---
license: apache-2.0
datasets:
- BUT-FIT/BUT-LCC
- BUT-FIT/adult_content_classifier_dataset
language:
- cs
---
# Introduction
CSTinyLlama-1.2B is a Czech language model continously pretrained on 168b training tokens from English [TinyLLama-2.5T](https://huggingface.co./TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) model. Model was pretrained on ~67b token [Large Czech Collection](https://huggingface.co./datasets/BUT-FIT/BUT-LCC) using Czech tokenizer, obtained using our vocabulary swap method.
Training was done on [Karolina](https://www.it4i.cz/en) cluster.
# BUT LM Model Roster
- [BUT-FIT/CSTinyLlama-1.2B](https://huggingface.co./BUT-FIT/CSTinyLlama-1.2B)
- [BUT-FIT/Czech-GPT-2-XL-133k](https://huggingface.co./BUT-FIT/Czech-GPT-2-XL-133k)
- [BUT-FIT/csmpt7b](https://huggingface.co./BUT-FIT/csmpt7b)
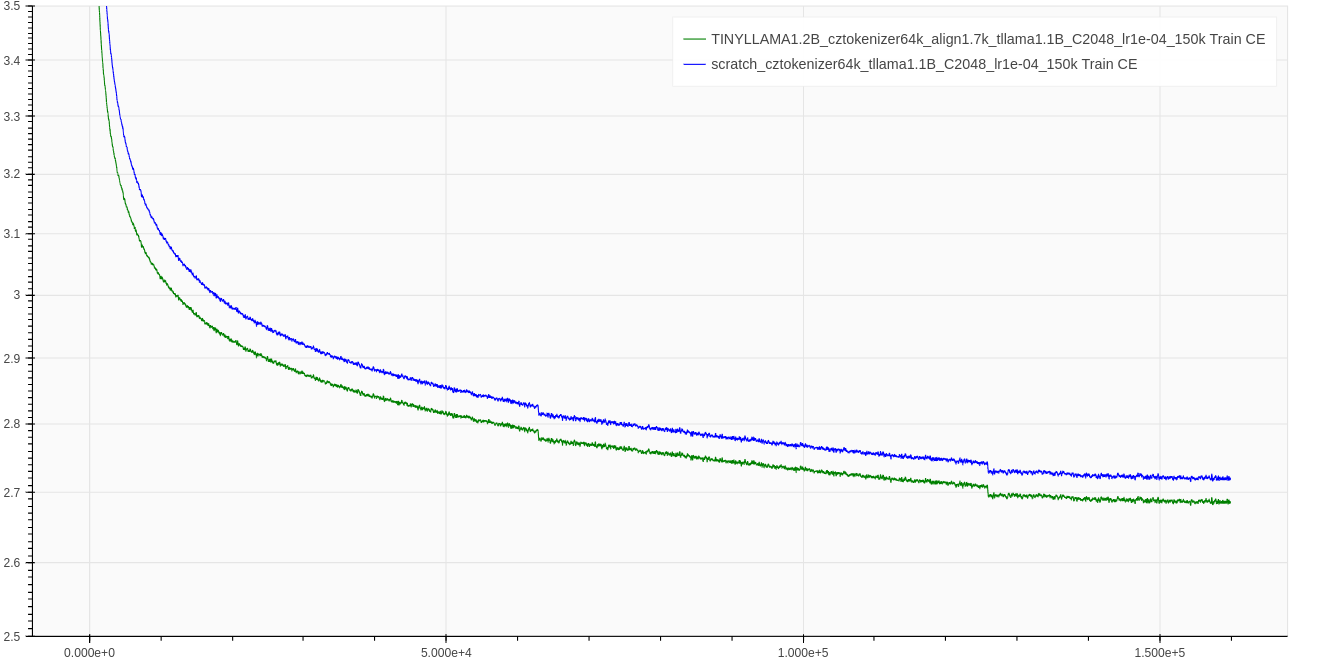
# Loss
Below we
- (i) demonstrate the convergence speed of released model (`TINYLLAMA1.2B_cztokenizer64k_align1.7k_tllama1.1B_C2048_lr1e-04_150k`, at 160k step).
