the final Model with larger split of the data, we proceed with Full param method in training as the Model accuracy were affected by the reduction of the number of trainable parameters (from 32 to 23 Bleu score on 20K examples) with not much reduction in training time (from 7 to 6 Hrs), might consider experimenting the use of PEFT in future project.
## Bleu Score Metric
Dialects to MSA or Classical Arabic conversion is a sequence to sequence task closer for Machine Translation, as we are try to convert the same exact sentence but in differnt formation or rules, we ends up chosing Bleu score for evaluating our Model performance as it measures how similar the occurrence word in predict and correct MSA text, and it is a good and widly used metric for Seq2Seq MT.
## Testing
To ensure correct performance measuring for the Model we need to make sure that the input and generated sequences are ~100% accurate when evaluating our Model, we need to inspect portion of the data to use as a test split since we got some data quality issues for the input and generated text,
Inspecting large paris of texts might be tedious, thus we have taken a sample of 553 paris of sentences as a testing split and inspected them manually, ~25% of the data needed modifications or was being discarded, resulting test data size is 477 inspected sentences, even though the test split size is small, it still help to provice enough indication if the Model is improving when changing certain parameters or its over or under fitting on the training data.
## Results
| Data Set Size | GPU Device | Epochs | Training Time | Blue Score |
|:-------------:|:----------:|:----------:|:---------------:|:------------:|
| 0.8M | A100 | 3 | 7.7Hrs | 46.9 |
| 2.6M | A100 | 1 | ??? | ??? |
## Costs and Resources
There are two main computing resources when Dialects to MSA Transformer were built, one is the generation of MSA sequences using GPT model, the second resource is the GPU used to train and adjust the parameters of the pretrained Model.
- OpenAI API: Generating the data took around a week with small batches fed into the API due to limited max tokens sizes and due to arabic being tokenized in the char level in the GPT Model, total costs for the API is around 35$.
- GPU: T4, A100 provided by Google Colab total computing units are 200, which costs around 20$
# Possible Future Improvements
As discussed eariler we got some limitations related with the used data and the used model, and we expect to achive better model performance by utilzing better data or GPT model to generate the Classical Arabic text
- Data: The data used to train the Model is random Arabic Tweets and its possible to find incorrect sentences grammatical and syntactical, we may use customized and more accurate data in the future which expect to increase the performance of the Model, also using larger input of texts with variaty of dialects is also considered.
- GPT: We could use larger or any future released versions of GPT models instead of the smaller one "gpt-4o-mini" which expect to improve the qulity for the generated Classical Arabic sentences.
- Model: We also might consider using larger Model, which also expect to improve the performance
# Other use cases for the model
- Text Correction: Some of the input text might have typos, GPT model beside converting the Dialects text into MSA, it also fixed these typos, making it possible to use the Model as Text Correction.
- Punctiating: Input text in normalized with no punctuations, also GPT model were to add needed puctuactions while conversions, making the Model capable of adding missing or incorrect punctiations.
- Diacretization: Similar for Punctuating, input text has no diacretizations, we noticed that GPT output text include some of the mostly required diacretization that might affect the meaning of the sentence, this Model behavior can be adjusted through Prompt Engineering, also half way through generating the data the GPT model was prompted to include diacretizations while converting the text into MSA, although not all of the produce texts even after adjusting the prompt contains these diacs, it might be possible to use the Model to add some of the most important diacretization to the input sentence.
- En-Ar Machine Translation: even the Model was not Fine-Tuned on any English text, the Model still able to perform good English to Arabic translation due to its Pretraining on English texts.
# Training
In this section will discuss trainig procedure we followed as well metrics used and final results.
## Steps
Developing the Model ran into several steps, first step is by training the Model on 800K portion of the data twice using LoRA and traditional Full Parameters training, to see how much the performace would be affected if we used any of the PEFT techniques when training the final Model with larger split of the data, we proceed with Full param method in training as the Model accuracy were affected by the reduction of the number of trainable parameters (from 32 to 23 Bleu score on 20K examples) with not much reduction in training time (from 7 to 6 Hrs), might consider experimenting the use of PEFT in future project.
## Bleu Score Metric
Dialects to MSA or Classical Arabic conversion is a sequence to sequence task closer for Machine Translation, as we are try to convert the same exact sentence but in differnt formation or rules, we ends up chosing Bleu score for evaluating our Model performance as it measures how similar the occurrence word in predict and correct MSA text, and it is a good and widly used metric for Seq2Seq MT.
## Testing
To ensure correct performance measuring for the Model we need to make sure that the input and generated sequences are ~100% accurate when evaluating our Model, we need to inspect portion of the data to use as a test split since we got some data quality issues for the input and generated text,
Inspecting large paris of texts might be tedious, thus we have taken a sample of 553 paris of sentences as a testing split and inspected them manually, ~25% of the data needed modifications or was being discarded, resulting test data size is 477 inspected sentences, even though the test split size is small, it still help to provice enough indication if the Model is improving when changing certain parameters or its over or under fitting on the training data.
## Results
| Data Set Size | GPU Device | Epochs | Training Time | Blue Score |
|:-------------:|:----------:|:----------:|:---------------:|:------------:|
| 0.8M | A100 | 3 | 7.7Hrs | 46.9 |
| 2.6M | A100 | 1 | ??? | ??? |
## Costs and Resources
There are two main computing resources when Dialects to MSA Transformer were built, one is the generation of MSA sequences using GPT model, the second resource is the GPU used to train and adjust the parameters of the pretrained Model.
- OpenAI API: Generating the data took around a week with small batches fed into the API due to limited max tokens sizes and due to arabic being tokenized in the char level in the GPT Model, total costs for the API is around 35$.
- GPU: T4, A100 provided by Google Colab total computing units are 200, which costs around 20$
# Possible Future Improvements
As discussed eariler we got some limitations related with the used data and the used model, and we expect to achive better model performance by utilzing better data or GPT model to generate the Classical Arabic text
- Data: The data used to train the Model is random Arabic Tweets and its possible to find incorrect sentences grammatical and syntactical, we may use customized and more accurate data in the future which expect to increase the performance of the Model, also using larger input of texts with variaty of dialects is also considered.
- GPT: We could use larger or any future released versions of GPT models instead of the smaller one "gpt-4o-mini" which expect to improve the qulity for the generated Classical Arabic sentences.
- Model: We also might consider using larger Model, which also expect to improve the performance