
File size: 4,454 Bytes
7420f86 403f1bc 7420f86 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 |
---
base_model: Sao10K/Llama-3.1-8B-Stheno-v3.4
datasets:
- Setiaku/Stheno-v3.4-Instruct
- Setiaku/Stheno-3.4-Creative-2
language:
- en
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
---

---
Llama-3.1-8B-Stheno-v3.4
This model has went through a multi-stage finetuning process.
```
- 1st, over a multi-turn Conversational-Instruct
- 2nd, over a Creative Writing / Roleplay along with some Creative-based Instruct Datasets.
- - Dataset consists of a mixture of Human and Claude Data.
```
Prompting Format:
```
- Use the L3 Instruct Formatting - Euryale 2.1 Preset Works Well
- Temperature + min_p as per usual, I recommend 1.4 Temp + 0.2 min_p.
- Has a different vibe to previous versions. Tinker around.
```
Changes since previous Stheno Datasets:
```
- Included Multi-turn Conversation-based Instruct Datasets to boost multi-turn coherency. # This is a seperate set, not the ones made by Kalomaze and Nopm, that are used in Magnum. They're completely different data.
- Replaced Single-Turn Instruct with Better Prompts and Answers by Claude 3.5 Sonnet and Claude 3 Opus.
- Removed c2 Samples -> Underway of re-filtering and masking to use with custom prefills. TBD
- Included 55% more Roleplaying Examples based of [Gryphe's](https://huggingface.co./datasets/Gryphe/Sonnet3.5-Charcard-Roleplay) Charcard RP Sets. Further filtered and cleaned on.
- Included 40% More Creative Writing Examples.
- Included Datasets Targeting System Prompt Adherence.
- Included Datasets targeting Reasoning / Spatial Awareness.