- (ii) justify the contributions of our vocabulary swap method by comparing the swapped model with model trained from scratch (using same hyperparameters) `scratch_cztokenizer64k_tllama1.1B_C2048_lr1e-04_150k`. We swap 1.7K tokens in this run, similarly as for our other models (see [Czech-GPT-2-XL-133k](https://huggingface.co./BUT-FIT/Czech-GPT-2-XL-133k))
## Train Cross-Entropy
 ## Test Perplexity
## Test Perplexity
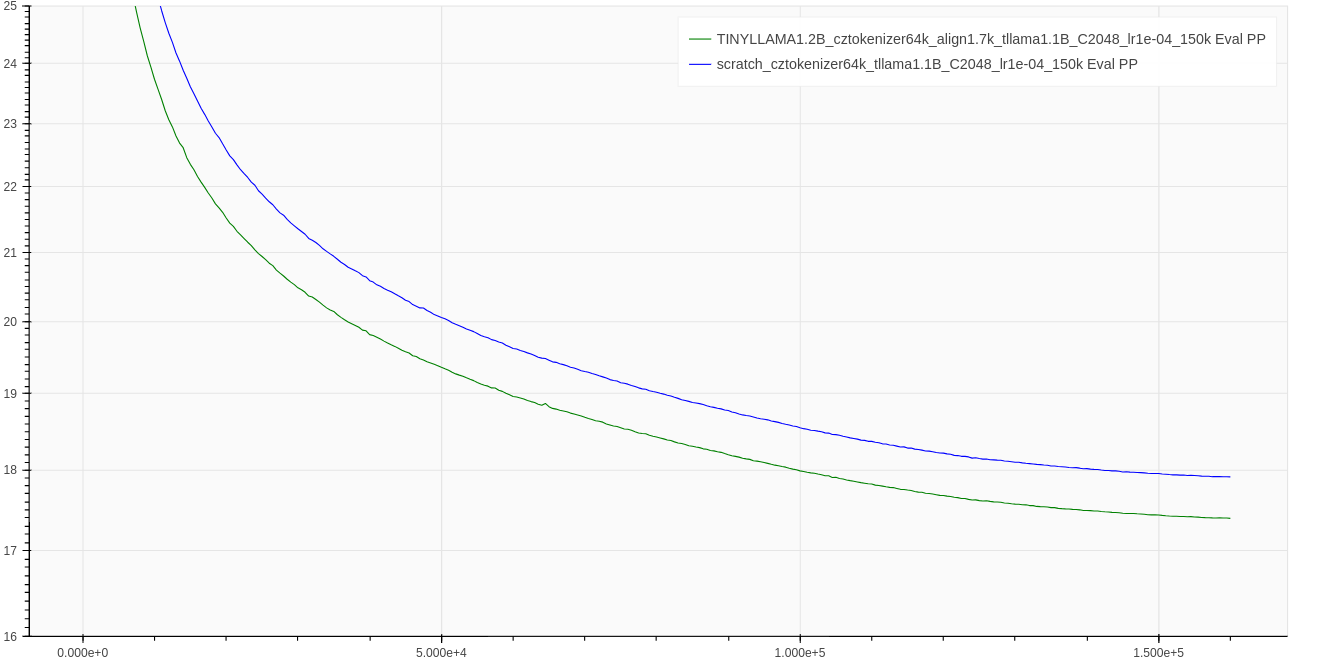 ## Training parameters
Not mentioned parameters are the same as for [TinyLLama-2.5T](https://huggingface.co./TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T).
| **Name** | **Value** | **Note** |
|----------------------------|---------------|----------------------------------------------------------------------------------------------|
| dataset_type | Concat | Sequences at the model's input were concatenated up to `$max_seq_len`, divided by EOS token. |
| tokenizer_size | 64k | |
| max_seq_len | 2048 | |
| batch_size | 512 | |
| learning_rate | 1.0e-4 | |
| optimizer | LionW | |
| optimizer_betas | 0.9/0.95 | |
| optimizer_weight_decay | 0 | |
| gradient_clipping_max_norm | 1.0 | |
| attn_impl | flash2 | |
| fsdp | SHARD_GRAD_OP | (optimized for A100 40GB GPUs) |
| precision | bf16 | |
| scheduler | cosine | |
| scheduler_warmup | 100 steps | |
| scheduler_steps | 200,000 | |
| scheduler_alpha | 0.1 | So LR on last step is 0.1*(vanilla LR) |
## Usage
```python
import torch
import transformers
from transformers import pipeline
name = 'BUT-FIT/CSTinyLlama-1.2B'
config = transformers.AutoConfig.from_pretrained(name, trust_remote_code=True)
model = transformers.AutoModelForCausalLM.from_pretrained(
name,
config=config,
trust_remote_code=True
)
tokenizer = transformers.AutoTokenizer.from_pretrained(name, trust_remote_code=True)
pipe = pipeline('text-generation', model=model, tokenizer=tokenizer, device='cuda:0')
with torch.autocast('cuda', dtype=torch.bfloat16):
print(
pipe('Nejznámějším českým spisovatelem ',
max_new_tokens=100,
top_p=0.95,
repetition_penalty=1.0,
do_sample=True,
use_cache=True))
```
# Training Data
We release most (95.79%) of our training data corpus as [BUT-Large Czech Collection](https://huggingface.co./datasets/BUT-FIT/but_lcc).
