---
license: mit
language:
- en
---
X-Dyna: Expressive Dynamic Human Image Animation
Di Chang1,2
·
Hongyi Xu2*
·
You Xie2*
·
Yipeng Gao1*
·
Zhengfei Kuang3*
·
Shengqu Cai3*
Chenxu Zhang2*
·
Guoxian Song2
·
Chao Wang2
·
Yichun Shi2
·
Zeyuan Chen2,5
·
Shijie Zhou4
Linjie Luo2
·
Gordon Wetzstein3
·
Mohammad Soleymani1
1Unviersity of Southern California 2ByteDance Inc. 3Stanford University
4University of California Los Angeles 5University of California San Diego
* denotes equally contribution
Project Page
·
Code
·
Paper
-----
This huggingface repo contains the pretrained models of X-Dyna.
## **Abstract**
We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key factors underlying the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations.
## **Architecture**
We leverage a pretrained diffusion UNet backbone for controlled human image animation, enabling expressive dynamic details and precise motion control. Specifically, we introduce a dynamics adapter that seamlessly integrates the reference image context as a trainable residual to the spatial attention, in parallel with the denoising process, while preserving the original spatial and temporal attention mechanisms within the UNet. In addition to body pose control via a ControlNet, we introduce a local face control module that implicitly learns facial expression control from a synthesized cross-identity face patch. We train our model on a diverse dataset of human motion videos and natural scene videos simultaneously.

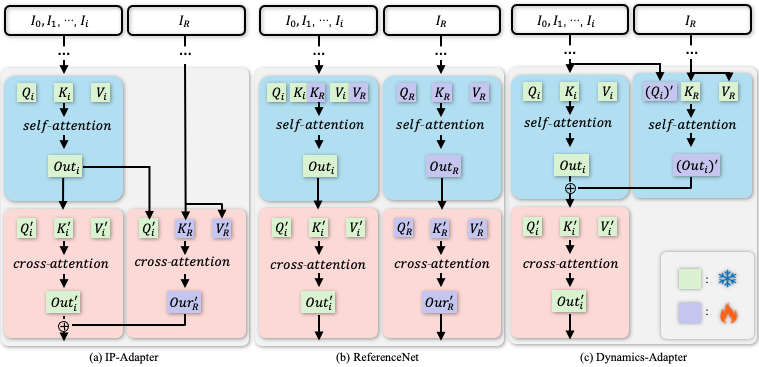
## **Dynamics Adapter**
### **Archtecture Designs for Human Video Animation**
a) IP-Adapter encodes the reference image as an image CLIP embedding and injects the information into the cross-attention layers in SD as the residual. b) ReferenceNet is a trainable parallel UNet and feeds the semantic information into SD via concatenation of self-attention features. c) Dynamics-Adapter encodes the reference image with a partially shared-weight UNet. The appearance control is realized by learning a residual in the self-attention with trainable query and output linear layers. All other components share the same frozen weight with SD.
## 📜 Requirements
* An NVIDIA GPU with CUDA support is required.
* We have tested on a single A100 GPU.
* **Minimum**: The minimum GPU memory required is 20GB for generating a single video (batch_size=1) of 16 frames.
* **Recommended**: We recommend using a GPU with 80GB of memory.
* Operating system: Linux
## 🧱 Download Pretrained Models
Due to restrictions we are not able to release the model pretrained with in-house data. Instead, we re-train our model on public datasets, e.g. [HumanVid](https://github.com/zhenzhiwang/HumanVid), and other human video data for research use, e.g.[Pexels](https://www.pexels.com/). We follow the implementation details in our paper and release pretrained weights and other necessary network modules in this huggingface repository. The Stable Diffusion 1.5 UNet can be found [here](https://huggingface.co./stable-diffusion-v1-5/stable-diffusion-v1-5) and place it under pretrained_weights/unet_initialization/SD. After downloading, please put all of them under the pretrained_weights folder. Your file structure should look like this:
```bash
X-Dyna
|----...
|----pretrained_weights
|----controlnet
|----controlnet-checkpoint-epoch-5.ckpt
|----controlnet_face
|----controlnet-face-checkpoint-epoch-2.ckpt
|----unet
|----unet-checkpoint-epoch-5.ckpt
|----initialization
|----controlnets_initialization
|----controlnet
|----control_v11p_sd15_openpose
|----controlnet_face
|----controlnet2
|----unet_initialization
|----IP-Adapter
|----IP-Adapter
|----SD
|----stable-diffusion-v1-5
|----...
```
## 🔗 BibTeX
If you find [X-Dyna](https://arxiv.org/abs/2501.10021) useful for your research and applications, please cite X-Dyna using this BibTeX:
```BibTeX
@misc{chang2025xdynaexpressivedynamichuman,
title={X-Dyna: Expressive Dynamic Human Image Animation},
author={Di Chang and Hongyi Xu and You Xie and Yipeng Gao and Zhengfei Kuang and Shengqu Cai and Chenxu Zhang and Guoxian Song and Chao Wang and Yichun Shi and Zeyuan Chen and Shijie Zhou and Linjie Luo and Gordon Wetzstein and Mohammad Soleymani},
year={2025},
eprint={2501.10021},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.10021},
}
```
## Acknowledgements
We appreciate the contributions from [AnimateDiff](https://github.com/guoyww/AnimateDiff), [MagicPose](https://github.com/Boese0601/MagicDance), [MimicMotion](https://github.com/tencent/MimicMotion), [Moore-AnimateAnyone](https://github.com/MooreThreads/Moore-AnimateAnyone), [MagicAnimate](https://github.com/magic-research/magic-animate), [IP-Adapter](https://github.com/tencent-ailab/IP-Adapter), [ControlNet](https://arxiv.org/abs/2302.05543), [I2V-Adapter](https://arxiv.org/abs/2312.16693) for their open-sourced research. We appreciate the support from Quankai Gao, Qiangeng Xu, Shen Sang, and Tiancheng Zhi for their suggestions and discussions.