- Filtered for the usual errors, slop and stuff at the end. Some may have slipped through, but I removed nearly all of it.
```
Personal Opinions:
```
- Llama3.1 was more disappointing, in the Instruct Tune? It felt overbaked, atleast. Likely due to the DPO being done after their SFT Stage.
- Tuning on L3.1 base did not give good results, unlike when I tested with Nemo base. unfortunate.
- Still though, I think I did an okay job. It does feel a bit more distinctive.
- It took a lot of tinkering, like a LOT to wrangle this.
```
Below are some graphs and all for you to observe.
---
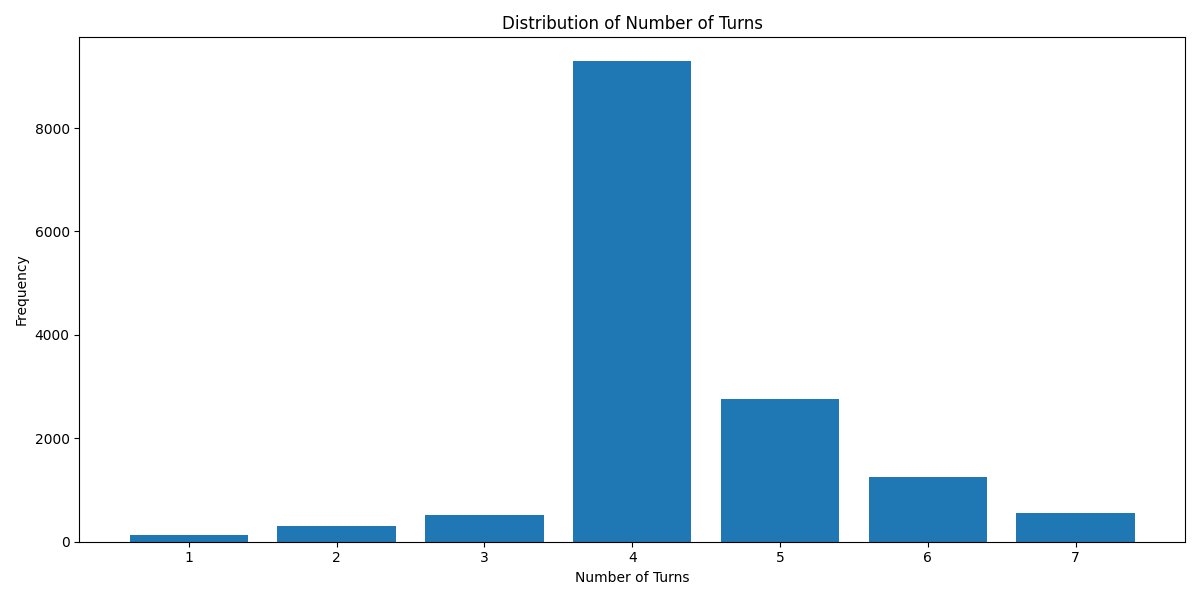
`Turn Distribution # 1 Turn is considered as 1 combined Human/GPT pair in a ShareGPT format. 4 Turns means 1 System Row + 8 Human/GPT rows in total.`
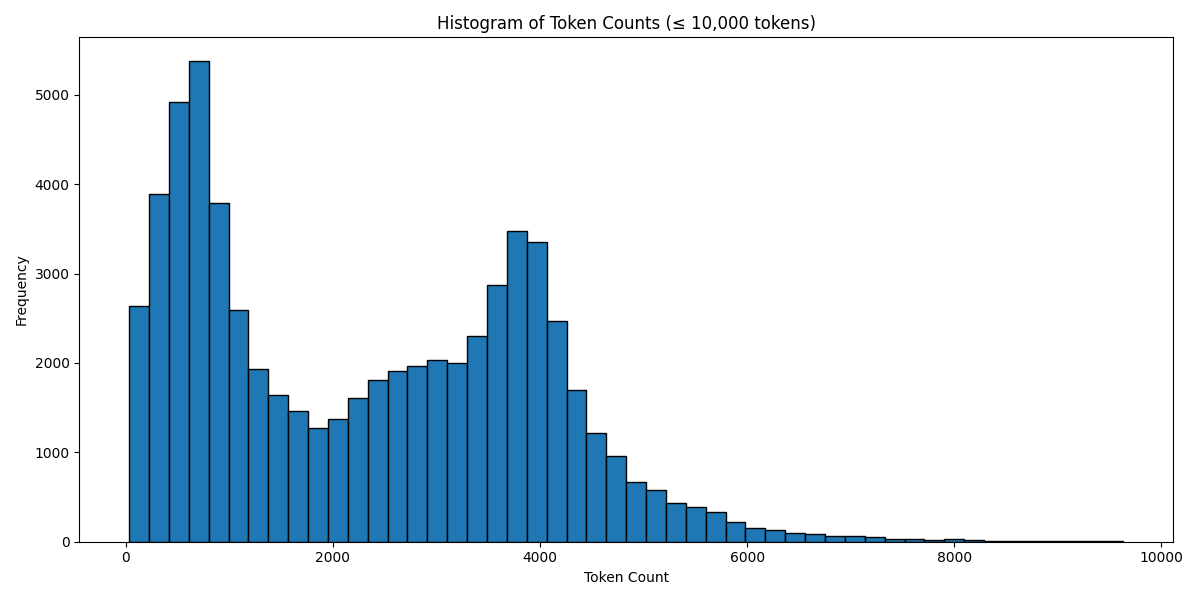
`Token Count Histogram # Based on the Llama 3 Tokenizer`
---
```
Source Image: https://www.pixiv.net/en/artworks/91689070
```
# DarqueDante/Llama-3.1-8B-Stheno-v3.4-Q5_K_M-GGUF
This model was converted to GGUF format from [`Sao10K/Llama-3.1-8B-Stheno-v3.4`](https://huggingface.co./Sao10K/Llama-3.1-8B-Stheno-v3.4) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co./spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co./Sao10K/Llama-3.1-8B-Stheno-v3.4) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-Q5_K_M-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-Q5_K_M-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-Q5_K_M-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-Q5_K_M-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q5_k_m.gguf -c 2048
```
|