## Getting in Touch
For further questions, email to `martin.fajcik@vut.cz`.
# Disclaimer
This is a probabilistic model, it can output stochastic information. Authors are not responsible for the model outputs. Use at your own risk.
# Acknowledgement
This work was supported by NAKI III program of Ministry of Culture Czech Republic, project semANT ---
"Sémantický průzkumník textového kulturního dědictví" grant no. `DH23P03OVV060` and
by the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:`90254`).
# Citation
```bibtex
@article{benczechmark,
author = {Martin Fajčík, Martin Dočekal, Jan Doležal, Karel Beneš, Michal Hradiš},
title = {BenCzechMark: Machine Language Understanding Benchmark for Czech Language},
journal = {arXiv preprint arXiv:insert-arxiv-number-here},
year = {2024},
month = {March},
eprint = {insert-arxiv-number-here},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
}
## Training parameters
Not mentioned parameters are the same as for [TinyLLama-2.5T](https://huggingface.co./TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T).
| **Name** | **Value** | **Note** |
|----------------------------|---------------|----------------------------------------------------------------------------------------------|
| dataset_type | Concat | Sequences at the model's input were concatenated up to `$max_seq_len`, divided by EOS token. |
| tokenizer_size | 64k | |
| max_seq_len | 2048 | |
| batch_size | 512 | |
| learning_rate | 1.0e-4 | |
| optimizer | LionW | |
| optimizer_betas | 0.9/0.95 | |
| optimizer_weight_decay | 0 | |
| gradient_clipping_max_norm | 1.0 | |
| attn_impl | flash2 | |
| fsdp | SHARD_GRAD_OP | (optimized for A100 40GB GPUs) |
| precision | bf16 | |
| scheduler | cosine | |
| scheduler_warmup | 100 steps | |
| scheduler_steps | 200,000 | |
| scheduler_alpha | 0.1 | So LR on last step is 0.1*(vanilla LR) |
## Usage
```python
import torch
import transformers
from transformers import pipeline
name = 'BUT-FIT/CSTinyLlama-1.2B'
config = transformers.AutoConfig.from_pretrained(name, trust_remote_code=True)
model = transformers.AutoModelForCausalLM.from_pretrained(
name,
config=config,
trust_remote_code=True
)
tokenizer = transformers.AutoTokenizer.from_pretrained(name, trust_remote_code=True)
pipe = pipeline('text-generation', model=model, tokenizer=tokenizer, device='cuda:0')
with torch.autocast('cuda', dtype=torch.bfloat16):
print(
pipe('Nejznámějším českým spisovatelem ',
max_new_tokens=100,
top_p=0.95,
repetition_penalty=1.0,
do_sample=True,
use_cache=True))
```
# Training Data
We release most (95.79%) of our training data corpus as [BUT-Large Czech Collection](https://huggingface.co./datasets/BUT-FIT/but_lcc).
## Getting in Touch
For further questions, email to `martin.fajcik@vut.cz`.
# Disclaimer
This is a probabilistic model, it can output stochastic information. Authors are not responsible for the model outputs. Use at your own risk.
# Acknowledgement
This work was supported by NAKI III program of Ministry of Culture Czech Republic, project semANT ---
"Sémantický průzkumník textového kulturního dědictví" grant no. `DH23P03OVV060` and
by the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:`90254`).
# Citation
```bibtex
@article{benczechmark,
author = {Martin Fajčík, Martin Dočekal, Jan Doležal, Karel Beneš, Michal Hradiš},
title = {BenCzechMark: Machine Language Understanding Benchmark for Czech Language},
journal = {arXiv preprint arXiv:insert-arxiv-number-here},
year = {2024},
month = {March},
eprint = {insert-arxiv-number-here},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
}